

Local Spatiotemporal Representation Learning for Longitudinally-consistent Neuroimage Analysis
- PMID: 37614415
- PMCID: PMC10445502
Local Spatiotemporal Representation Learning for Longitudinally-consistent Neuroimage Analysis
Abstract
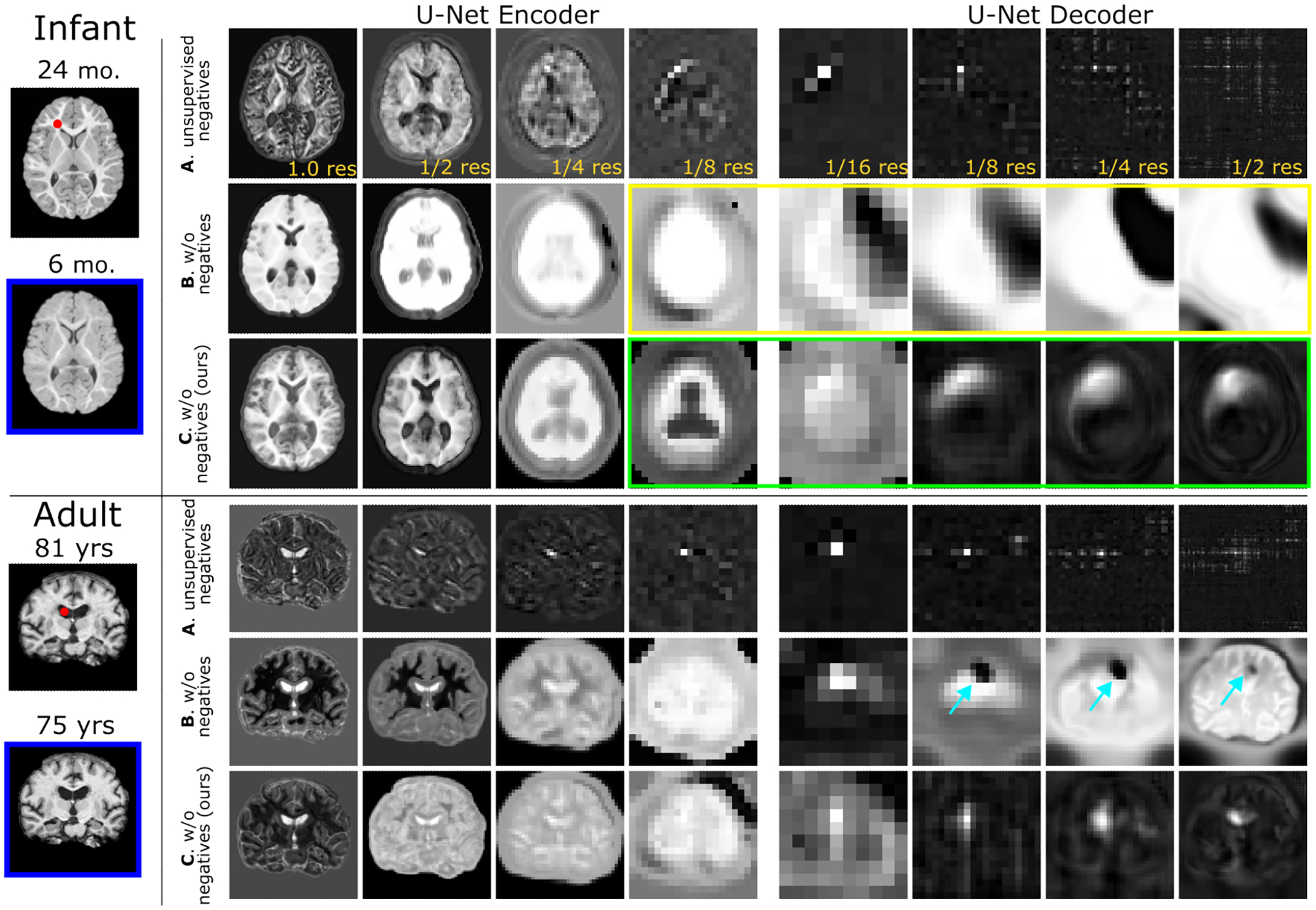
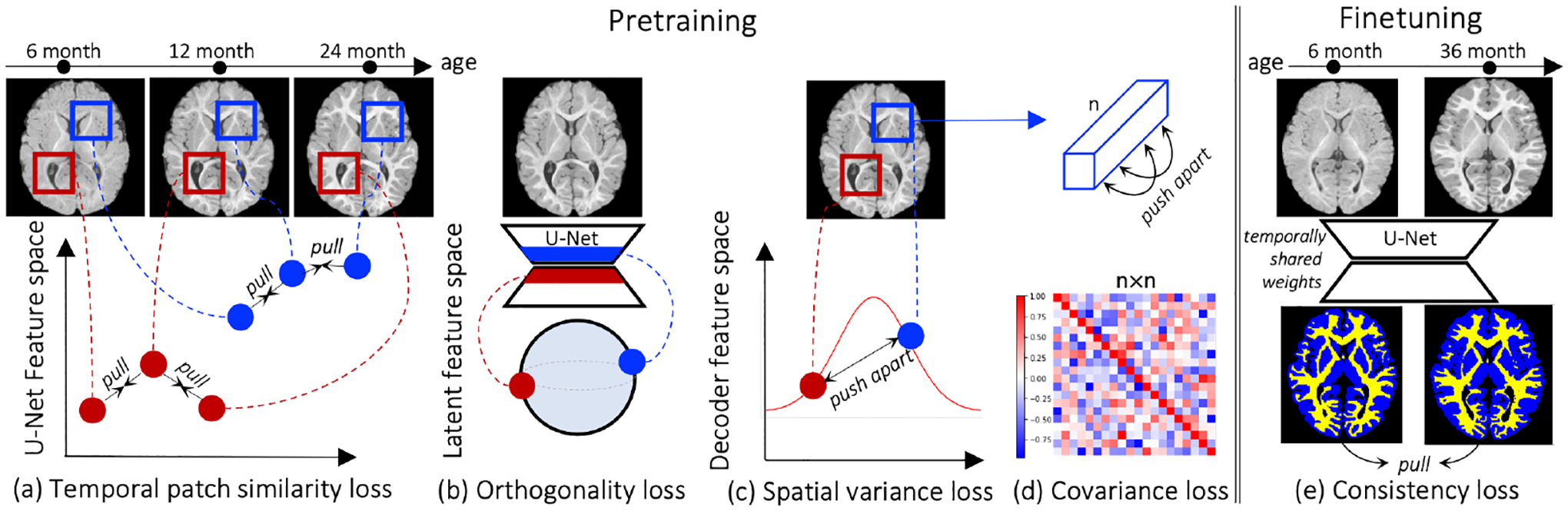
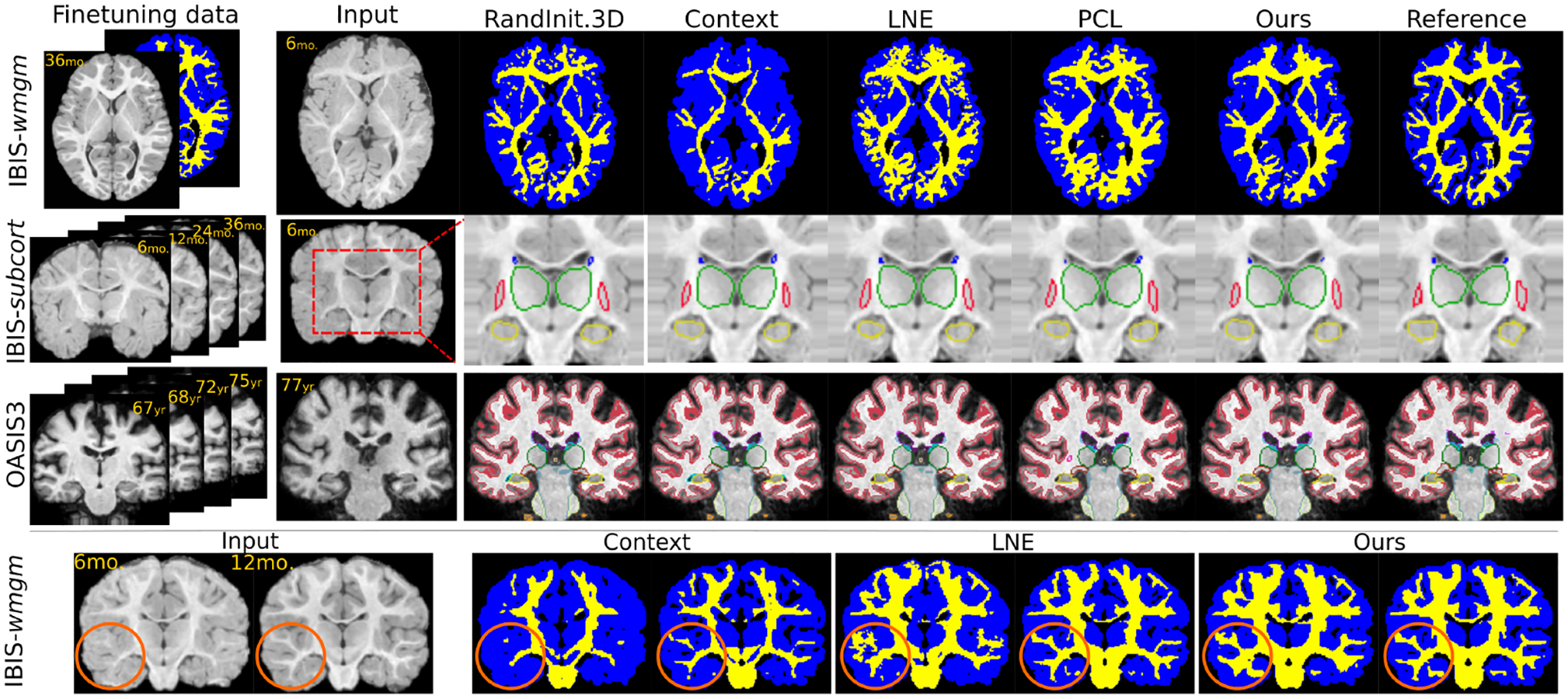
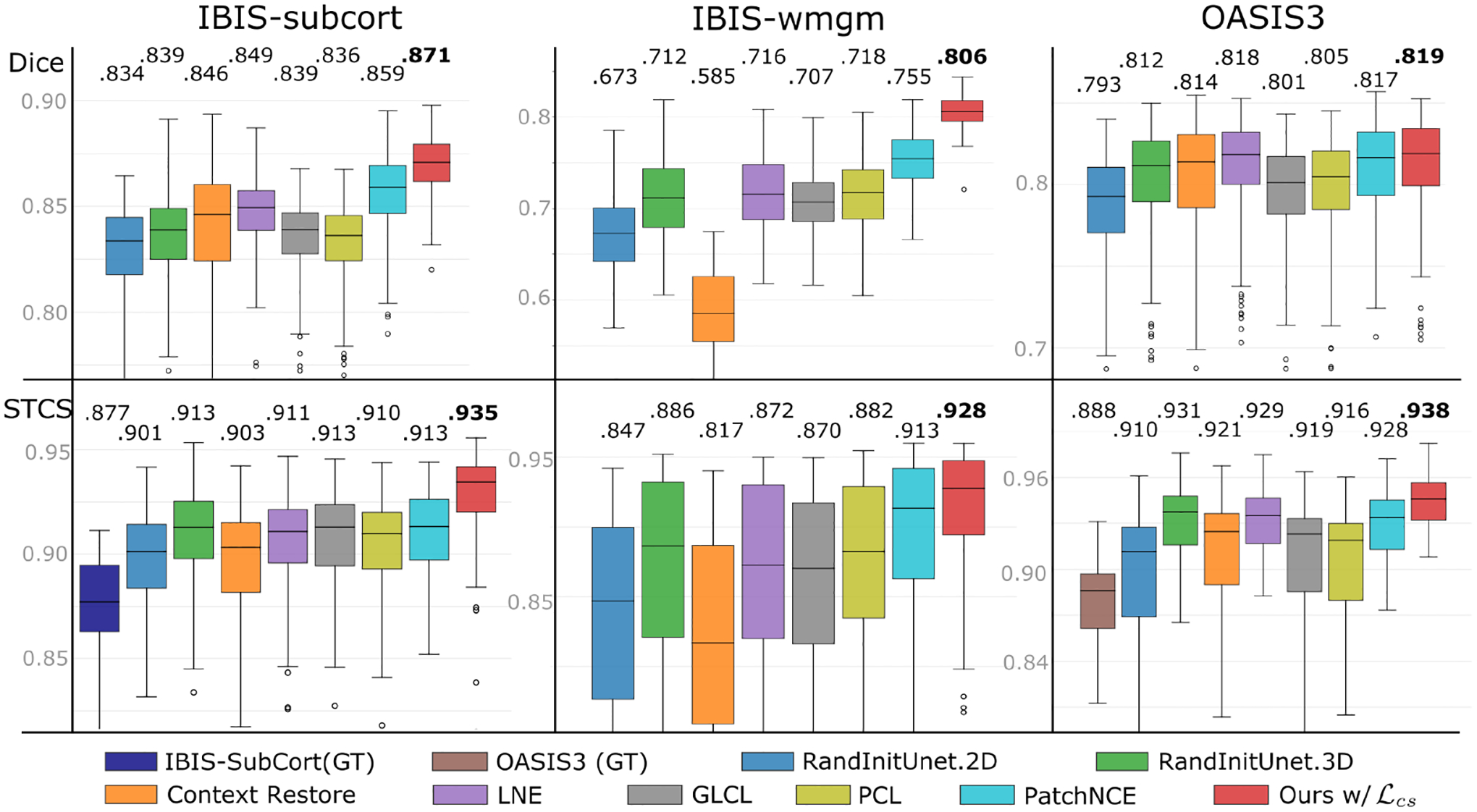
Recent self-supervised advances in medical computer vision exploit the global and local anatomical self-similarity for pretraining prior to downstream tasks such as segmentation. However, current methods assume i.i.d. image acquisition, which is invalid in clinical study designs where follow-up longitudinal scans track subject-specific temporal changes. Further, existing self-supervised methods for medically-relevant image-to-image architectures exploit only spatial or temporal self-similarity and do so via a loss applied only at a single image-scale, with naive multi-scale spatiotemporal extensions collapsing to degenerate solutions. To these ends, this paper makes two contributions: (1) It presents a local and multi-scale spatiotemporal representation learning method for image-to-image architectures trained on longitudinal images. It exploits the spatiotemporal self-similarity of learned multi-scale intra-subject image features for pretraining and develops several feature-wise regularizations that avoid degenerate representations; (2) During finetuning, it proposes a surprisingly simple self-supervised segmentation consistency regularization to exploit intra-subject correlation. Benchmarked across various segmentation tasks, the proposed framework outperforms both well-tuned randomly-initialized baselines and current self-supervised techniques designed for both i.i.d. and longitudinal datasets. These improvements are demonstrated across both longitudinal neurodegenerative adult MRI and developing infant brain MRI and yield both higher performance and longitudinal consistency.
Figures
References
-
- Aljabar Paul, Heckemann Rolf A, Hammers Alexander, Hajnal Joseph V, and Rueckert Daniel. Multi-atlas based segmentation of brain images: atlas selection and its effect on accuracy. Neuroimage, 46(3):726–738, 2009. - PubMed
-
- Alonso Iñigo, Sabater Alberto, Ferstl David, Montesano Luis, and Murillo Ana C.. Semisupervised semantic segmentation with pixel-level contrastive learning from a class-wise memory bank. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 8219–8228, October 2021.
-
- Bai Yutong, Fan Haoqi, Misra Ishan, Venkatesh Ganesh, Lu Yongyi, Zhou Yuyin, Yu Qihang, Chandra Vikas, and Yuille Alan. Can temporal information help with contrastive self-supervised learning? arXiv preprint arXiv:2011.13046, 2020.
Grants and funding
- R01 AG043434/AG/NIA NIH HHS/United States
- R01 ES032294/ES/NIEHS NIH HHS/United States
- P01 AG003991/AG/NIA NIH HHS/United States
- P01 AG026276/AG/NIA NIH HHS/United States
- R01 EB009352/EB/NIBIB NIH HHS/United States
- UL1 TR000448/TR/NCATS NIH HHS/United States
- R01 MH118362/MH/NIMH NIH HHS/United States
- R01 HD059854/HD/NICHD NIH HHS/United States
- UL1 TR002345/TR/NCATS NIH HHS/United States
- R01 HD055741/HD/NICHD NIH HHS/United States
- R01 HD088125/HD/NICHD NIH HHS/United States
- P50 HD103573/HD/NICHD NIH HHS/United States
- R01 MH122447/MH/NIMH NIH HHS/United States
- U54 HD079124/HD/NICHD NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources