

Relating Acoustic Measures to Listener Ratings of Children's Productions of Word-Initial /ɹ/ and /w/
- PMID: 37591234
- PMCID: PMC10558147
- DOI: 10.1044/2023_JSLHR-22-00713
Relating Acoustic Measures to Listener Ratings of Children's Productions of Word-Initial /ɹ/ and /w/
Abstract
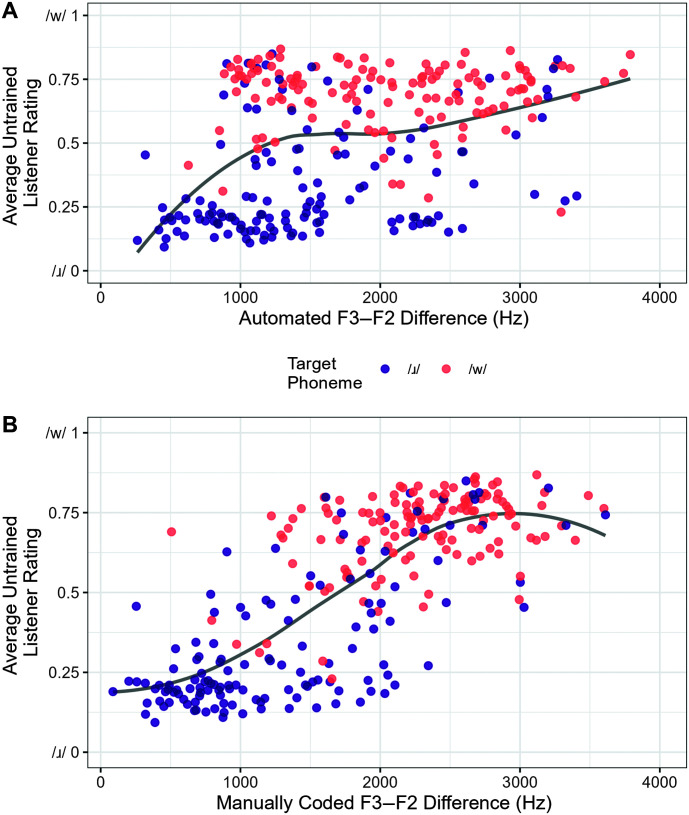
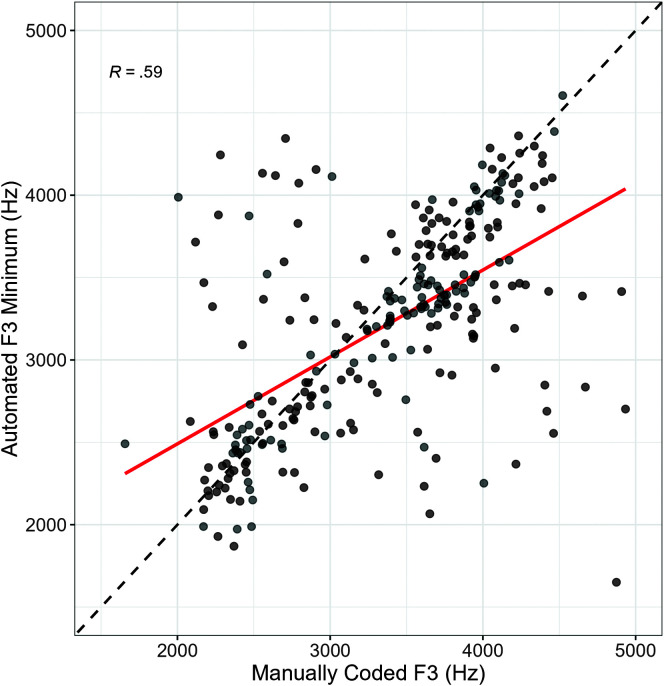
Purpose: The /ɹ/ productions of young children acquiring American English are highly variable and often inaccurate, with [w] as the most common substitution error. One acoustic indicator of the goodness of children's /ɹ/ productions is the difference between the frequency of the second formant (F2) and the third formant (F3), with a smaller F3-F2 difference being associated with a perceptually more adultlike /ɹ/. This study analyzed the effectiveness of automatically extracted F3-F2 differences in characterizing young children's productions of /ɹ/-/w/ in comparison with manually coded measurements.
Method: Automated F3-F2 differences were extracted from productions of a variety of different /ɹ/- and /w/-initial words spoken by 3- to 4-year-old monolingual preschoolers (N = 117; 2,278 tokens in total). These automated measures were compared to ratings of the phoneme goodness of children's productions as rated by untrained adult listeners (n = 132) on a visual analog scale, as well as to narrow transcriptions of the production into four categories: [ɹ], [w], and two intermediate categories.
Results: Data visualizations show a weak relationship between automated F3-F2 differences with listener ratings and narrow transcriptions. Mixed-effects models suggest the automated F3-F2 difference only modestly predicts listener ratings (R 2 = .37) and narrow transcriptions (R 2 = .32).
Conclusion: The weak relationship between automated F3-F2 difference and both listener ratings and narrow transcriptions suggests that these automated acoustic measures are of questionable reliability and utility in assessing preschool children's mastery of the /ɹ/-/w/ contrast.
Figures





References
-
- Barreda, S. (2021). Fast track: Fast (nearly) automatic formant-tracking using Praat. Linguistics Vanguard, 7(1), Article 20200051. 10.1515/lingvan-2020-0051 - DOI
-
- Campbell, H. , Harel, D. , Hitchcock, E. , & McAllister Byun, T. (2018). Selecting an acoustic correlate for automated measurement of American English rhotic production in children. International Journal of Speech-Language Pathology, 20(6), 635–643. 10.1080/17549507.2017.1359334 - DOI - PMC - PubMed
-
- Crowe Hall, B. J. (1991). Attitudes of fourth and sixth graders toward peers with mild articulation disorders. Language, Speech, and Hearing Services in Schools, 22(1), 334–340. 10.1044/0161-1461.2201.334 - DOI
-
- Cychosz, M. , Edwards, J. R. , Bernstein Ratner, N. , Torrington Eaton, C. , & Newman, R. S. (2021). Acoustic–lexical characteristics of child-directed speech between 7 and 24 months and their impact on toddlers' phonological processing. Frontiers in Psychology, 12, Article 3186. 10.3389/fpsyg.2021.712647 - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
