

This is a preprint.
A systems vaccinology resource to develop and test computational models of immunity
- PMID: 37693565
- PMCID: PMC10491180
- DOI: 10.1101/2023.08.28.555193
A systems vaccinology resource to develop and test computational models of immunity
Update in
-
A multi-omics systems vaccinology resource to develop and test computational models of immunity.Cell Rep Methods. 2024 Mar 25;4(3):100731. doi: 10.1016/j.crmeth.2024.100731. Epub 2024 Mar 14. Cell Rep Methods. 2024. PMID: 38490204 Free PMC article.
Abstract
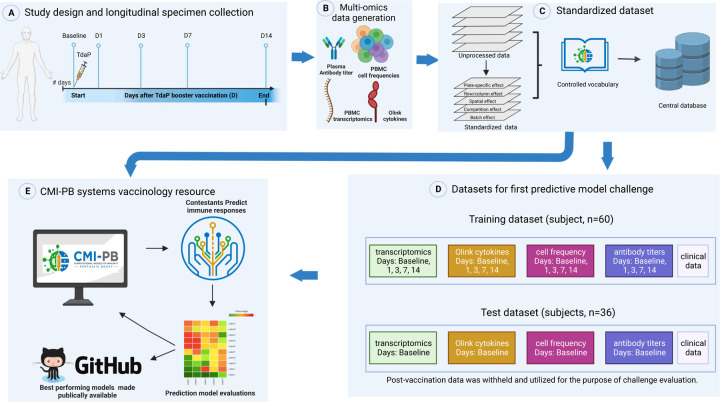
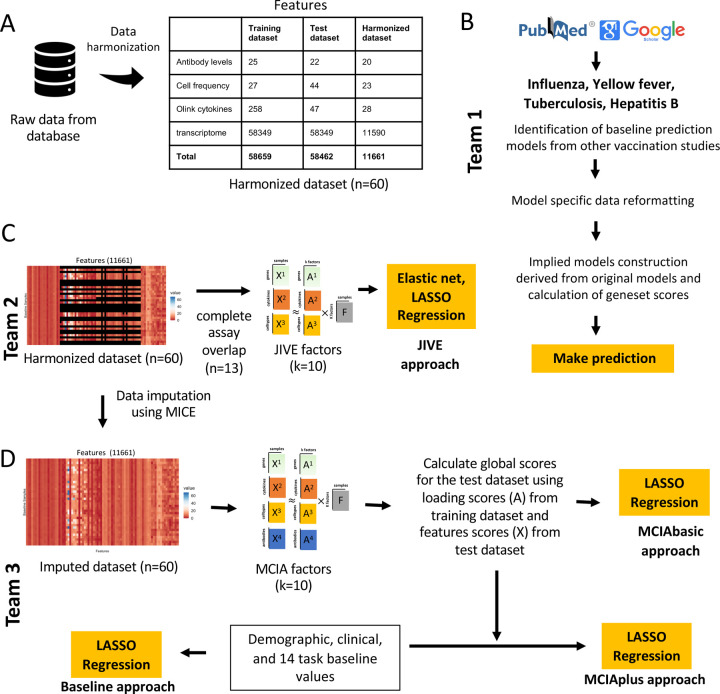
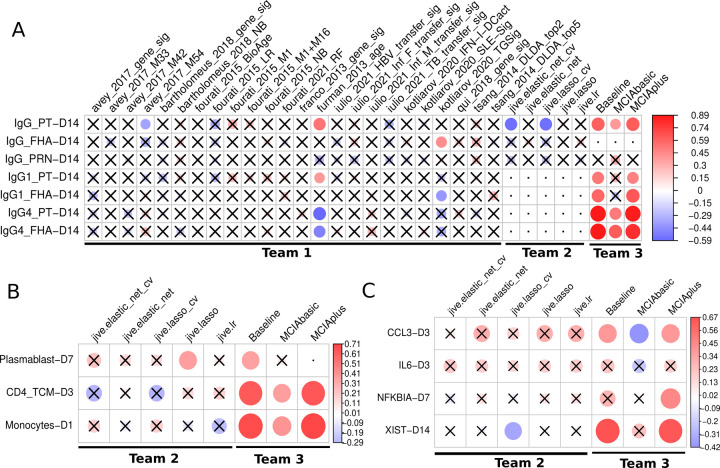
Computational models that predict an individual's response to a vaccine offer the potential for mechanistic insights and personalized vaccination strategies. These models are increasingly derived from systems vaccinology studies that generate immune profiles from human cohorts pre- and post-vaccination. Most of these studies involve relatively small cohorts and profile the response to a single vaccine. The ability to assess the performance of the resulting models would be improved by comparing their performance on independent datasets, as has been done with great success in other areas of biology such as protein structure predictions. To transfer this approach to system vaccinology studies, we established a prototype platform that focuses on the evaluation of Computational Models of Immunity to Pertussis Booster vaccinations (CMI-PB). A community resource, CMI-PB generates experimental data for the explicit purpose of model evaluation, which is performed through a series of annual data releases and associated contests. We here report on our experience with the first such 'dry run' for a contest where the goal was to predict individual immune responses based on pre-vaccination multi-omic profiles. Over 30 models adopted from the literature were tested, but only one was predictive, and was based on age alone. The performance of new models built using CMI-PB training data was much better, but varied significantly based on the choice of pre-vaccination features used and the model building strategy. This suggests that previously published models developed for other vaccines do not generalize well to Pertussis Booster vaccination. Overall, these results reinforced the need for comparative analysis across models and datasets that CMI-PB aims to achieve. We are seeking wider community engagement for our first public prediction contest, which will open in early 2024.
Figures
References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources