

ChatGPT versus human in generating medical graduate exam multiple choice questions-A multinational prospective study (Hong Kong S.A.R., Singapore, Ireland, and the United Kingdom)
- PMID: 37643186
- PMCID: PMC10464959
- DOI: 10.1371/journal.pone.0290691
ChatGPT versus human in generating medical graduate exam multiple choice questions-A multinational prospective study (Hong Kong S.A.R., Singapore, Ireland, and the United Kingdom)
Erratum in
-
Correction: ChatGPT versus human in generating medical graduate exam multiple choice questions-A multinational prospective study (Hong Kong S.A.R., Singapore, Ireland, and the United Kingdom).PLoS One. 2025 Jun 27;20(6):e0327290. doi: 10.1371/journal.pone.0327290. eCollection 2025. PLoS One. 2025. PMID: 40577328 Free PMC article.
Abstract
Introduction: Large language models, in particular ChatGPT, have showcased remarkable language processing capabilities. Given the substantial workload of university medical staff, this study aims to assess the quality of multiple-choice questions (MCQs) produced by ChatGPT for use in graduate medical examinations, compared to questions written by university professoriate staffs based on standard medical textbooks.
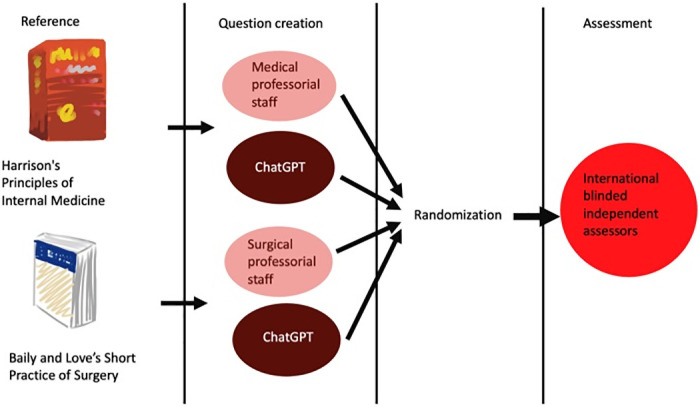
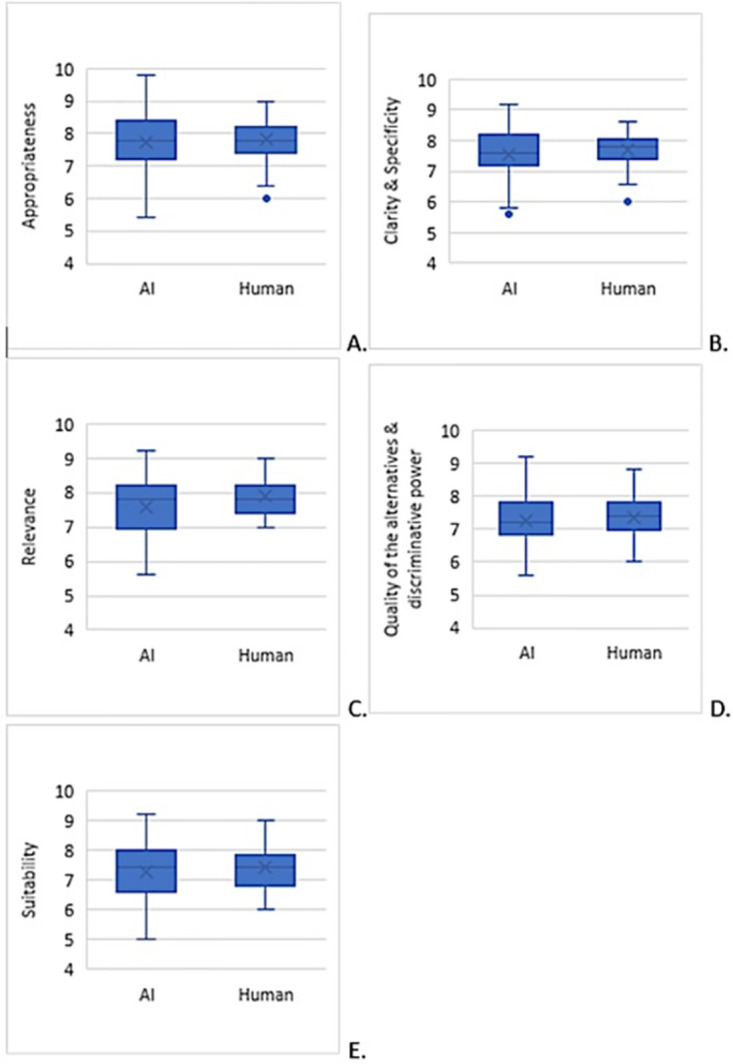
Methods: 50 MCQs were generated by ChatGPT with reference to two standard undergraduate medical textbooks (Harrison's, and Bailey & Love's). Another 50 MCQs were drafted by two university professoriate staff using the same medical textbooks. All 100 MCQ were individually numbered, randomized and sent to five independent international assessors for MCQ quality assessment using a standardized assessment score on five assessment domains, namely, appropriateness of the question, clarity and specificity, relevance, discriminative power of alternatives, and suitability for medical graduate examination.
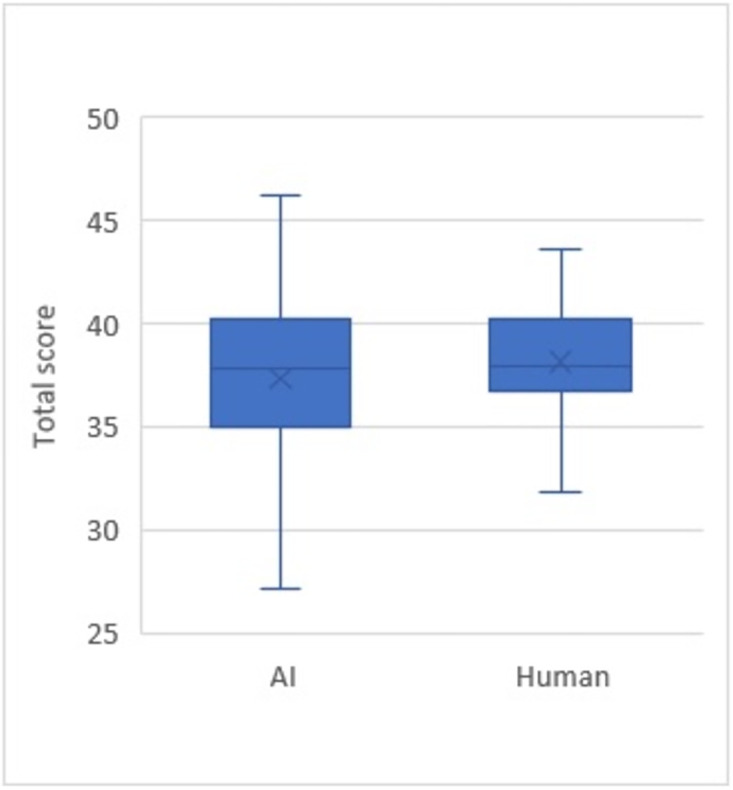
Results: The total time required for ChatGPT to create the 50 questions was 20 minutes 25 seconds, while it took two human examiners a total of 211 minutes 33 seconds to draft the 50 questions. When a comparison of the mean score was made between the questions constructed by A.I. with those drafted by humans, only in the relevance domain that the A.I. was inferior to humans (A.I.: 7.56 +/- 0.94 vs human: 7.88 +/- 0.52; p = 0.04). There was no significant difference in question quality between questions drafted by A.I. versus humans, in the total assessment score as well as in other domains. Questions generated by A.I. yielded a wider range of scores, while those created by humans were consistent and within a narrower range.
Conclusion: ChatGPT has the potential to generate comparable-quality MCQs for medical graduate examinations within a significantly shorter time.
Copyright: © 2023 Cheung et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
No.
Figures
References
-
- Chen L, Chen P, Lin Z. Artificial Intelligence in Education: A Review. IEEE Access. 2020;8:75264–78.
MeSH terms
LinkOut - more resources
Full Text Sources
