

A high-performance speech neuroprosthesis
- PMID: 37612500
- PMCID: PMC10468393
- DOI: 10.1038/s41586-023-06377-x
A high-performance speech neuroprosthesis
Abstract
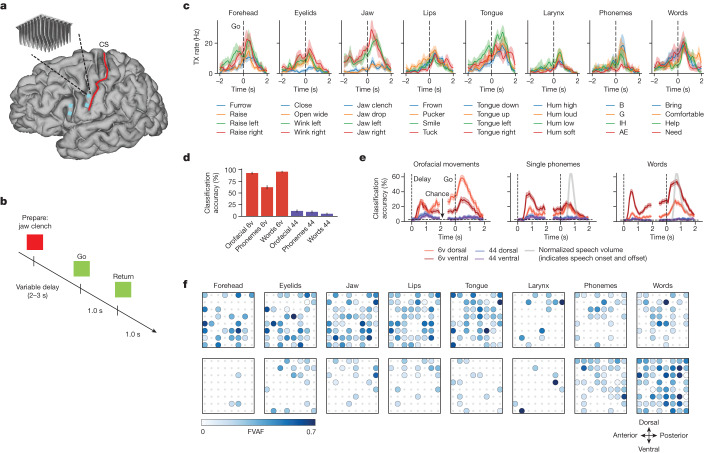
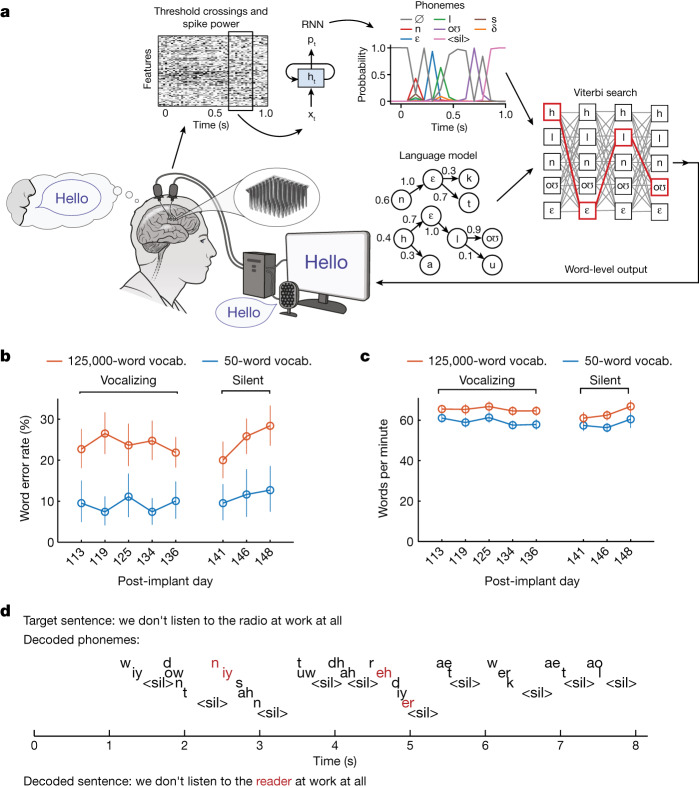
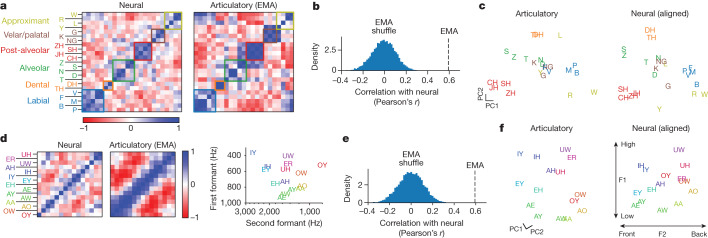
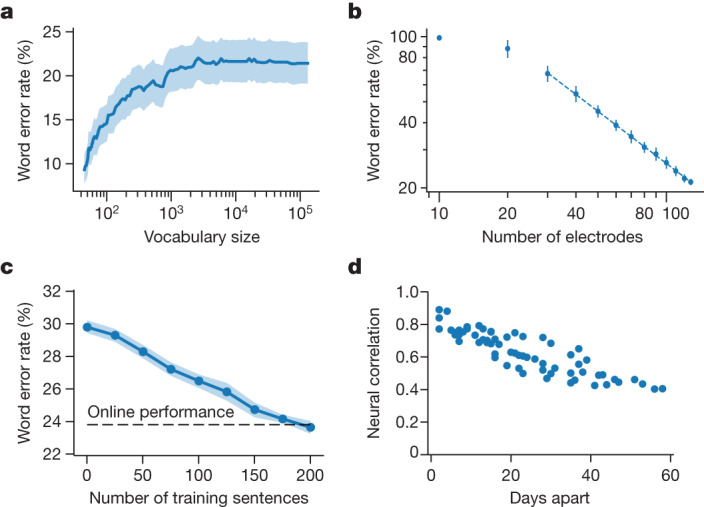
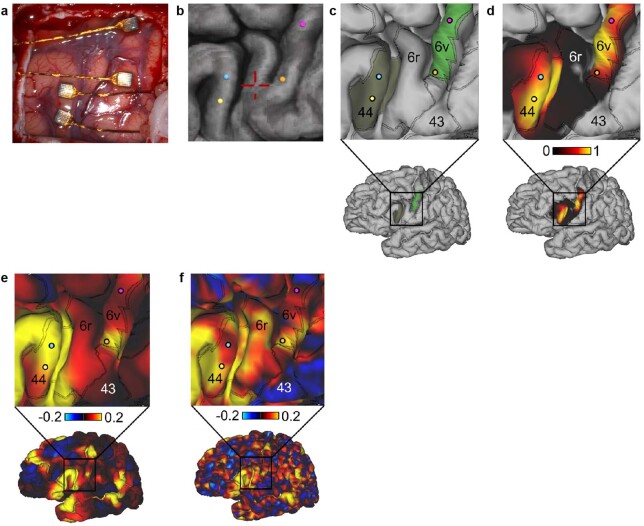
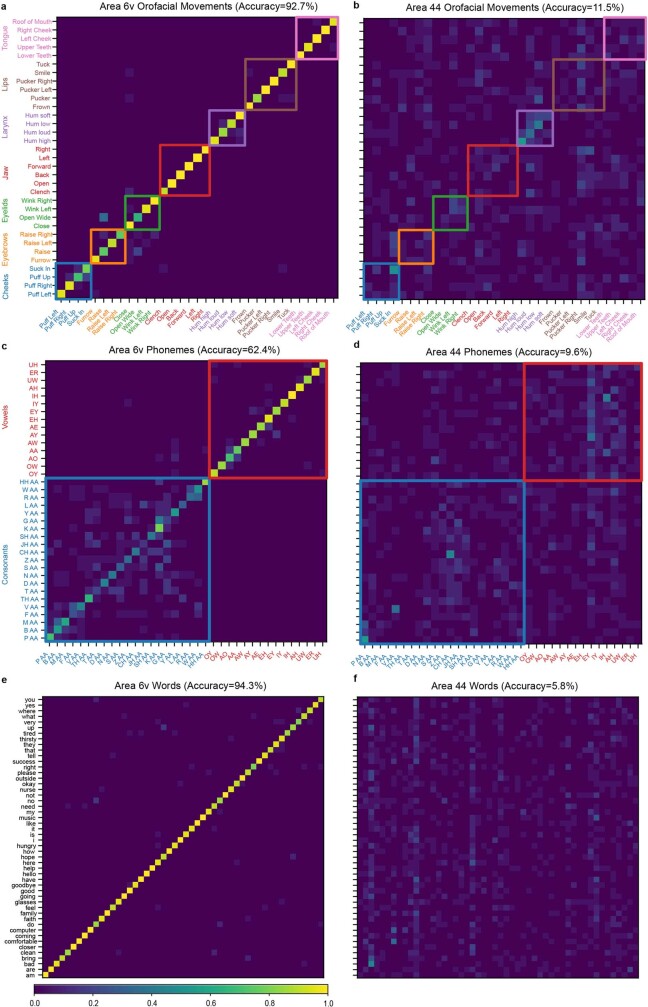
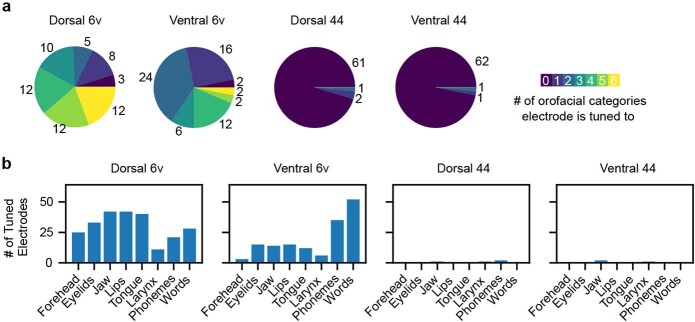
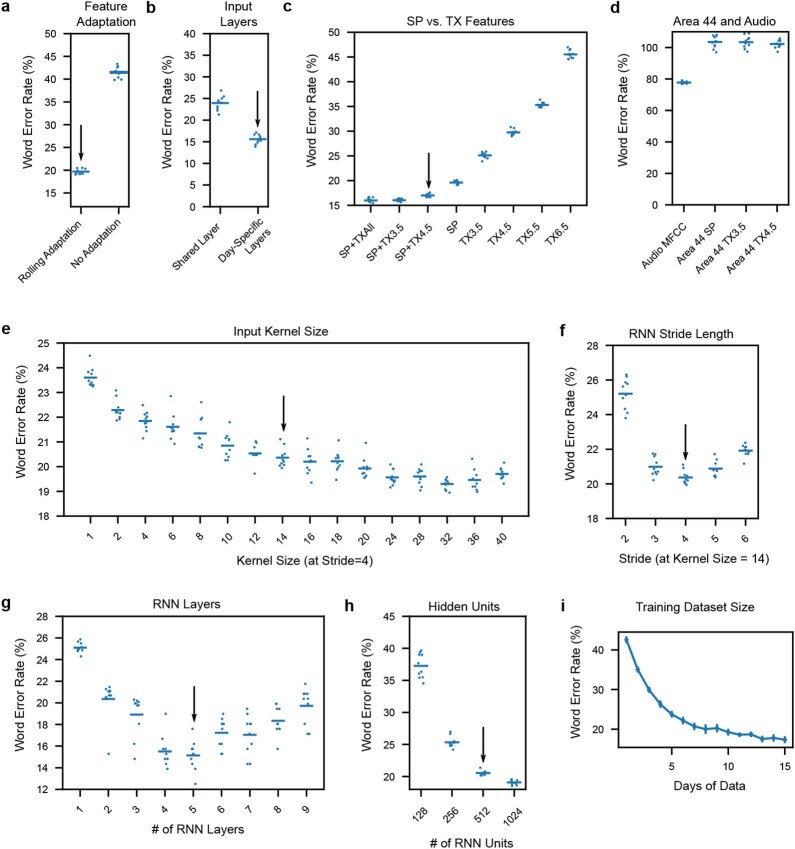
Speech brain-computer interfaces (BCIs) have the potential to restore rapid communication to people with paralysis by decoding neural activity evoked by attempted speech into text1,2 or sound3,4. Early demonstrations, although promising, have not yet achieved accuracies sufficiently high for communication of unconstrained sentences from a large vocabulary1-7. Here we demonstrate a speech-to-text BCI that records spiking activity from intracortical microelectrode arrays. Enabled by these high-resolution recordings, our study participant-who can no longer speak intelligibly owing to amyotrophic lateral sclerosis-achieved a 9.1% word error rate on a 50-word vocabulary (2.7 times fewer errors than the previous state-of-the-art speech BCI2) and a 23.8% word error rate on a 125,000-word vocabulary (the first successful demonstration, to our knowledge, of large-vocabulary decoding). Our participant's attempted speech was decoded at 62 words per minute, which is 3.4 times as fast as the previous record8 and begins to approach the speed of natural conversation (160 words per minute9). Finally, we highlight two aspects of the neural code for speech that are encouraging for speech BCIs: spatially intermixed tuning to speech articulators that makes accurate decoding possible from only a small region of cortex, and a detailed articulatory representation of phonemes that persists years after paralysis. These results show a feasible path forward for restoring rapid communication to people with paralysis who can no longer speak.
© 2023. The Author(s).
Conflict of interest statement
The MGH Translational Research Center has a clinical research support agreement with Neuralink, Axoft, Reach Neuro and Synchron, for which L.R.H. provides consultative input. J.M.H. is a consultant for Neuralink, serves on the Medical Advisory Board of Enspire DBS and is a shareholder in Maplight Therapeutics. K.V.S. consults for Neuralink and CTRL-Labs (part of Facebook Reality Labs) and is on the scientific advisory boards of MIND-X, Inscopix and Heal. The remaining authors declare no competing interests.
Figures

Update of
-
A high-performance speech neuroprosthesis.bioRxiv [Preprint]. 2023 Apr 25:2023.01.21.524489. doi: 10.1101/2023.01.21.524489. bioRxiv. 2023. Update in: Nature. 2023 Aug;620(7976):1031-1036. doi: 10.1038/s41586-023-06377-x. PMID: 36711591 Free PMC article. Updated. Preprint.
Comment in
-
Brain implants that enable speech pass performance milestones.Nature. 2023 Aug;620(7976):954-955. doi: 10.1038/d41586-023-02546-0. Nature. 2023. PMID: 37612488 No abstract available.
-
Restoring speech.Nat Rev Neurosci. 2023 Nov;24(11):653. doi: 10.1038/s41583-023-00746-1. Nat Rev Neurosci. 2023. PMID: 37740095 No abstract available.
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
