

This is a preprint.
Sigmoni: classification of nanopore signal with a compressed pangenome index
- PMID: 37645873
- PMCID: PMC10462034
- DOI: 10.1101/2023.08.15.553308
Sigmoni: classification of nanopore signal with a compressed pangenome index
Update in
-
Sigmoni: classification of nanopore signal with a compressed pangenome index.Bioinformatics. 2024 Jun 28;40(Suppl 1):i287-i296. doi: 10.1093/bioinformatics/btae213. Bioinformatics. 2024. PMID: 38940135 Free PMC article.
Abstract
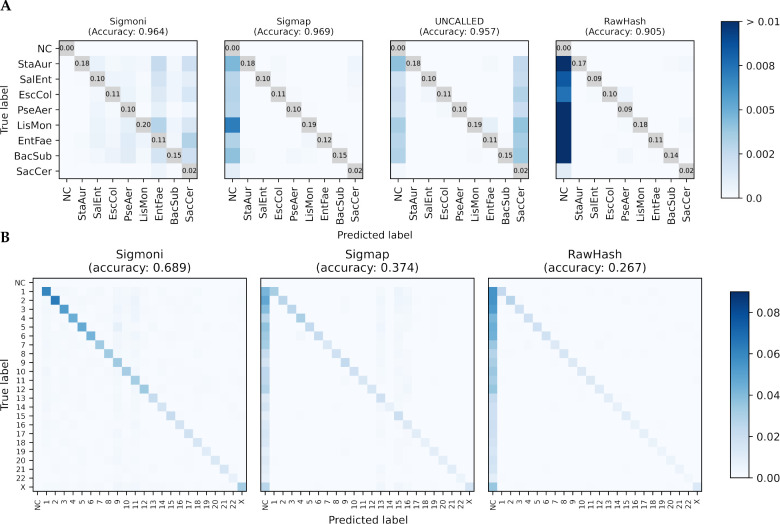
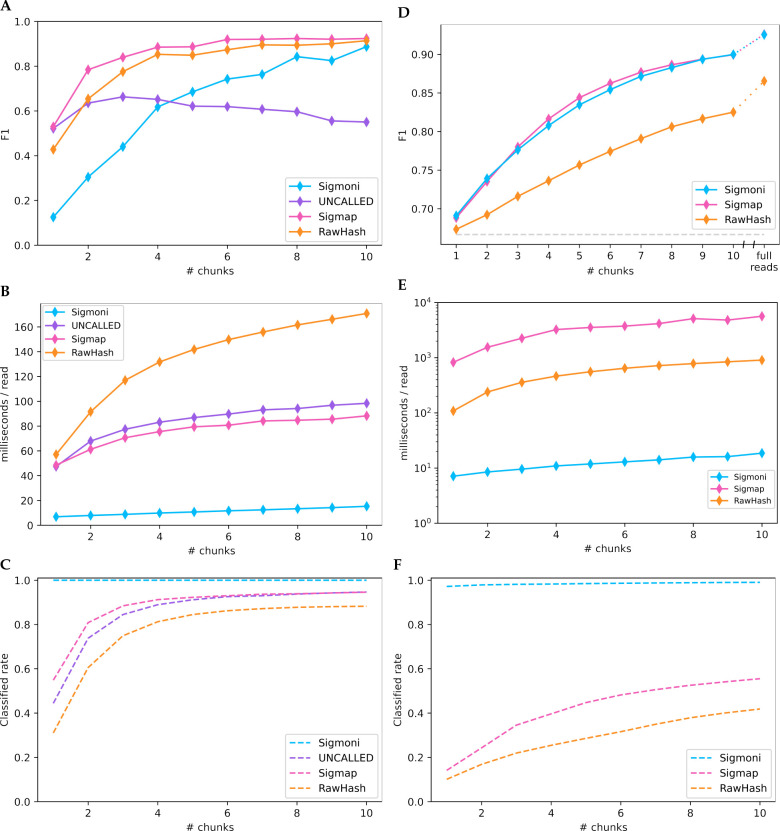
Improvements in nanopore sequencing necessitate efficient classification methods, including pre-filtering and adaptive sampling algorithms that enrich for reads of interest. Signal-based approaches circumvent the computational bottleneck of basecalling. But past methods for signal-based classification do not scale efficiently to large, repetitive references like pangenomes, limiting their utility to partial references or individual genomes. We introduce Sigmoni: a rapid, multiclass classification method based on the r-index that scales to references of hundreds of Gbps. Sigmoni quantizes nanopore signal into a discrete alphabet of picoamp ranges. It performs rapid, approximate matching using matching statistics, classifying reads based on distributions of picoamp matching statistics and co-linearity statistics. Sigmoni is 10-100× faster than previous methods for adaptive sampling in host depletion experiments with improved accuracy, and can query reads against large microbial or human pangenomes.
Conflict of interest statement
9 Competing interests SK has received travel funding from Oxford Nanopore Technologies Limited.
Figures

References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous