

Sample-efficient multi-agent reinforcement learning with masked reconstruction
- PMID: 37708154
- PMCID: PMC10501567
- DOI: 10.1371/journal.pone.0291545
Sample-efficient multi-agent reinforcement learning with masked reconstruction
Abstract
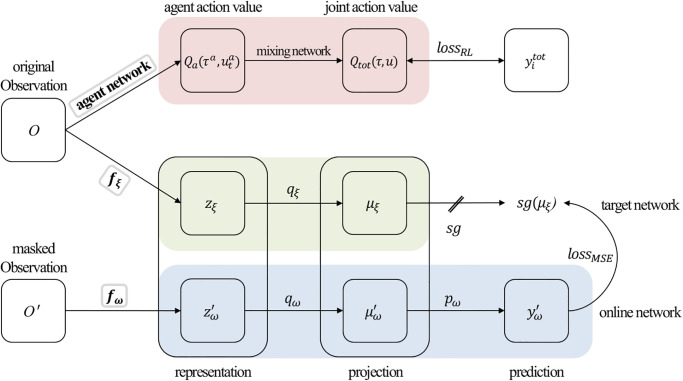
Deep reinforcement learning (DRL) is a powerful approach that combines reinforcement learning (RL) and deep learning to address complex decision-making problems in high-dimensional environments. Although DRL has been remarkably successful, its low sample efficiency necessitates extensive training times and large amounts of data to learn optimal policies. These limitations are more pronounced in the context of multi-agent reinforcement learning (MARL). To address these limitations, various studies have been conducted to improve DRL. In this study, we propose an approach that combines a masked reconstruction task with QMIX (M-QMIX). By introducing a masked reconstruction task as an auxiliary task, we aim to achieve enhanced sample efficiency-a fundamental limitation of RL in multi-agent systems. Experiments were conducted using the StarCraft II micromanagement benchmark to validate the effectiveness of the proposed method. We used 11 scenarios comprising five easy, three hard, and three very hard scenarios. We particularly focused on using a limited number of time steps for each scenario to demonstrate the improved sample efficiency. Compared to QMIX, the proposed method is superior in eight of the 11 scenarios. These results provide strong evidence that the proposed method is more sample-efficient than QMIX, demonstrating that it effectively addresses the limitations of DRL in multi-agent systems.
Copyright: © 2023 Kim et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures






References
-
- CHüttenrauch, M., Šošić, A., Neumann, G. Guided deep reinforcement learning for swarm systems. arXiv preprint arXiv:170906011. 2017;. 10.48550/arXiv.1709.06011 - DOI
-
- Cao Yongcan and Yu Wenwu and Ren Wei and Chen Guanrong. An overview of recent progress in the study of distributed multi-agent coordination. IEEE Transactions on Industrial informatics. 2012;9(1):427–438. https://ieeexplore.ieee.org/abstract/document/6303906 doi: 10.1109/TII.2012.2219061 - DOI
-
- Lipowska D, Lipowski A. Emergence of linguistic conventions in multi-agent reinforcement learning. PLoS One. 2018;13(11):e0208095.438. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0208095 - PMC - PubMed
-
- Tampuu A, Matiisen T, Kodelja D, Kuzovkin I, Korjus K, Aru J, et al.. Multiagent cooperation and competition with deep reinforcement learning. PloS one. 2017;12(4):e0172395. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0172395 - PMC - PubMed
-
- Park YJ, Cho YS, Kim SB. Multiagent cooperation and competition with deep reinforcement learning. PloS one. 2019;14(9):e0222215. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0222215 - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
