

Evidence for a Spoken Word Lexicon in the Auditory Ventral Stream
- PMID: 37588129
- PMCID: PMC10426387
- DOI: 10.1162/nol_a_00108
Evidence for a Spoken Word Lexicon in the Auditory Ventral Stream
Abstract
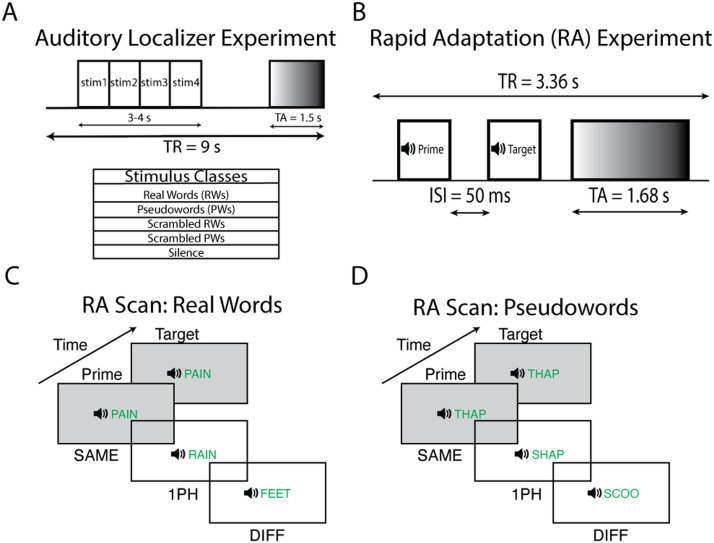
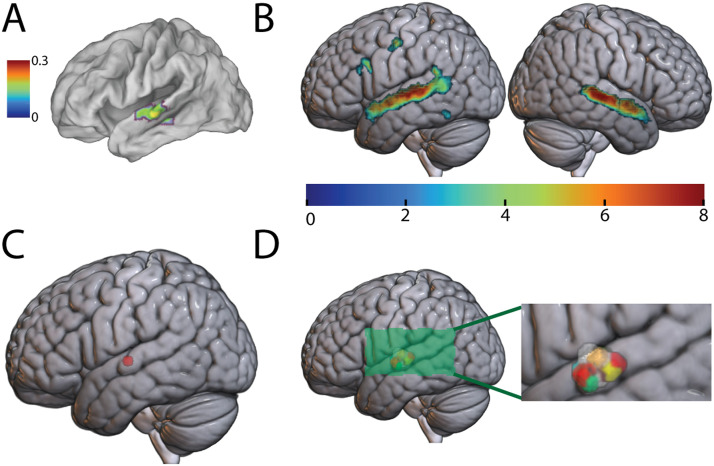
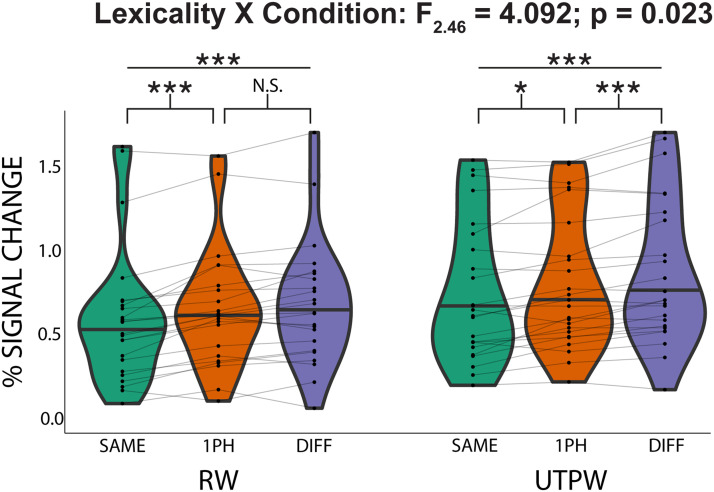
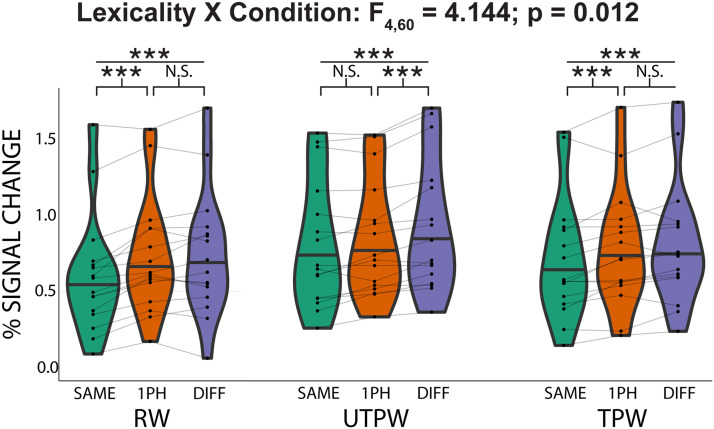
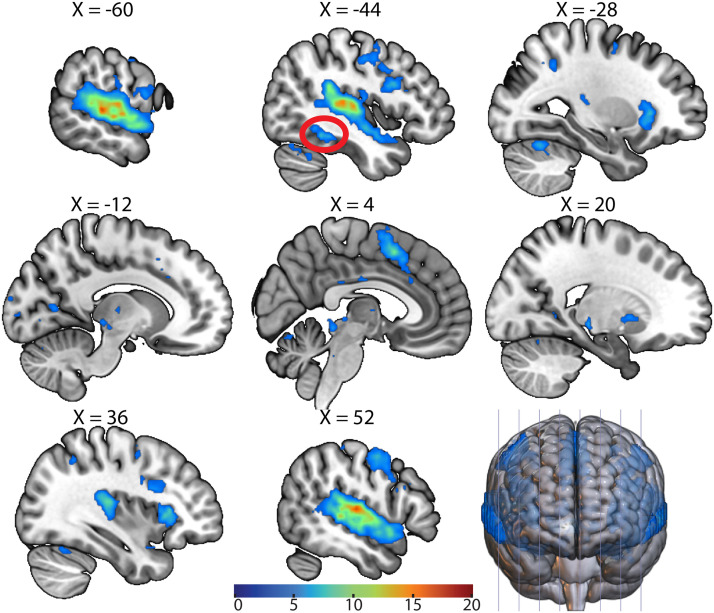
The existence of a neural representation for whole words (i.e., a lexicon) is a common feature of many models of speech processing. Prior studies have provided evidence for a visual lexicon containing representations of whole written words in an area of the ventral visual stream known as the visual word form area. Similar experimental support for an auditory lexicon containing representations of spoken words has yet to be shown. Using functional magnetic resonance imaging rapid adaptation techniques, we provide evidence for an auditory lexicon in the auditory word form area in the human left anterior superior temporal gyrus that contains representations highly selective for individual spoken words. Furthermore, we show that familiarization with novel auditory words sharpens the selectivity of their representations in the auditory word form area. These findings reveal strong parallels in how the brain represents written and spoken words, showing convergent processing strategies across modalities in the visual and auditory ventral streams.
Keywords: auditory lexicon; auditory ventral stream; speech recognition; superior temporal gyrus.
© 2023 Massachusetts Institute of Technology.
Figures
References
-
- Archakov, D., DeWitt, I., Kuśmierek, P., Ortiz-Rios, M., Cameron, D., Cui, D., Morin, E. L., VanMeter, J. W., Sams, M., Jääskeläinen, I. P., & Rauschecker, J. P. (2020). Auditory representation of learned sound sequences in motor regions of the macaque brain. Proceedings of the National Academy of Sciences, 117(26), 15242–15252. 10.1073/pnas.1915610117, - DOI - PMC - PubMed
-
- Ashburner, J., Barnes, G., Chen, C.-C., Daunizeau, J., Flandin, G., Friston, K., Gitelman, D., Glauche, V., Henson, R., Hutton, C., Jafarian, A., Kiebel, S., Kilner, J., Litvak, V., Mattout, J., Moran, R., Penny, W., Phillips, C., Razi, A., … Zeidman, P. (2021). SPM12 manual. Wellcome Centre for Human Neuroimaging.
Grants and funding
LinkOut - more resources
Full Text Sources