

Privacy-preserving continual learning methods for medical image classification: a comparative analysis
- PMID: 37644987
- PMCID: PMC10461441
- DOI: 10.3389/fmed.2023.1227515
Privacy-preserving continual learning methods for medical image classification: a comparative analysis
Abstract
Background: The implementation of deep learning models for medical image classification poses significant challenges, including gradual performance degradation and limited adaptability to new diseases. However, frequent retraining of models is unfeasible and raises concerns about healthcare privacy due to the retention of prior patient data. To address these issues, this study investigated privacy-preserving continual learning methods as an alternative solution.
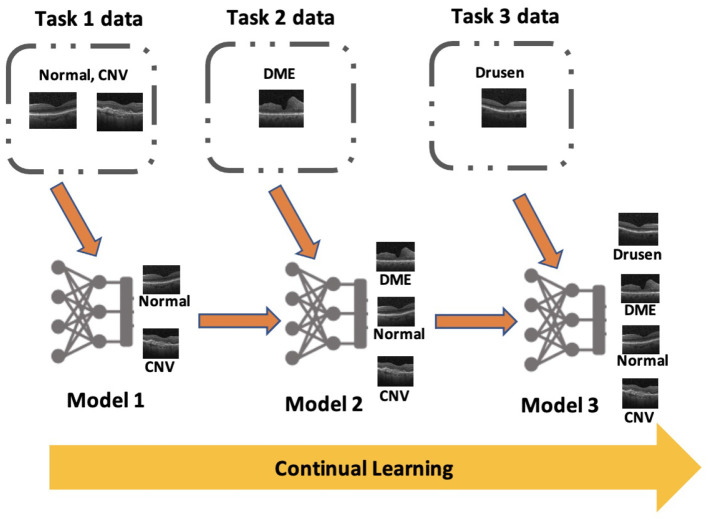
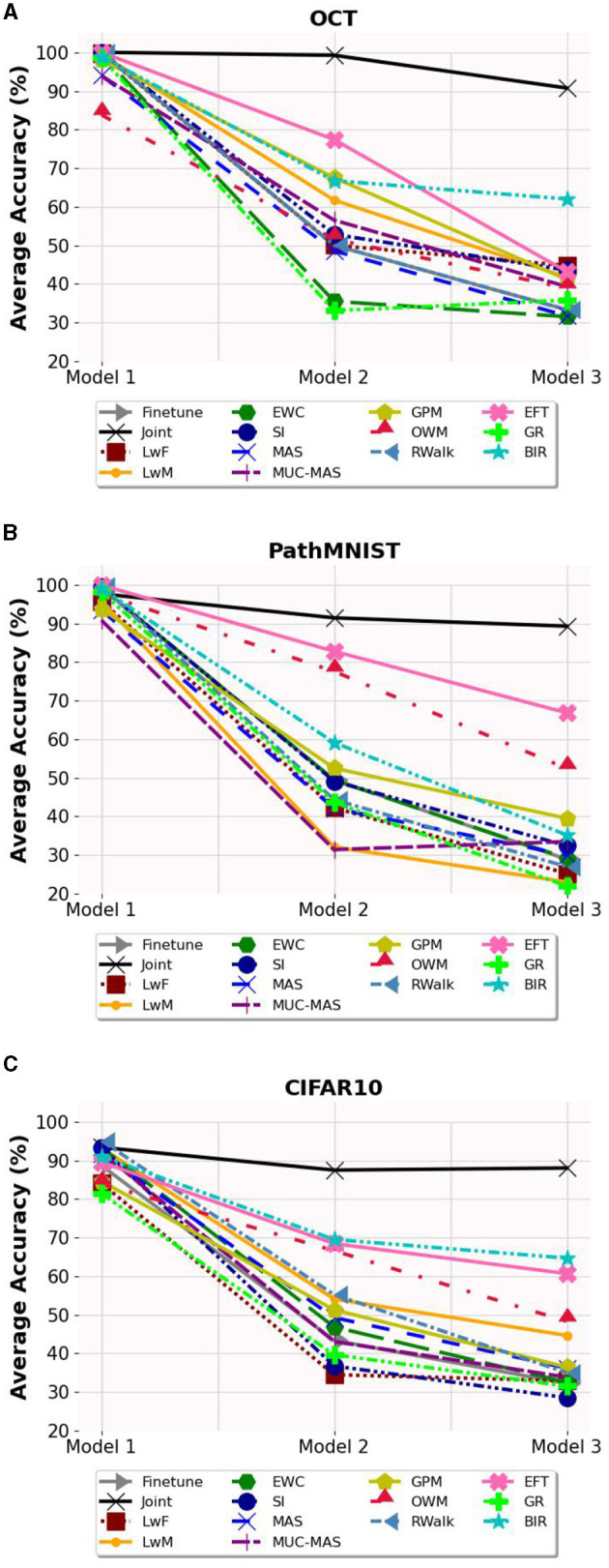
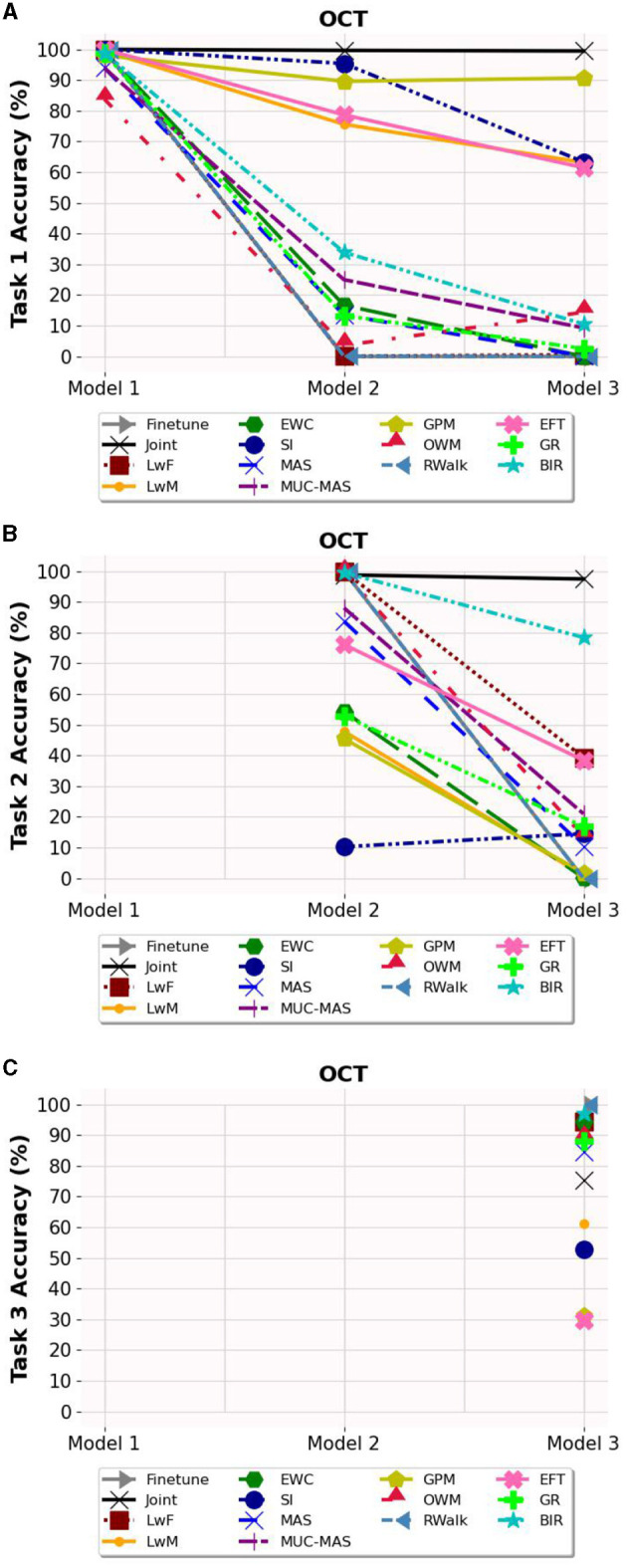
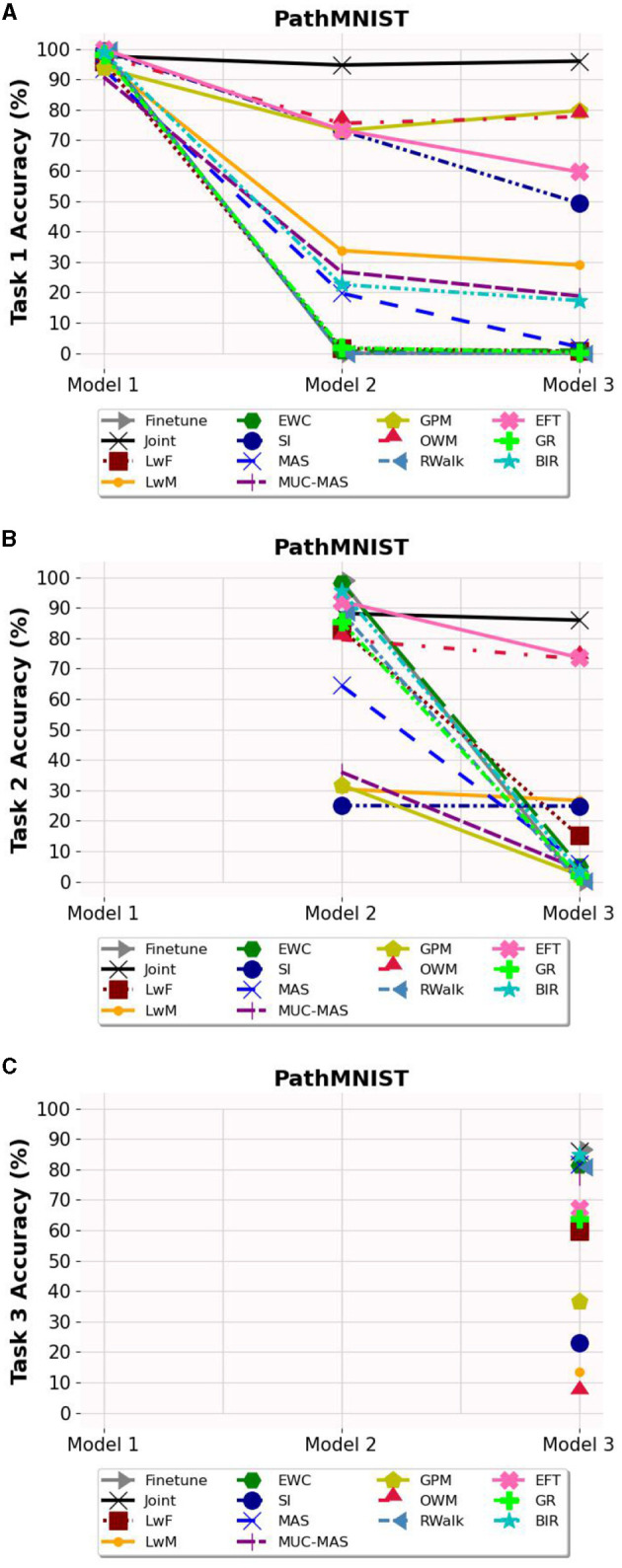
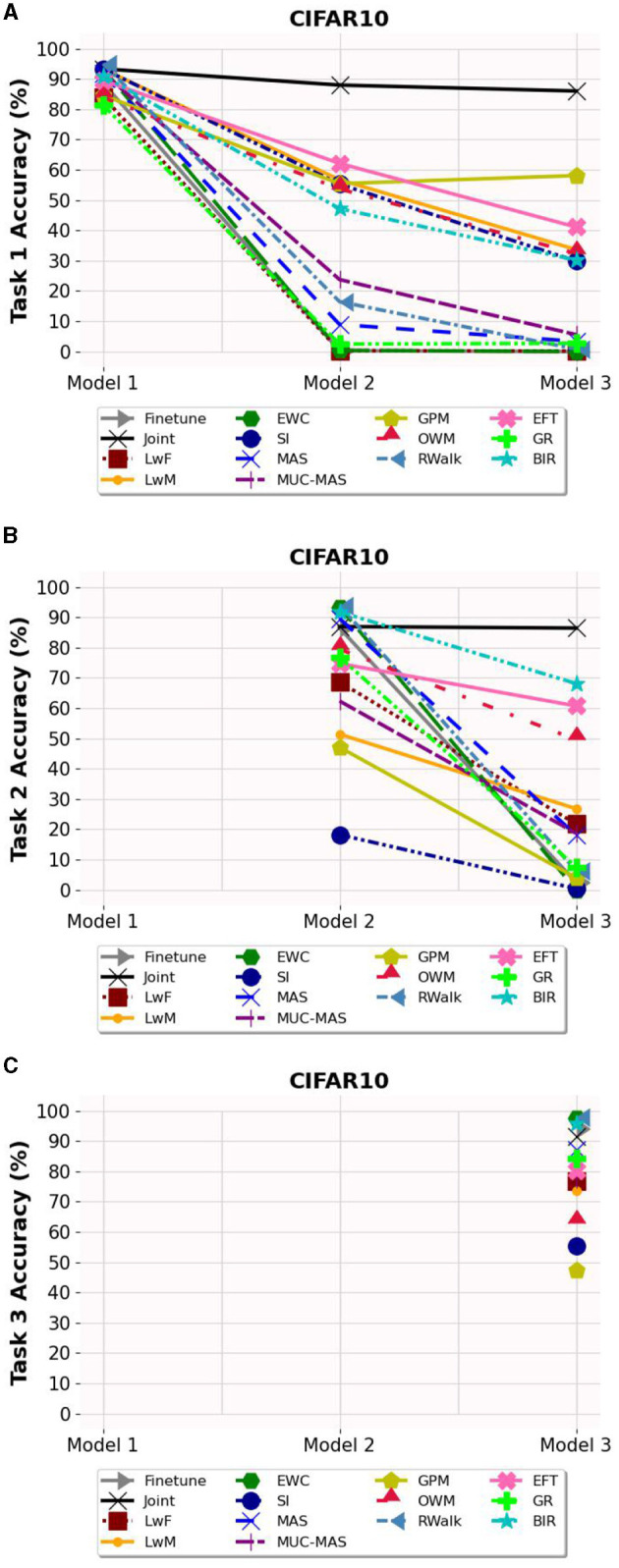
Methods: We evaluated twelve privacy-preserving non-storage continual learning algorithms based deep learning models for classifying retinal diseases from public optical coherence tomography (OCT) images, in a class-incremental learning scenario. The OCT dataset comprises 108,309 OCT images. Its classes include normal (47.21%), drusen (7.96%), choroidal neovascularization (CNV) (34.35%), and diabetic macular edema (DME) (10.48%). Each class consisted of 250 testing images. For continuous training, the first task involved CNV and normal classes, the second task focused on DME class, and the third task included drusen class. All selected algorithms were further experimented with different training sequence combinations. The final model's average class accuracy was measured. The performance of the joint model obtained through retraining and the original finetune model without continual learning algorithms were compared. Additionally, a publicly available medical dataset for colon cancer detection based on histology slides was selected as a proof of concept, while the CIFAR10 dataset was included as the continual learning benchmark.
Results: Among the continual learning algorithms, Brain-inspired-replay (BIR) outperformed the others in the continual learning-based classification of retinal diseases from OCT images, achieving an accuracy of 62.00% (95% confidence interval: 59.36-64.64%), with consistent top performance observed in different training sequences. For colon cancer histology classification, Efficient Feature Transformations (EFT) attained the highest accuracy of 66.82% (95% confidence interval: 64.23-69.42%). In comparison, the joint model achieved accuracies of 90.76% and 89.28%, respectively. The finetune model demonstrated catastrophic forgetting in both datasets.
Conclusion: Although the joint retraining model exhibited superior performance, continual learning holds promise in mitigating catastrophic forgetting and facilitating continual model updates while preserving privacy in healthcare deep learning models. Thus, it presents a highly promising solution for the long-term clinical deployment of such models.
Keywords: comparative analysis; continual learning; medical image classification; model deployment; optical coherence tomography.
Copyright © 2023 Verma, Jin, Zhou, Huang, Tan, Choong, Tan, Gao, Xu, Ting and Liu.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
Similar articles
-
Deep Learning Classification of Drusen, Choroidal Neovascularization, and Diabetic Macular Edema in Optical Coherence Tomography (OCT) Images.Cureus. 2023 Jul 9;15(7):e41615. doi: 10.7759/cureus.41615. eCollection 2023 Jul. Cureus. 2023. PMID: 37565126 Free PMC article.
-
Fully automated detection of retinal disorders by image-based deep learning.Graefes Arch Clin Exp Ophthalmol. 2019 Mar;257(3):495-505. doi: 10.1007/s00417-018-04224-8. Epub 2019 Jan 4. Graefes Arch Clin Exp Ophthalmol. 2019. PMID: 30610422
-
Deep Residual Network for Diagnosis of Retinal Diseases Using Optical Coherence Tomography Images.Interdiscip Sci. 2022 Dec;14(4):906-916. doi: 10.1007/s12539-022-00533-z. Epub 2022 Jun 29. Interdiscip Sci. 2022. PMID: 35767116
-
Deep learning-based detection of diabetic macular edema using optical coherence tomography and fundus images: A meta-analysis.Indian J Ophthalmol. 2023 May;71(5):1783-1796. doi: 10.4103/IJO.IJO_2614_22. Indian J Ophthalmol. 2023. PMID: 37203031 Free PMC article. Review.
-
Continual learning in medical image analysis: A survey.Comput Biol Med. 2024 Nov;182:109206. doi: 10.1016/j.compbiomed.2024.109206. Epub 2024 Sep 26. Comput Biol Med. 2024. PMID: 39332115 Review.
Cited by
-
Optical coherence tomography (OCT) and OCT angiography: Technological development and applications in brain science.Theranostics. 2025 Jan 1;15(1):122-140. doi: 10.7150/thno.97192. eCollection 2025. Theranostics. 2025. PMID: 39744229 Free PMC article. Review.
References
-
- Goodfellow IJ, Mirza M, Xiao D, Courville A, Bengio Y. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv preprint arXiv:13126211 (2013). 10.48550/arXiv.1312.6211 - DOI
-
- American Health Information Management Association . Retention and destruction of health information. J AHIMA. (2013). Available online at: https://library.ahima.org/PB/RetentionDestruction
-
- Kermany D, Zhang K, Goldbaum M. Large dataset of labeled optical coherence tomography (OCT) and chest x-ray images. Mendeley Data. (2018) 3:10–17632.
-
- Yang J, Shi R, Ni B. “Medmnist classification decathlon: a lightweight autoML benchmark for medical image analysis,” in: 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI). IEEE (2021). p. 191–5.
-
- Krizhevsky A, Hinton G, et al. . Learning multiple layers of features from tiny images (2009). Available online at: https://www.cs.toronto.edu/~kriz/cifar.html
LinkOut - more resources
Full Text Sources