

Predicting and Interpreting Protein Developability Via Transfer of Convolutional Sequence Representation
- PMID: 37642646
- PMCID: PMC10829850
- DOI: 10.1021/acssynbio.3c00196
Predicting and Interpreting Protein Developability Via Transfer of Convolutional Sequence Representation
Abstract
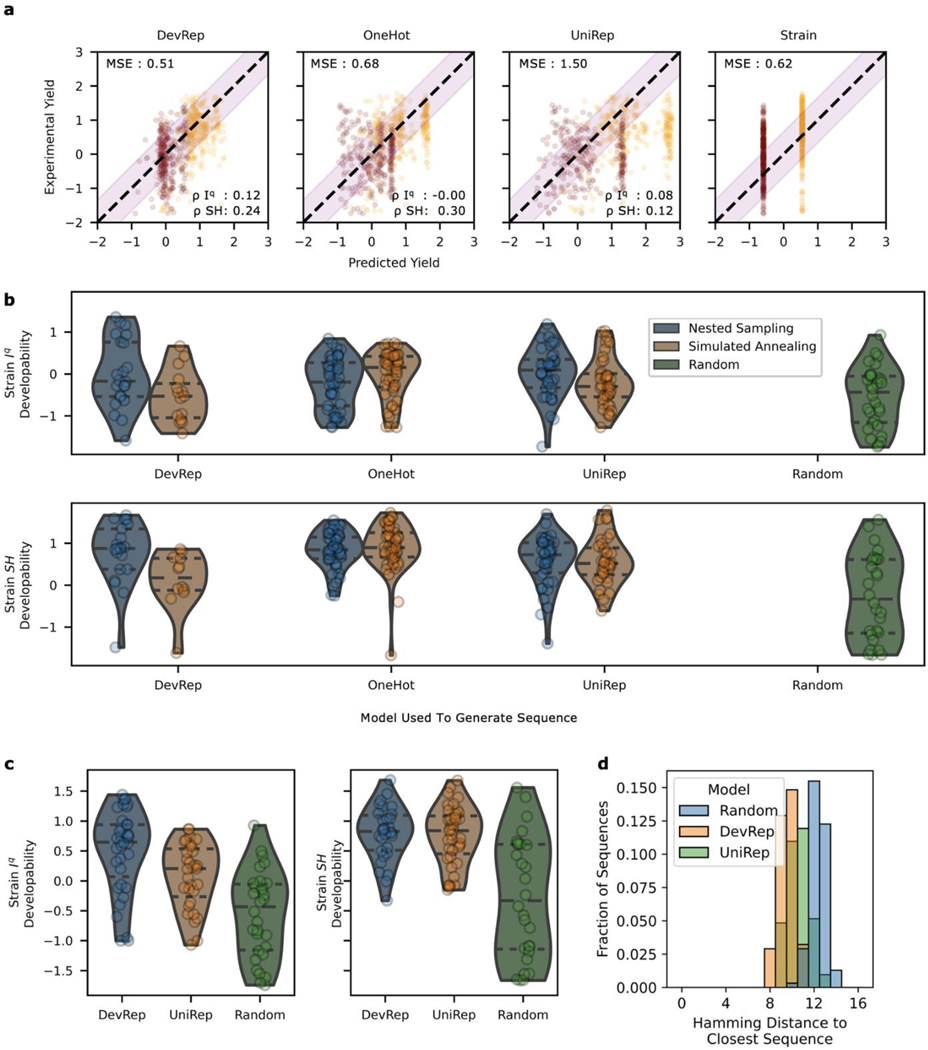
Engineered proteins have emerged as novel diagnostics, therapeutics, and catalysts. Often, poor protein developability─quantified by expression, solubility, and stability─hinders utility. The ability to predict protein developability from amino acid sequence would reduce the experimental burden when selecting candidates. Recent advances in screening technologies enabled a high-throughput (HT) developability dataset for 105 of 1020 possible variants of protein ligand scaffold Gp2. In this work, we evaluate the ability of neural networks to learn a developability representation from a HT dataset and transfer this knowledge to predict recombinant expression beyond observed sequences. The model convolves learned amino acid properties to predict expression levels 44% closer to the experimental variance compared to a non-embedded control. Analysis of learned amino acid embeddings highlights the uniqueness of cysteine, the importance of hydrophobicity and charge, and the unimportance of aromaticity, when aiming to improve the developability of small proteins. We identify clusters of similar sequences with increased recombinant expression through nonlinear dimensionality reduction and we explore the inferred expression landscape via nested sampling. The analysis enables the first direct visualization of the fitness landscape and highlights the existence of evolutionary bottlenecks in sequence space giving rise to competing subpopulations of sequences with different developability. The work advances applied protein engineering efforts by predicting and interpreting protein scaffold expression from a limited dataset. Furthermore, our statistical mechanical treatment of the problem advances foundational efforts to characterize the structure of the protein fitness landscape and the amino acid characteristics that influence protein developability.
Keywords: developability; landscape; model; predictive; protein; sequence.
Figures









Similar articles
-
Sequence-developability mapping of affibody and fibronectin paratopes via library-scale variant characterization.Protein Eng Des Sel. 2024 Jan 29;37:gzae010. doi: 10.1093/protein/gzae010. Protein Eng Des Sel. 2024. PMID: 38836499 Free PMC article.
-
High-throughput developability assays enable library-scale identification of producible protein scaffold variants.Proc Natl Acad Sci U S A. 2021 Jun 8;118(23):e2026658118. doi: 10.1073/pnas.2026658118. Proc Natl Acad Sci U S A. 2021. PMID: 34078670 Free PMC article.
-
Holistic in silico developability assessment of novel classes of small proteins using publicly available sequence-based predictors.J Comput Aided Mol Des. 2024 Aug 20;38(1):30. doi: 10.1007/s10822-024-00569-x. J Comput Aided Mol Des. 2024. PMID: 39164492
-
Protein engineering via sequence-performance mapping.Cell Syst. 2023 Aug 16;14(8):656-666. doi: 10.1016/j.cels.2023.06.009. Epub 2023 Jul 25. Cell Syst. 2023. PMID: 37494931 Free PMC article. Review.
-
Current advances in biopharmaceutical informatics: guidelines, impact and challenges in the computational developability assessment of antibody therapeutics.MAbs. 2022 Jan-Dec;14(1):2020082. doi: 10.1080/19420862.2021.2020082. MAbs. 2022. PMID: 35104168 Free PMC article. Review.
Cited by
-
Sequence-developability mapping of affibody and fibronectin paratopes via library-scale variant characterization.Protein Eng Des Sel. 2024 Jan 29;37:gzae010. doi: 10.1093/protein/gzae010. Protein Eng Des Sel. 2024. PMID: 38836499 Free PMC article.
-
Engineering Affibody Binders to Death Receptor 5 and Tumor Necrosis Factor Receptor 1 With Improved Stability.Biotechnol Bioeng. 2025 Jun;122(6):1386-1396. doi: 10.1002/bit.28954. Epub 2025 Mar 5. Biotechnol Bioeng. 2025. PMID: 40045532 Free PMC article.
-
Multi-Objective Design of DNA-Stabilized Nanoclusters Using Variational Autoencoders With Automatic Feature Extraction.ACS Nano. 2024 Oct 1;18(39):26997-27008. doi: 10.1021/acsnano.4c09640. Epub 2024 Sep 17. ACS Nano. 2024. PMID: 39288200 Free PMC article.
References
-
- Gebauer M, and Skerra A. (2020). Engineered protein scaffolds as next-generation therapeutics. Annu. Rev. Pharmacol. Toxicol. 60, 391–415. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
