

Resolution enhancement with a task-assisted GAN to guide optical nanoscopy image analysis and acquisition
- PMID: 37615032
- PMCID: PMC10442226
- DOI: 10.1038/s42256-023-00689-3
Resolution enhancement with a task-assisted GAN to guide optical nanoscopy image analysis and acquisition
Abstract
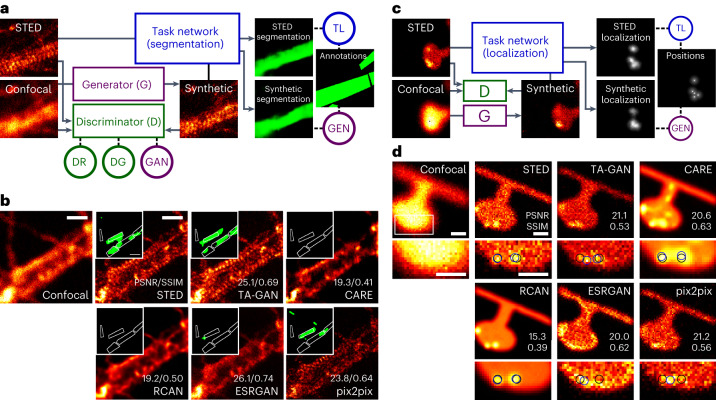
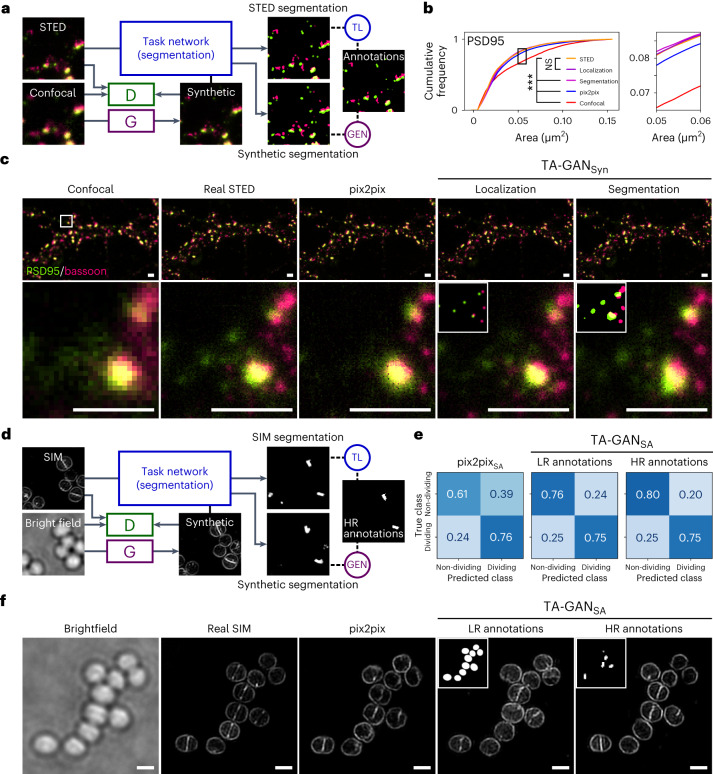
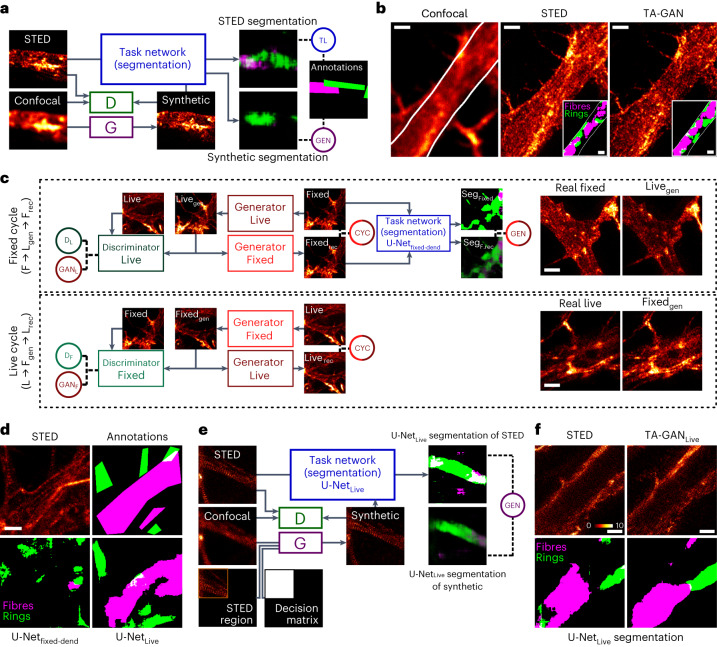
Super-resolution fluorescence microscopy methods enable the characterization of nanostructures in living and fixed biological tissues. However, they require the adjustment of multiple imaging parameters while attempting to satisfy conflicting objectives, such as maximizing spatial and temporal resolution while minimizing light exposure. To overcome the limitations imposed by these trade-offs, post-acquisition algorithmic approaches have been proposed for resolution enhancement and image-quality improvement. Here we introduce the task-assisted generative adversarial network (TA-GAN), which incorporates an auxiliary task (for example, segmentation, localization) closely related to the observed biological nanostructure characterization. We evaluate how the TA-GAN improves generative accuracy over unassisted methods, using images acquired with different modalities such as confocal, bright-field, stimulated emission depletion and structured illumination microscopy. The TA-GAN is incorporated directly into the acquisition pipeline of the microscope to predict the nanometric content of the field of view without requiring the acquisition of a super-resolved image. This information is used to automatically select the imaging modality and regions of interest, optimizing the acquisition sequence by reducing light exposure. Data-driven microscopy methods like the TA-GAN will enable the observation of dynamic molecular processes with spatial and temporal resolutions that surpass the limits currently imposed by the trade-offs constraining super-resolution microscopy.
Keywords: Cellular neuroscience; Image processing; Machine learning; Super-resolution microscopy.
© The Author(s) 2023.
Conflict of interest statement
Competing interestsThe authors declare no competing interests.
Figures







References
LinkOut - more resources
Full Text Sources