

Self-Supervised Learning Application on COVID-19 Chest X-ray Image Classification Using Masked AutoEncoder
- PMID: 37627786
- PMCID: PMC10451788
- DOI: 10.3390/bioengineering10080901
Self-Supervised Learning Application on COVID-19 Chest X-ray Image Classification Using Masked AutoEncoder
Abstract
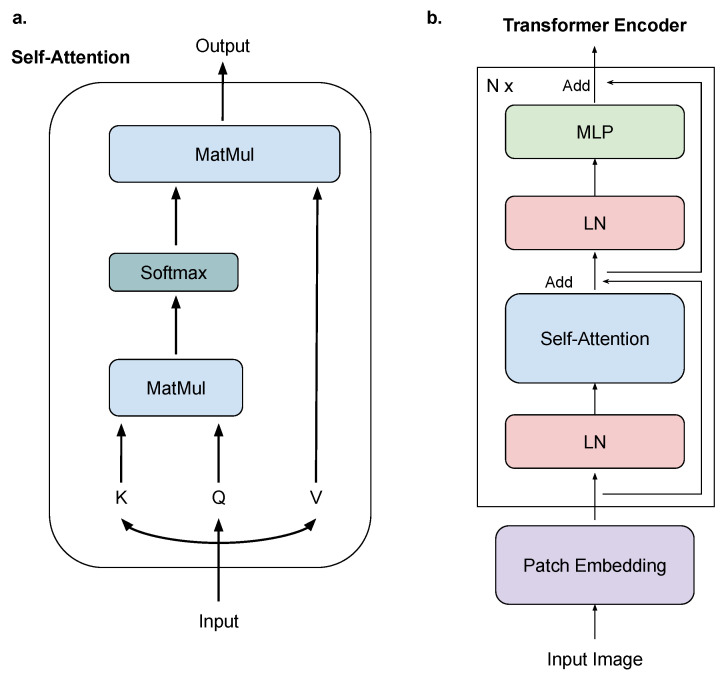
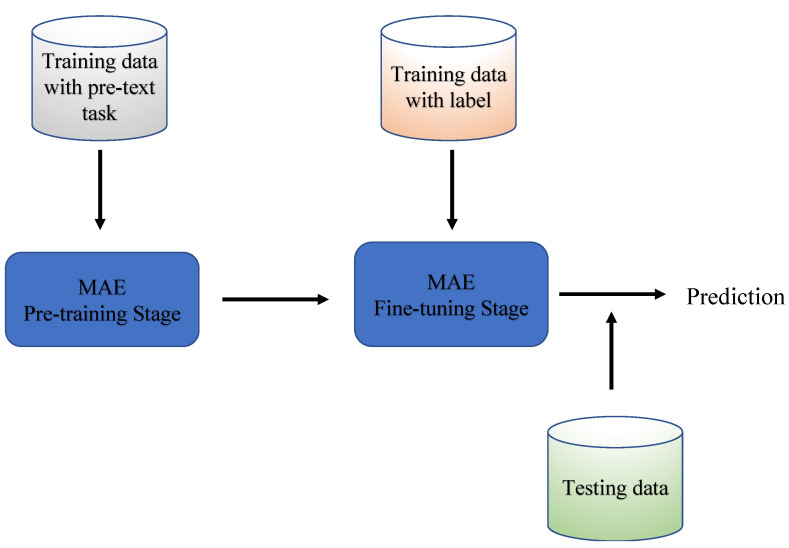
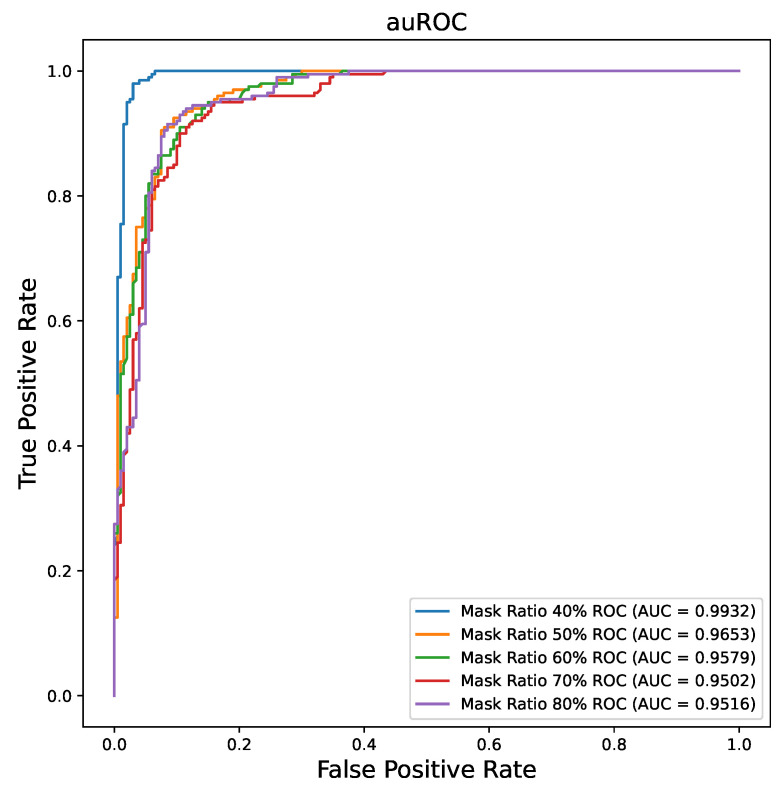
The COVID-19 pandemic has underscored the urgent need for rapid and accurate diagnosis facilitated by artificial intelligence (AI), particularly in computer-aided diagnosis using medical imaging. However, this context presents two notable challenges: high diagnostic accuracy demand and limited availability of medical data for training AI models. To address these issues, we proposed the implementation of a Masked AutoEncoder (MAE), an innovative self-supervised learning approach, for classifying 2D Chest X-ray images. Our approach involved performing imaging reconstruction using a Vision Transformer (ViT) model as the feature encoder, paired with a custom-defined decoder. Additionally, we fine-tuned the pretrained ViT encoder using a labeled medical dataset, serving as the backbone. To evaluate our approach, we conducted a comparative analysis of three distinct training methods: training from scratch, transfer learning, and MAE-based training, all employing COVID-19 chest X-ray images. The results demonstrate that MAE-based training produces superior performance, achieving an accuracy of 0.985 and an AUC of 0.9957. We explored the mask ratio influence on MAE and found ratio = 0.4 shows the best performance. Furthermore, we illustrate that MAE exhibits remarkable efficiency when applied to labeled data, delivering comparable performance to utilizing only 30% of the original training dataset. Overall, our findings highlight the significant performance enhancement achieved by using MAE, particularly when working with limited datasets. This approach holds profound implications for future disease diagnosis, especially in scenarios where imaging information is scarce.
Keywords: chest X-ray image; image classification; self-supervised learning; vision transformer (ViT).
Conflict of interest statement
The authors declare no conflict of interest.
Figures





References
-
- Tan M., Le Q. Efficientnet: Rethinking model scaling for convolutional neural networks; Proceedings of the International Conference on Machine Learning; Long Beach, CA, USA. 9–15 June 2019; pp. 6105–6114.
-
- Huang G., Liu Z., Van Der Maaten L., Weinberger K.Q. Densely connected convolutional networks; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Honolulu, HI, USA. 21–26 July 2017; pp. 4700–4708.
-
- He K., Zhang X., Ren S., Sun J. Deep residual learning for image recognition; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Las Vegas, NV, USA. 26 June–1 July 2016; pp. 770–778.
-
- Xing X., Peng C., Zhang Y., Lin A.L., Jacobs N. AssocFormer: Association Transformer for Multi-label Classification; Proceedings of the 33rd British Machine Vision Conference; London, UK. 21–24 November 2022.
-
- Fu J., Liu J., Tian H., Li Y., Bao Y., Fang Z., Lu H. Dual attention network for scene segmentation; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Long Beach, CA, USA. 15–20 June 2019; pp. 3146–3154.
Grants and funding
LinkOut - more resources
Full Text Sources
