

Federated Learning in Computational Toxicology: An Industrial Perspective on the Effiris Hackathon
- PMID: 37584277
- PMCID: PMC10523574
- DOI: 10.1021/acs.chemrestox.3c00137
Federated Learning in Computational Toxicology: An Industrial Perspective on the Effiris Hackathon
Abstract
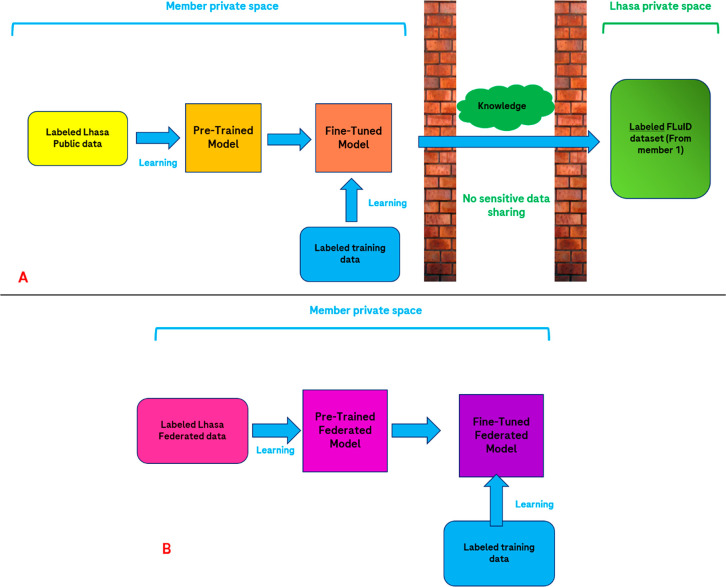
In silico approaches have acquired a towering role in pharmaceutical research and development, allowing laboratories all around the world to design, create, and optimize novel molecular entities with unprecedented efficiency. From a toxicological perspective, computational methods have guided the choices of medicinal chemists toward compounds displaying improved safety profiles. Even if the recent advances in the field are significant, many challenges remain active in the on-target and off-target prediction fields. Machine learning methods have shown their ability to identify molecules with safety concerns. However, they strongly depend on the abundance and diversity of data used for their training. Sharing such information among pharmaceutical companies remains extremely limited due to confidentiality reasons, but in this scenario, a recent concept named "federated learning" can help overcome such concerns. Within this framework, it is possible for companies to contribute to the training of common machine learning algorithms, using, but not sharing, their proprietary data. Very recently, Lhasa Limited organized a hackathon involving several industrial partners in order to assess the performance of their federated learning platform, called "Effiris". In this paper, we share our experience as Roche in participating in such an event, evaluating the performance of the federated algorithms and comparing them with those coming from our in-house-only machine learning models. Our aim is to highlight the advantages of federated learning and its intrinsic limitations and also suggest some points for potential improvements in the method.
Conflict of interest statement
The authors declare no competing financial interest.
Figures







References
-
- Samuel A. L. Some Studies in Machine Learning Using the Game of Checkers,. IBM J. Res. Dev. 1959, 3 (3), 210–229. 10.1147/rd.33.0210. - DOI
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
