

Champion-level drone racing using deep reinforcement learning
- PMID: 37648758
- PMCID: PMC10468397
- DOI: 10.1038/s41586-023-06419-4
Champion-level drone racing using deep reinforcement learning
Abstract
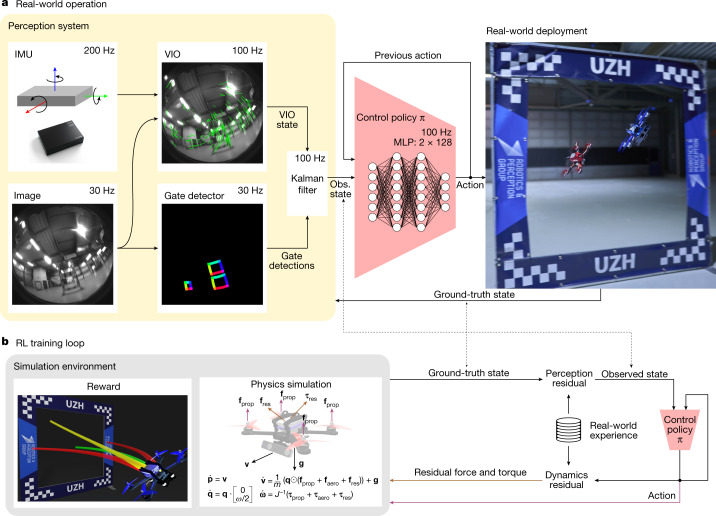
First-person view (FPV) drone racing is a televised sport in which professional competitors pilot high-speed aircraft through a 3D circuit. Each pilot sees the environment from the perspective of their drone by means of video streamed from an onboard camera. Reaching the level of professional pilots with an autonomous drone is challenging because the robot needs to fly at its physical limits while estimating its speed and location in the circuit exclusively from onboard sensors1. Here we introduce Swift, an autonomous system that can race physical vehicles at the level of the human world champions. The system combines deep reinforcement learning (RL) in simulation with data collected in the physical world. Swift competed against three human champions, including the world champions of two international leagues, in real-world head-to-head races. Swift won several races against each of the human champions and demonstrated the fastest recorded race time. This work represents a milestone for mobile robotics and machine intelligence2, which may inspire the deployment of hybrid learning-based solutions in other physical systems.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures





References
-
- De Wagter C, Paredes-Vallés F, Sheth N, de Croon G. Learning fast in autonomous drone racing. Nat. Mach. Intell. 2021;3:923. doi: 10.1038/s42256-021-00405-z. - DOI
-
- Hanover, D. et al. Autonomous drone racing: a survey. Preprint at https://arxiv.org/abs/2301.01755 (2023).
-
- Sutton, R. S. & Barto, A. G. Reinforcement Learning: An Introduction (MIT Press, 2018).
LinkOut - more resources
Full Text Sources
Other Literature Sources
