

This is a preprint.
A mathematical theory of relational generalization in transitive inference
- PMID: 37662223
- PMCID: PMC10473627
- DOI: 10.1101/2023.08.22.554287
A mathematical theory of relational generalization in transitive inference
Update in
-
A mathematical theory of relational generalization in transitive inference.Proc Natl Acad Sci U S A. 2024 Jul 9;121(28):e2314511121. doi: 10.1073/pnas.2314511121. Epub 2024 Jul 5. Proc Natl Acad Sci U S A. 2024. PMID: 38968113 Free PMC article.
Abstract
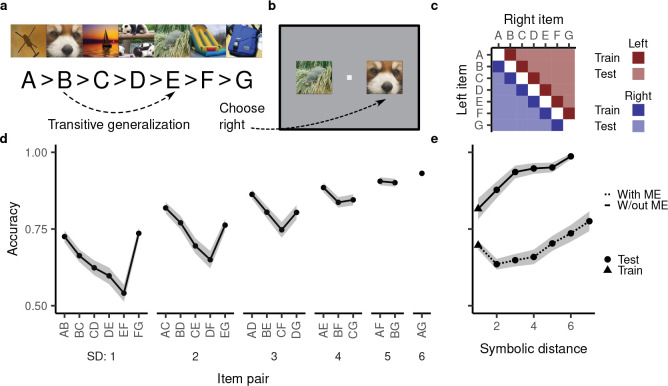
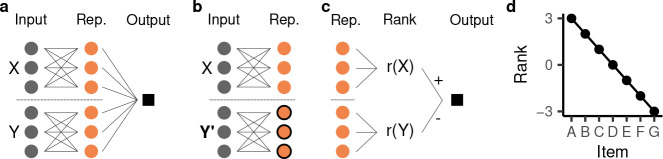
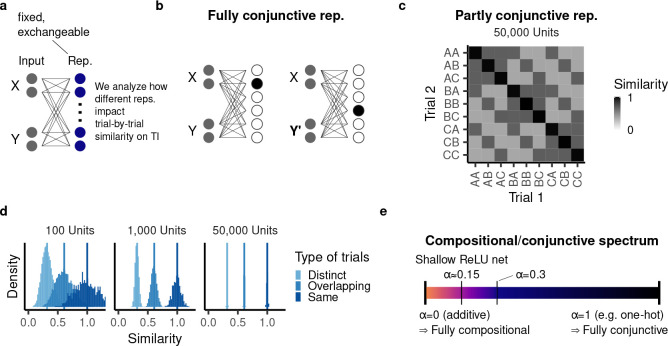
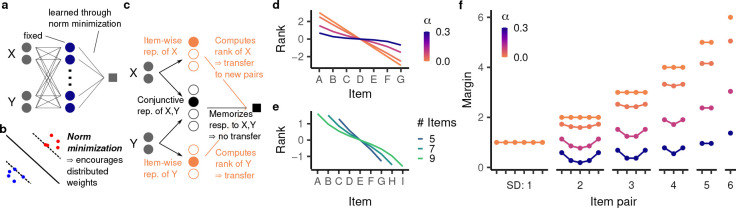
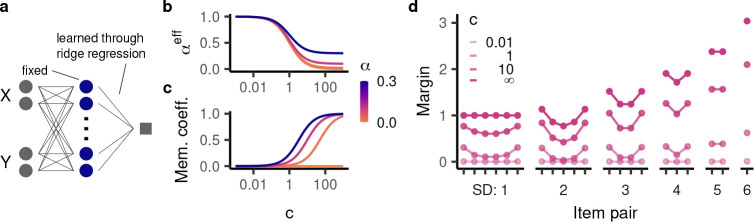
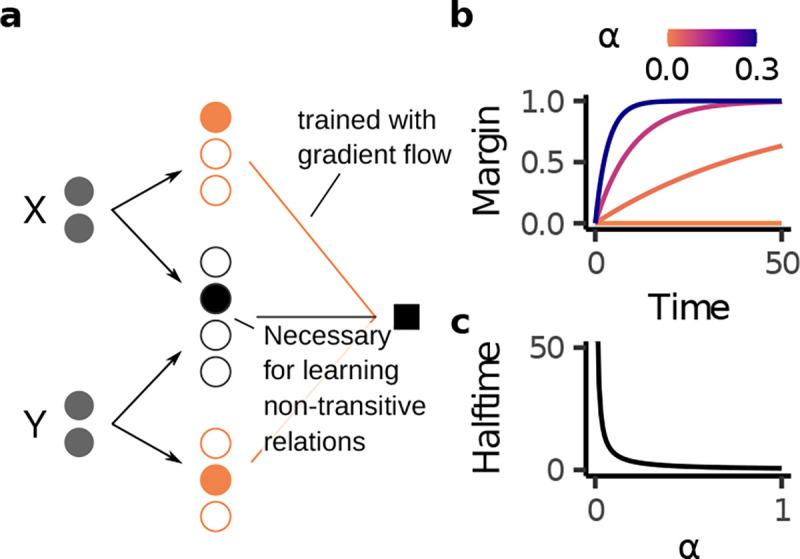
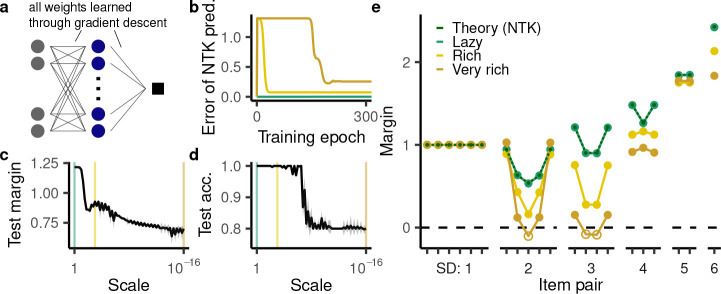
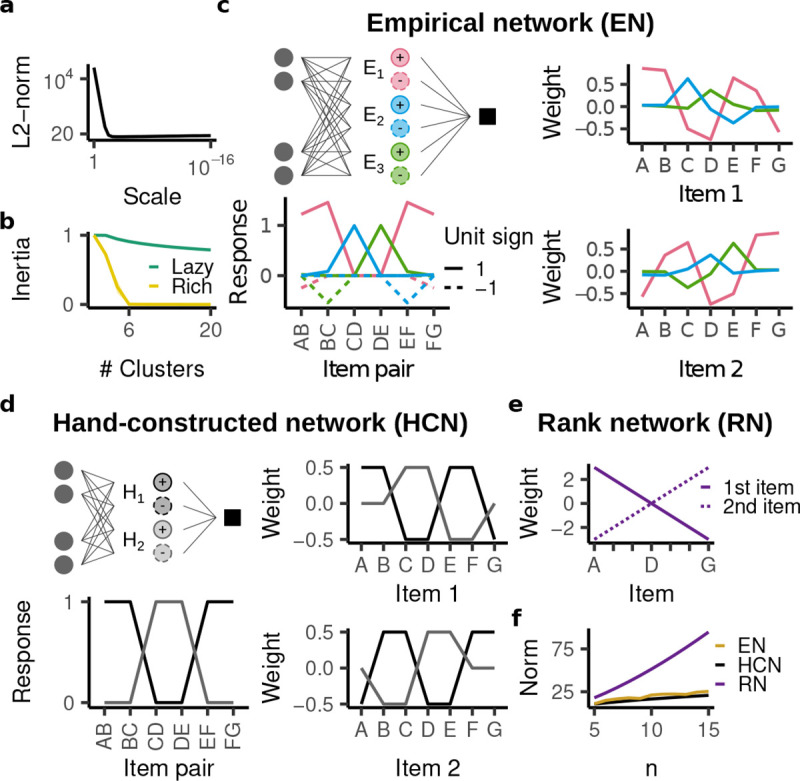
Humans and animals routinely infer relations between different items or events and generalize these relations to novel combinations of items. This allows them to respond appropriately to radically novel circumstances and is fundamental to advanced cognition. However, how learning systems (including the brain) can implement the necessary inductive biases has been unclear. Here we investigated transitive inference (TI), a classic relational task paradigm in which subjects must learn a relation (A > B and B > C) and generalize it to new combinations of items (A > C). Through mathematical analysis, we found that a broad range of biologically relevant learning models (e.g. gradient flow or ridge regression) perform TI successfully and recapitulate signature behavioral patterns long observed in living subjects. First, we found that models with item-wise additive representations automatically encode transitive relations. Second, for more general representations, a single scalar "conjunctivity factor" determines model behavior on TI and, further, the principle of norm minimization (a standard statistical inductive bias) enables models with fixed, partly conjunctive representations to generalize transitively. Finally, neural networks in the "rich regime," which enables representation learning and has been found to improve generalization, unexpectedly show poor generalization and anomalous behavior. We find that such networks implement a form of norm minimization (over hidden weights) that yields a local encoding mechanism lacking transitivity. Our findings show how minimal statistical learning principles give rise to a classical relational inductive bias (transitivity), explain empirically observed behaviors, and establish a formal approach to understanding the neural basis of relational abstraction.
Figures
Similar articles
-
A mathematical theory of relational generalization in transitive inference.Proc Natl Acad Sci U S A. 2024 Jul 9;121(28):e2314511121. doi: 10.1073/pnas.2314511121. Epub 2024 Jul 5. Proc Natl Acad Sci U S A. 2024. PMID: 38968113 Free PMC article.
-
Emergent neural dynamics and geometry for generalization in a transitive inference task.PLoS Comput Biol. 2024 Apr 25;20(4):e1011954. doi: 10.1371/journal.pcbi.1011954. eCollection 2024 Apr. PLoS Comput Biol. 2024. PMID: 38662797 Free PMC article.
-
Transitivity performance, relational hierarchy knowledge and awareness: results of an instructional framing manipulation.Hippocampus. 2013 Dec;23(12):1259-68. doi: 10.1002/hipo.22163. Epub 2013 Aug 5. Hippocampus. 2013. PMID: 23804544 Free PMC article. Clinical Trial.
-
Discovering Implied Serial Order Through Model-Free and Model-Based Learning.Front Neurosci. 2019 Aug 20;13:878. doi: 10.3389/fnins.2019.00878. eCollection 2019. Front Neurosci. 2019. PMID: 31481871 Free PMC article. Review.
-
Transitive inference as probabilistic preference learning.Psychon Bull Rev. 2025 Apr;32(2):674-689. doi: 10.3758/s13423-024-02600-6. Epub 2024 Oct 22. Psychon Bull Rev. 2025. PMID: 39438427 Review.
References
-
- Halford G. S., Wilson W. H. & Phillips S. Relational knowledge: the foundation of higher cognition. en. Trends in Cognitive Sciences 14, 497–505. ISSN: 1364-6613. https://www.sciencedirect.com/science/article/pii/S1364661310002020 (2023) (Nov. 2010). - PubMed
-
- Cheney D. L., Seyfarth R. M. & Silk J. B. The responses of female baboons (Papio cynocephalus ursinus) to anomalous social interactions: Evidence for causal reasoning? Journal of Comparative Psychology 109, 134–141. ISSN: 1939-2087(Electronic),0735-7036(Print) (1995). - PubMed
-
- Peake T. M., Terry A. M. R., McGregor P. K. & Dabelsteen T. Do great tits assess rivals by combining direct experience with information gathered by eavesdropping? Proceedings of the Royal Society of London. Series B: Biological Sciences 269. Publisher: Royal Society, 1925–1929. 10.1098/rspb.2002.2112 (2022) (Sept. 2002). - DOI - PMC - PubMed
-
- Paz-y-Miño C G., Bond A. B., Kamil A. C. & Balda R. P. Pinyon jays use transitive inference to predict social dominance. en. Nature 430. Number: 7001 Publisher: Nature Publishing Group, 778–781. ISSN: 1476–4687. https://www.nature.com/articles/nature02723 (2022) (Aug. 2004). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources