

Transfer Learning with Kernel Methods
- PMID: 37689796
- PMCID: PMC10492830
- DOI: 10.1038/s41467-023-41215-8
Transfer Learning with Kernel Methods
Abstract
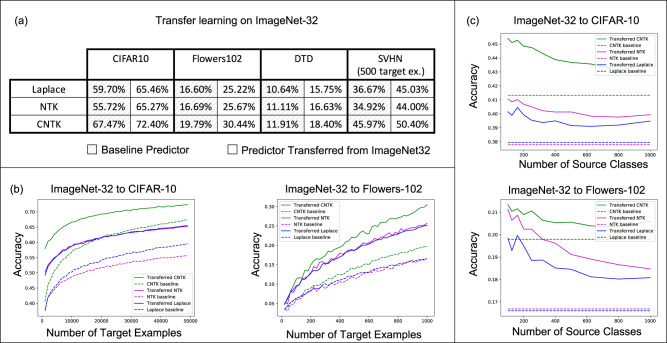
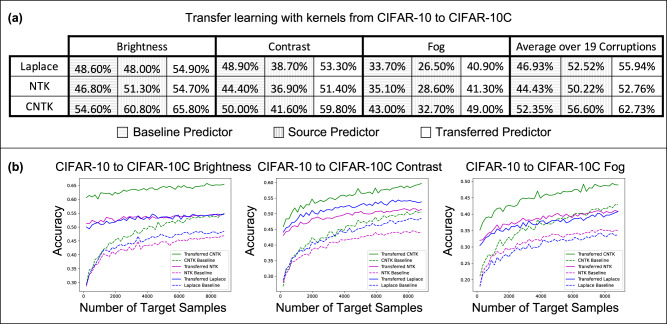
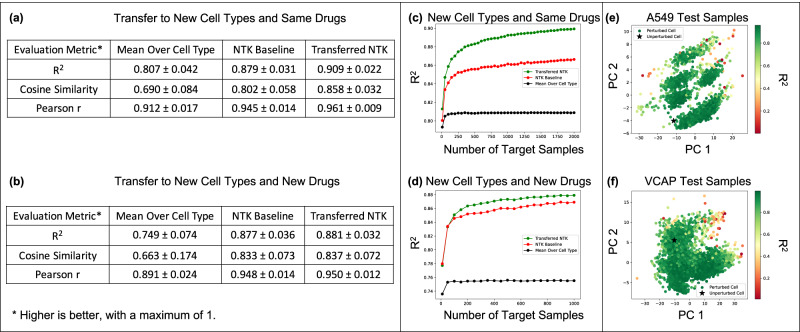
Transfer learning refers to the process of adapting a model trained on a source task to a target task. While kernel methods are conceptually and computationally simple models that are competitive on a variety of tasks, it has been unclear how to develop scalable kernel-based transfer learning methods across general source and target tasks with possibly differing label dimensions. In this work, we propose a transfer learning framework for kernel methods by projecting and translating the source model to the target task. We demonstrate the effectiveness of our framework in applications to image classification and virtual drug screening. For both applications, we identify simple scaling laws that characterize the performance of transfer-learned kernels as a function of the number of target examples. We explain this phenomenon in a simplified linear setting, where we are able to derive the exact scaling laws.
© 2023. Springer Nature Limited.
Conflict of interest statement
The authors declare no competing interests.
Figures

References
-
- Razavian, A. S., Azizpour, H., Sullivan, J. & Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In IEEE Conference on Computer Vision and Pattern Recognition Workshops (2014).
-
- Donahue, J. et al. Decaf: A deep convolutional activation feature for generic visual recognition. In International Conference on Machine Learning (2014).
-
- Peters, M. E. et al. Deep contextualized word representations. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) (2018).
-
- Raffel C, et al. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020;21:1–67. - PubMed
-
- Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (2019).
Grants and funding
LinkOut - more resources
Full Text Sources
