

Assessing the Utility of ChatGPT Throughout the Entire Clinical Workflow: Development and Usability Study
- PMID: 37606976
- PMCID: PMC10481210
- DOI: 10.2196/48659
Assessing the Utility of ChatGPT Throughout the Entire Clinical Workflow: Development and Usability Study
Abstract
Background: Large language model (LLM)-based artificial intelligence chatbots direct the power of large training data sets toward successive, related tasks as opposed to single-ask tasks, for which artificial intelligence already achieves impressive performance. The capacity of LLMs to assist in the full scope of iterative clinical reasoning via successive prompting, in effect acting as artificial physicians, has not yet been evaluated.
Objective: This study aimed to evaluate ChatGPT's capacity for ongoing clinical decision support via its performance on standardized clinical vignettes.
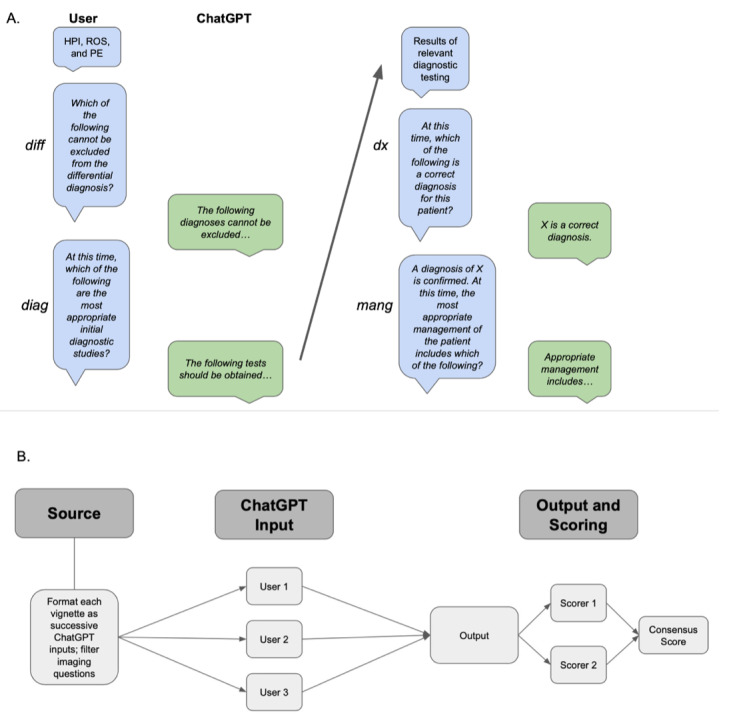
Methods: We inputted all 36 published clinical vignettes from the Merck Sharpe & Dohme (MSD) Clinical Manual into ChatGPT and compared its accuracy on differential diagnoses, diagnostic testing, final diagnosis, and management based on patient age, gender, and case acuity. Accuracy was measured by the proportion of correct responses to the questions posed within the clinical vignettes tested, as calculated by human scorers. We further conducted linear regression to assess the contributing factors toward ChatGPT's performance on clinical tasks.
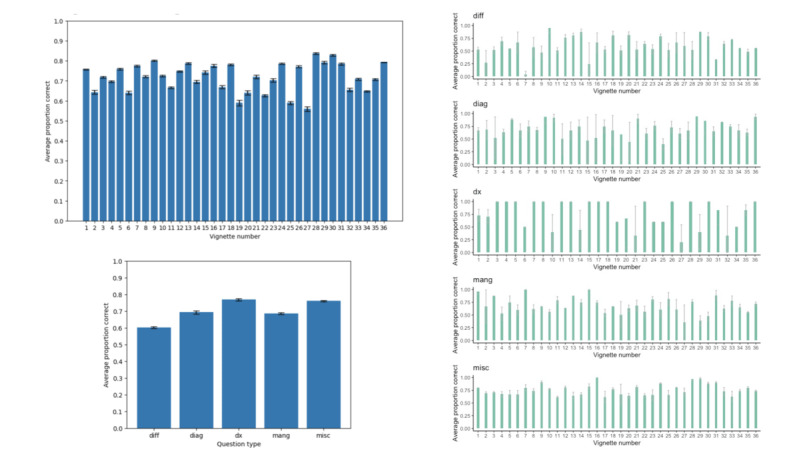
Results: ChatGPT achieved an overall accuracy of 71.7% (95% CI 69.3%-74.1%) across all 36 clinical vignettes. The LLM demonstrated the highest performance in making a final diagnosis with an accuracy of 76.9% (95% CI 67.8%-86.1%) and the lowest performance in generating an initial differential diagnosis with an accuracy of 60.3% (95% CI 54.2%-66.6%). Compared to answering questions about general medical knowledge, ChatGPT demonstrated inferior performance on differential diagnosis (β=-15.8%; P<.001) and clinical management (β=-7.4%; P=.02) question types.
Conclusions: ChatGPT achieves impressive accuracy in clinical decision-making, with increasing strength as it gains more clinical information at its disposal. In particular, ChatGPT demonstrates the greatest accuracy in tasks of final diagnosis as compared to initial diagnosis. Limitations include possible model hallucinations and the unclear composition of ChatGPT's training data set.
Keywords: AI; ChatGPT; GPT; Generative Pre-trained Transformer; LLMs; accuracy; artificial intelligence; chatbot; clinical decision support; clinical vignettes; decision-making; development; large language models; usability; utility.
©Arya Rao, Michael Pang, John Kim, Meghana Kamineni, Winston Lie, Anoop K Prasad, Adam Landman, Keith Dreyer, Marc D Succi. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 22.08.2023.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
Update of
-
Assessing the Utility of ChatGPT Throughout the Entire Clinical Workflow.medRxiv [Preprint]. 2023 Feb 26:2023.02.21.23285886. doi: 10.1101/2023.02.21.23285886. medRxiv. 2023. Update in: J Med Internet Res. 2023 Aug 22;25:e48659. doi: 10.2196/48659. PMID: 36865204 Free PMC article. Updated. Preprint.
References
-
- Xu L, Sanders L, Li K, Chow JCL. Chatbot for health care and oncology applications using artificial intelligence and machine learning: systematic review. JMIR Cancer. 2021 Nov 29;7(4):e27850. doi: 10.2196/27850. https://cancer.jmir.org/2021/4/e27850/ v7i4e27850 - DOI - PMC - PubMed
-
- Chonde DB, Pourvaziri A, Williams J, McGowan J, Moskos M, Alvarez C, Narayan AK, Daye D, Flores EJ, Succi MD. RadTranslate: an artificial intelligence-powered intervention for urgent imaging to enhance care equity for patients with limited English proficiency during the COVID-19 pandemic. J Am Coll Radiol. 2021 Jul;18(7):1000–1008. doi: 10.1016/j.jacr.2021.01.013. https://europepmc.org/abstract/MED/33609456 S1546-1440(21)00032-6 - DOI - PMC - PubMed
-
- Chung J, Kim D, Choi J, Yune S, Song K, Kim S, Chua M, Succi MD, Conklin J, Longo MGF, Ackman JB, Petranovic M, Lev MH, Do S. Prediction of oxygen requirement in patients with COVID-19 using a pre-trained chest radiograph xAI model: efficient development of auditable risk prediction models via a fine-tuning approach. Sci Rep. 2022 Dec 07;12(1):21164. doi: 10.1038/s41598-022-24721-5. doi: 10.1038/s41598-022-24721-5.10.1038/s41598-022-24721-5 - DOI - DOI - PMC - PubMed
-
- Li M, Arun N, Aggarwal M, Gupta Sharut, Singh Praveer, Little Brent P, Mendoza Dexter P, Corradi Gustavo C A, Takahashi Marcelo S, Ferraciolli Suely F, Succi Marc D, Lang Min, Bizzo Bernardo C, Dayan Ittai, Kitamura Felipe C, Kalpathy-Cramer Jayashree. Multi-population generalizability of a deep learning-based chest radiograph severity score for COVID-19. Medicine (Baltimore) 2022 Jul 22;101(29):e29587. doi: 10.1097/MD.0000000000029587. https://europepmc.org/abstract/MED/35866818 00005792-202207220-00064 - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
