

This is a preprint.
CAVE: Connectome Annotation Versioning Engine
- PMID: 37546753
- PMCID: PMC10402030
- DOI: 10.1101/2023.07.26.550598
CAVE: Connectome Annotation Versioning Engine
Update in
-
CAVE: Connectome Annotation Versioning Engine.Nat Methods. 2025 May;22(5):1112-1120. doi: 10.1038/s41592-024-02426-z. Epub 2025 Apr 9. Nat Methods. 2025. PMID: 40205066 Free PMC article.
Abstract
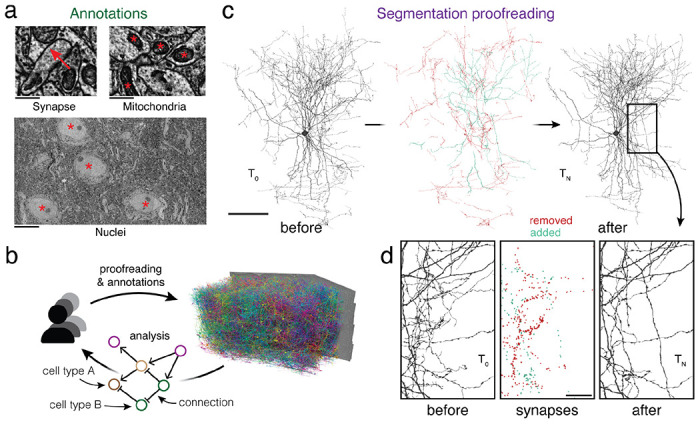
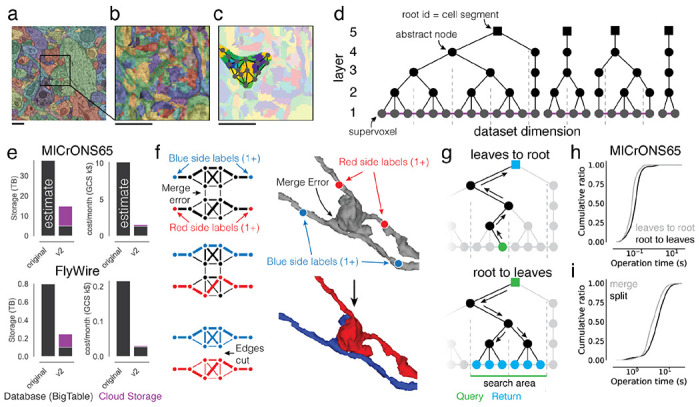
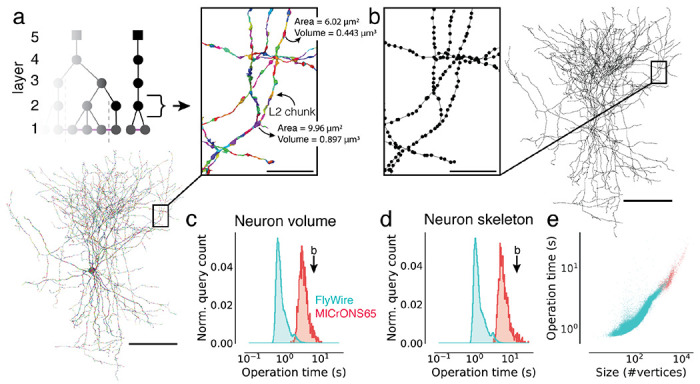
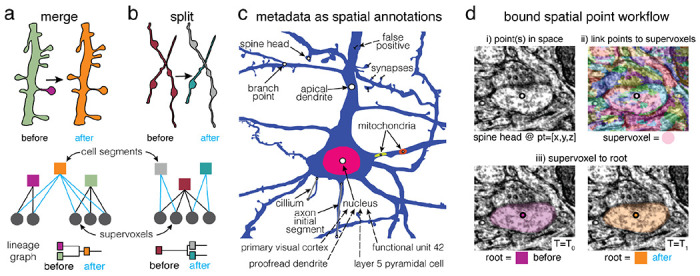
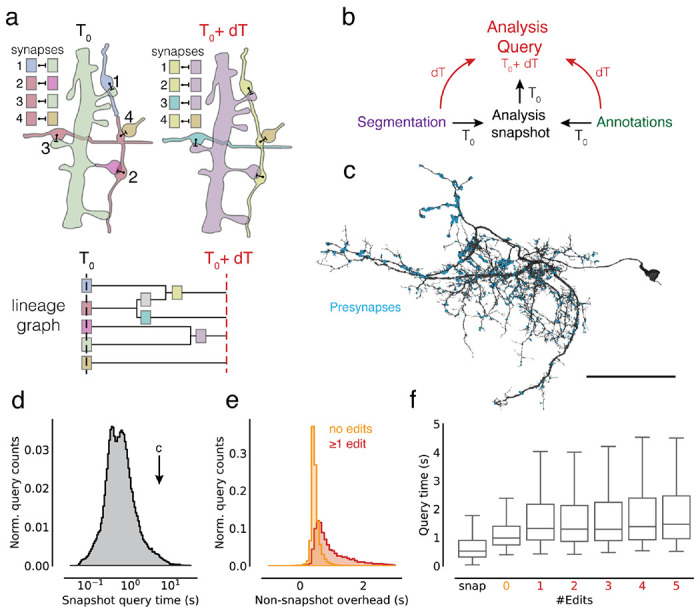
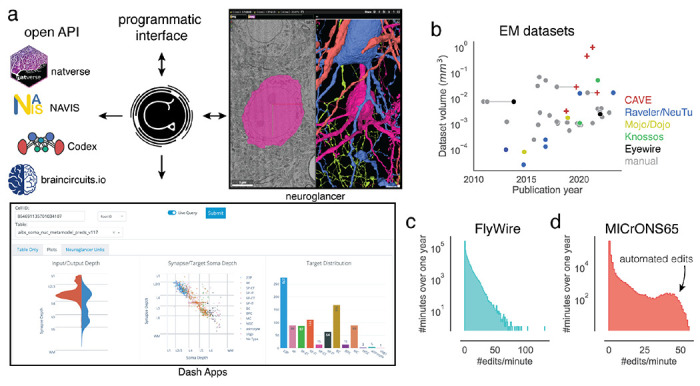
Advances in Electron Microscopy, image segmentation and computational infrastructure have given rise to large-scale and richly annotated connectomic datasets which are increasingly shared across communities. To enable collaboration, users need to be able to concurrently create new annotations and correct errors in the automated segmentation by proofreading. In large datasets, every proofreading edit relabels cell identities of millions of voxels and thousands of annotations like synapses. For analysis, users require immediate and reproducible access to this constantly changing and expanding data landscape. Here, we present the Connectome Annotation Versioning Engine (CAVE), a computational infrastructure for immediate and reproducible connectome analysis in up-to petascale datasets (~1mm3) while proofreading and annotating is ongoing. For segmentation, CAVE provides a distributed proofreading infrastructure for continuous versioning of large reconstructions. Annotations in CAVE are defined by locations such that they can be quickly assigned to the underlying segment which enables fast analysis queries of CAVE's data for arbitrary time points. CAVE supports schematized, extensible annotations, so that researchers can readily design novel annotation types. CAVE is already used for many connectomics datasets, including the largest datasets available to date.
Conflict of interest statement
Competing interests T. Macrina, K. Lee, S. Popovych, D. Ih, N. Kemnitz, and H. S. Seung declare financial interests in Zetta AI.
Figures
References
-
- Briggman K. L. & Bock D. D. Volume electron microscopy for neuronal circuit reconstruction. Curr. Opin. Neurobiol. 22, 154–161 (2012). - PubMed
-
- Lichtman J. W. & Denk W. The big and the small: challenges of imaging the brain’s circuits. Science 334, 618–623 (2011). - PubMed
-
- Dorkenwald S. et al. Automated synaptic connectivity inference for volume electron microscopy. Nat. Methods 14, 435–442 (2017). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources