

Solving the many-variables problem in MICE with principal component regression
- PMID: 37540467
- PMCID: PMC10991073
- DOI: 10.3758/s13428-023-02117-1
Solving the many-variables problem in MICE with principal component regression
Abstract
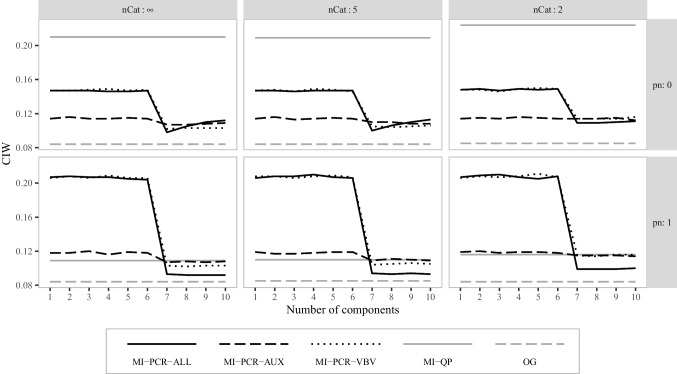
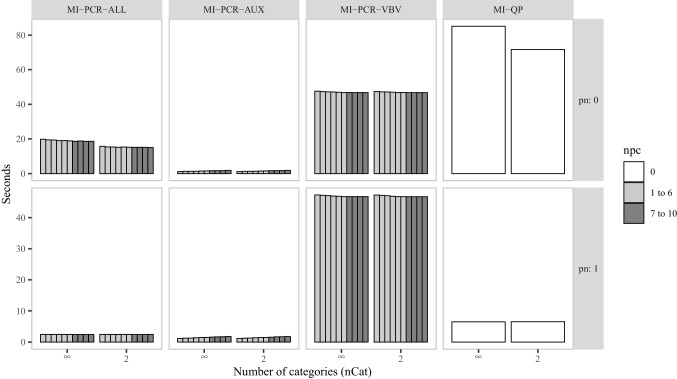
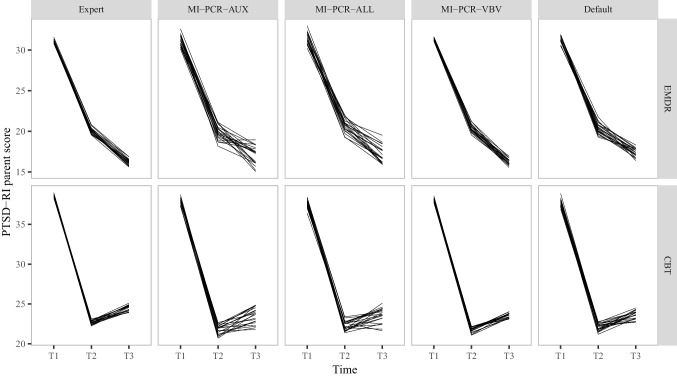
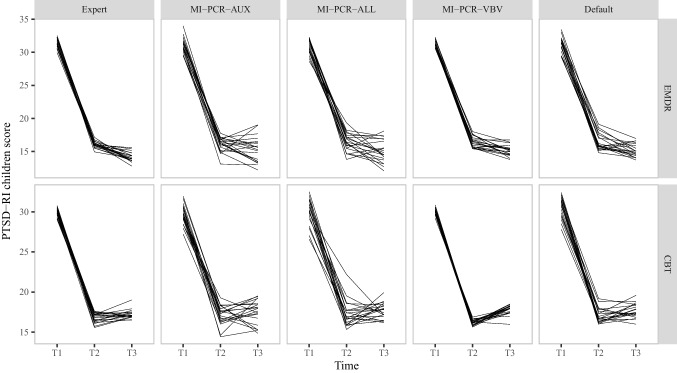
Multiple Imputation (MI) is one of the most popular approaches to addressing missing values in questionnaires and surveys. MI with multivariate imputation by chained equations (MICE) allows flexible imputation of many types of data. In MICE, for each variable under imputation, the imputer needs to specify which variables should act as predictors in the imputation model. The selection of these predictors is a difficult, but fundamental, step in the MI procedure, especially when there are many variables in a data set. In this project, we explore the use of principal component regression (PCR) as a univariate imputation method in the MICE algorithm to automatically address the many-variables problem that arises when imputing large social science data. We compare different implementations of PCR-based MICE with a correlation-thresholding strategy through two Monte Carlo simulation studies and a case study. We find the use of PCR on a variable-by-variable basis to perform best and that it can perform closely to expertly designed imputation procedures.
Keywords: High-dimensional data; Missing data; Multiple imputation; Principal component regression.
© 2023. The Author(s).
Figures
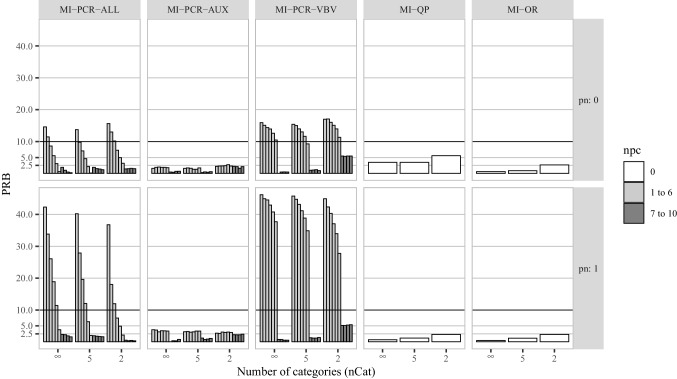
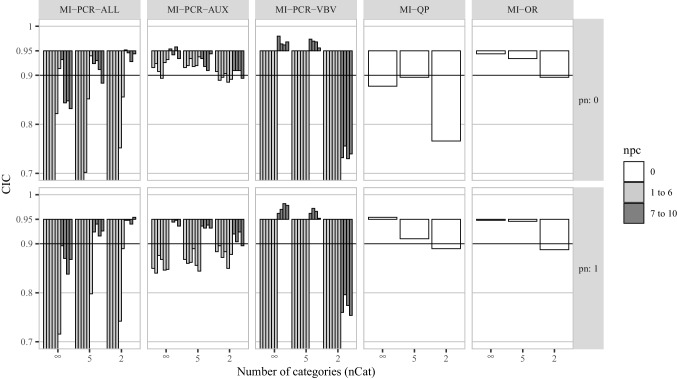
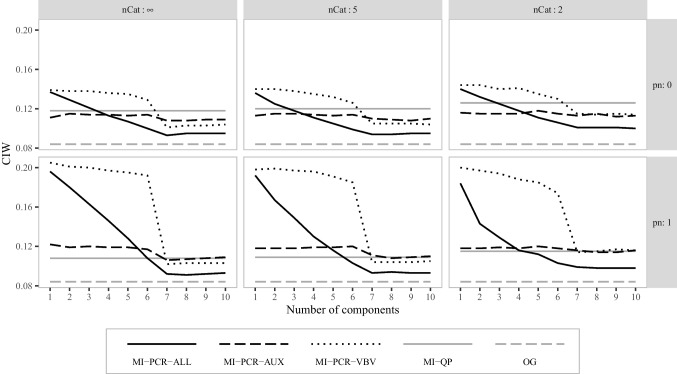
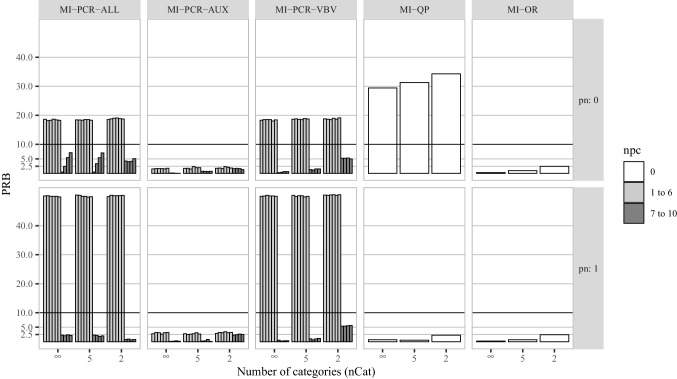

References
-
- Bair, E., Hastie, T., Paul, D., & Tibshirani, R. (2006). Prediction by supervised principal components. Journal of the American Statistical Association,101(473), 119–137.
-
- Bollen, K. A. (1989). Structural equations with latent variables (Vol. 210). John Wiley & Sons
-
- Burgette, L. F., & Reiter, J. P. (2010). Multiple imputation for missing data via sequential regression trees. American Journal of Epidemiology,172(9), 1070–1076. 10.1093/aje/kwq260. - PubMed
-
- Chavent M, Kuentz-Simonet V, Saracco J. Orthogonal rotation in pcamix. Advances in Data Analysis and Classification. 2012;6(2):131–146. doi: 10.1007/s11634-012-0105-3. - DOI
-
- Collins, L. M., Schafer, J. L., & Kam, C.-M. (2001). A comparison of inclusive and restrictive strategies in modern missing data procedures. Psychological Methods,6(4), 330–351. 10.1037//1082-989X.6.4.330. - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
