

Evaluating large language models on medical evidence summarization
- PMID: 37620423
- PMCID: PMC10449915
- DOI: 10.1038/s41746-023-00896-7
Evaluating large language models on medical evidence summarization
Abstract
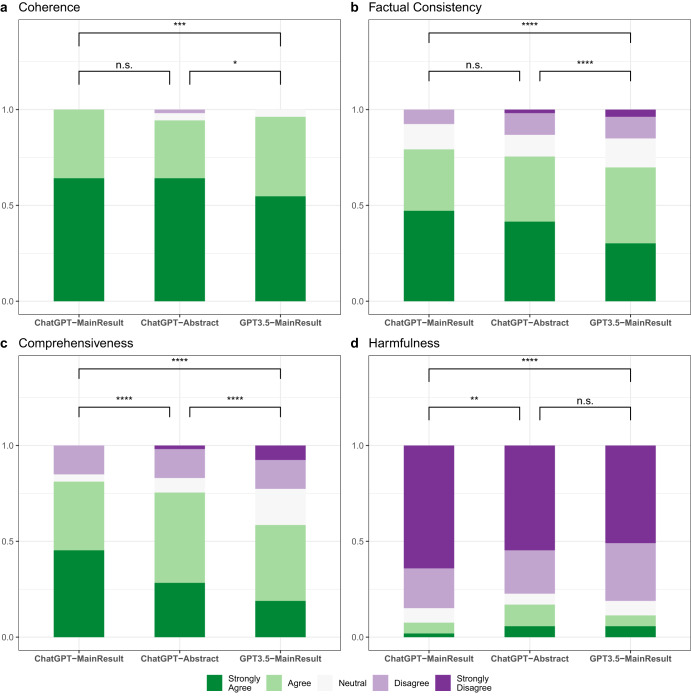
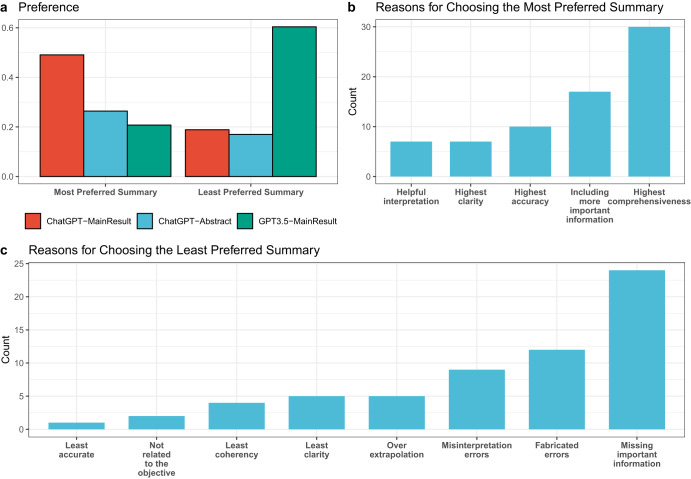
Recent advances in large language models (LLMs) have demonstrated remarkable successes in zero- and few-shot performance on various downstream tasks, paving the way for applications in high-stakes domains. In this study, we systematically examine the capabilities and limitations of LLMs, specifically GPT-3.5 and ChatGPT, in performing zero-shot medical evidence summarization across six clinical domains. We conduct both automatic and human evaluations, covering several dimensions of summary quality. Our study demonstrates that automatic metrics often do not strongly correlate with the quality of summaries. Furthermore, informed by our human evaluations, we define a terminology of error types for medical evidence summarization. Our findings reveal that LLMs could be susceptible to generating factually inconsistent summaries and making overly convincing or uncertain statements, leading to potential harm due to misinformation. Moreover, we find that models struggle to identify the salient information and are more error-prone when summarizing over longer textual contexts.
© 2023. Springer Nature Limited.
Conflict of interest statement
The authors declare no competing interests.
Figures

Update of
-
Evaluating Large Language Models on Medical Evidence Summarization.medRxiv [Preprint]. 2023 Apr 24:2023.04.22.23288967. doi: 10.1101/2023.04.22.23288967. medRxiv. 2023. Update in: NPJ Digit Med. 2023 Aug 24;6(1):158. doi: 10.1038/s41746-023-00896-7. PMID: 37162998 Free PMC article. Updated. Preprint.
References
-
- Wei, J. et al. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems Vol. 35 (eds Koyejo, S. et al.) 24824–24837 (Curran Associates, Inc., 2022).
-
- Brown, T. et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems Vol. 33 (eds Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F. & Lin, H.) 1877–1901 (Curran Associates, Inc., 2020).
-
- Chowdhery, A. et al. PaLM: scaling language modeling with pathways. Preprint at https://arxiv.org/abs/2204.02311 (2022).
-
- Kojima, T., Gu, S. S., Reid, M., Matsuo, Y. & Iwasawa, Y. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems Vol. 35 (eds Koyejo, S. et al.) 22199–22213 (Curran Associates, Inc., 2022).
-
- Ouyang, L. et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems Vol. 35 (eds Koyejo, S. et al.) 27730–27744 (Curran Associates, Inc., 2022).
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
