

Modeling islet enhancers using deep learning identifies candidate causal variants at loci associated with T2D and glycemic traits
- PMID: 37603758
- PMCID: PMC10469333
- DOI: 10.1073/pnas.2206612120
Modeling islet enhancers using deep learning identifies candidate causal variants at loci associated with T2D and glycemic traits
Abstract
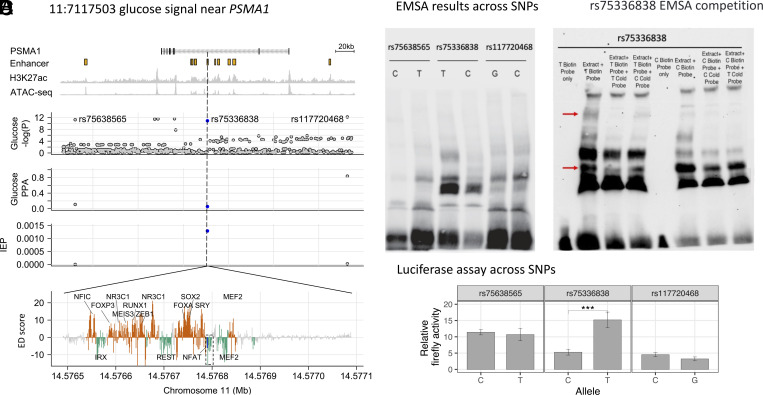
Genetic association studies have identified hundreds of independent signals associated with type 2 diabetes (T2D) and related traits. Despite these successes, the identification of specific causal variants underlying a genetic association signal remains challenging. In this study, we describe a deep learning (DL) method to analyze the impact of sequence variants on enhancers. Focusing on pancreatic islets, a T2D relevant tissue, we show that our model learns islet-specific transcription factor (TF) regulatory patterns and can be used to prioritize candidate causal variants. At 101 genetic signals associated with T2D and related glycemic traits where multiple variants occur in linkage disequilibrium, our method nominates a single causal variant for each association signal, including three variants previously shown to alter reporter activity in islet-relevant cell types. For another signal associated with blood glucose levels, we biochemically test all candidate causal variants from statistical fine-mapping using a pancreatic islet beta cell line and show biochemical evidence of allelic effects on TF binding for the model-prioritized variant. To aid in future research, we publicly distribute our model and islet enhancer perturbation scores across ~67 million genetic variants. We anticipate that DL methods like the one presented in this study will enhance the prioritization of candidate causal variants for functional studies.
Keywords: deep learning; enhancer; epigenomics; pancreatic islets; type 2 diabetes.
Conflict of interest statement
S.C. is the co-founders of OncoBeat, LLC. and a consultant of Vesalius Therapeutics. The other authors declare no competing interest.
Figures
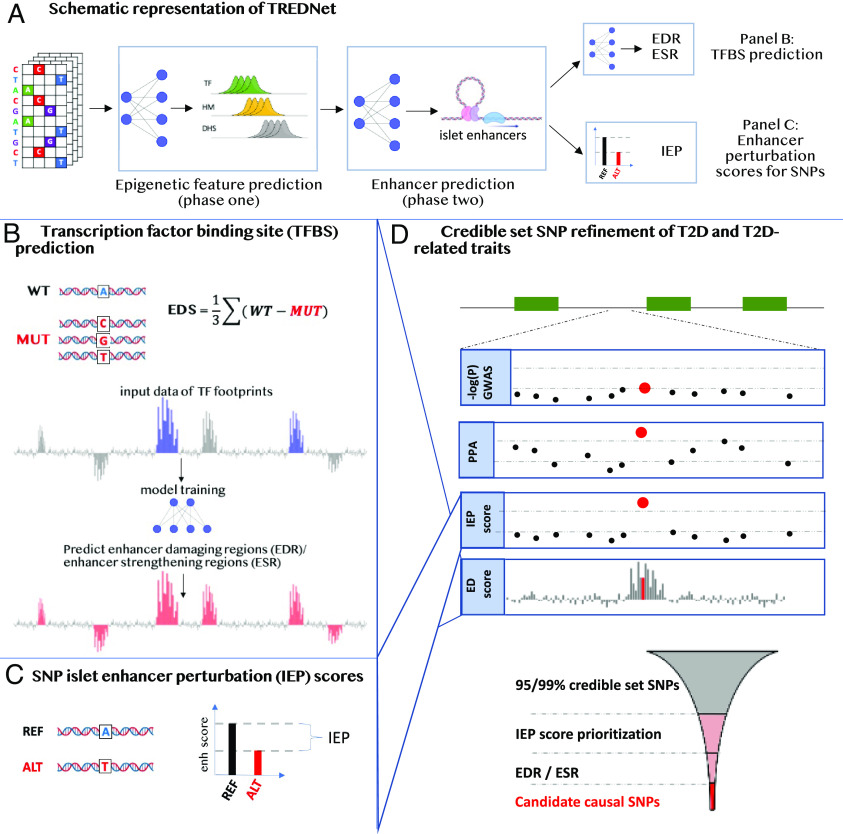
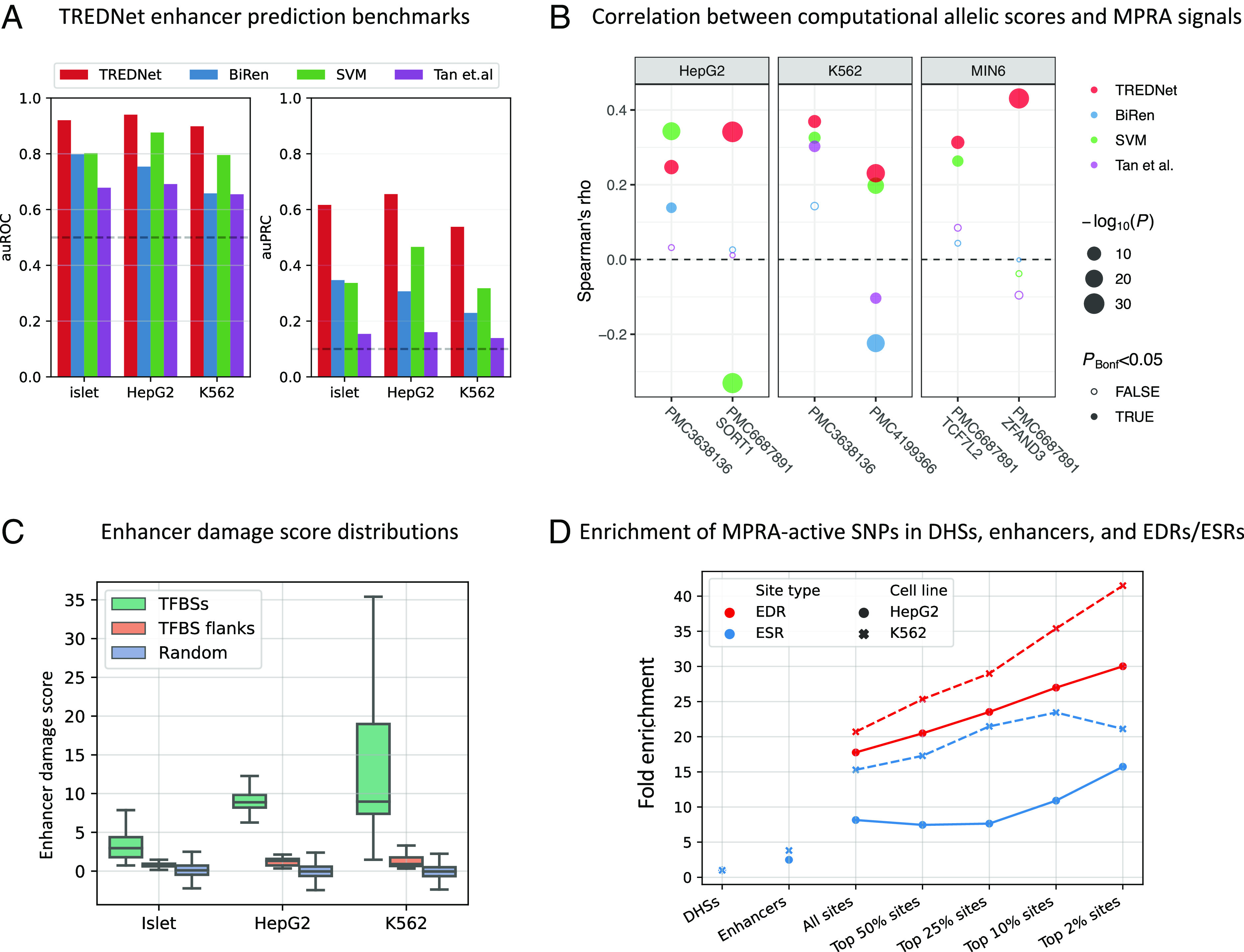
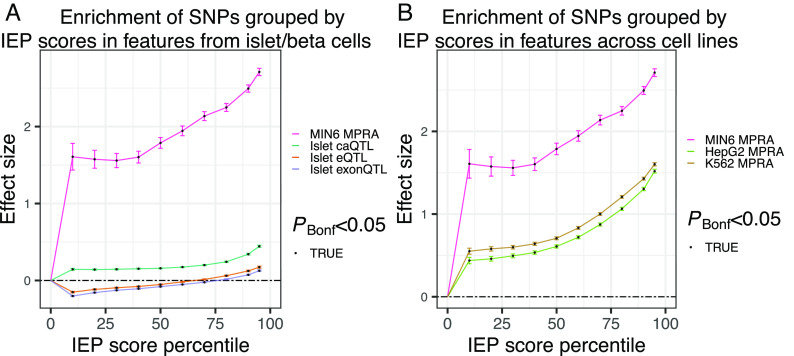
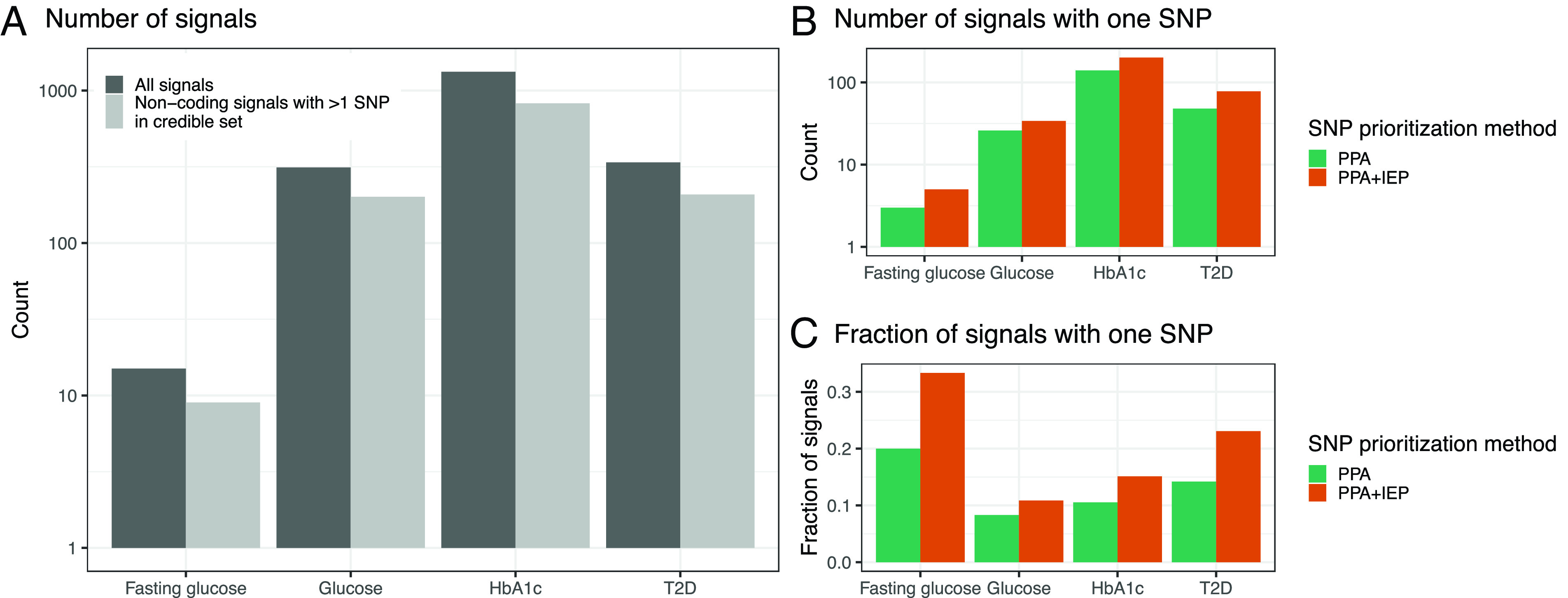
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
