

Thresholding Gini variable importance with a single-trained random forest: An empirical Bayes approach
- PMID: 37711185
- PMCID: PMC10497997
- DOI: 10.1016/j.csbj.2023.08.033
Thresholding Gini variable importance with a single-trained random forest: An empirical Bayes approach
Abstract
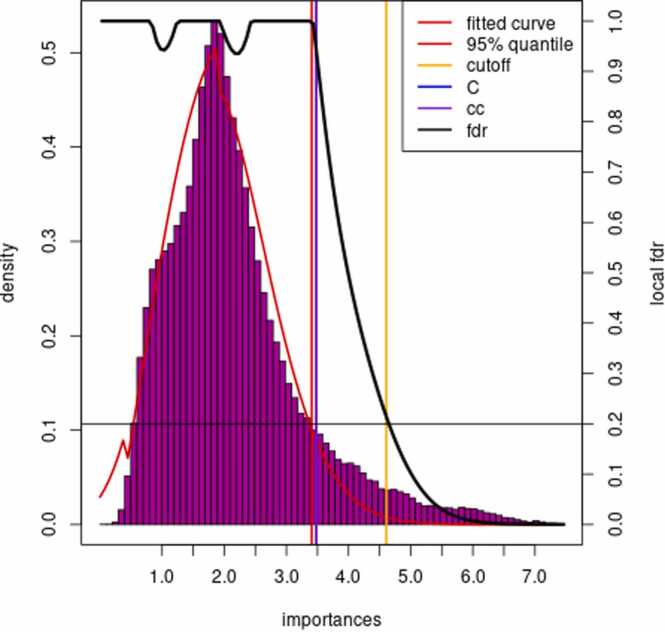
Random forests (RFs) are a widely used modelling tool capable of feature selection via a variable importance measure (VIM), however, a threshold is needed to control for false positives. In the absence of a good understanding of the characteristics of VIMs, many current approaches attempt to select features associated to the response by training multiple RFs to generate statistical power via a permutation null, by employing recursive feature elimination, or through a combination of both. However, for high-dimensional datasets these approaches become computationally infeasible. In this paper, we present RFlocalfdr, a statistical approach, built on the empirical Bayes argument of Efron, for thresholding mean decrease in impurity (MDI) importances. It identifies features significantly associated with the response while controlling the false positive rate. Using synthetic data and real-world data in health, we demonstrate that RFlocalfdr has equivalent accuracy to currently published approaches, while being orders of magnitude faster. We show that RFlocalfdr can successfully threshold a dataset of 106 datapoints, establishing its usability for large-scale datasets, like genomics. Furthermore, RFlocalfdr is compatible with any RF implementation that returns a VIM and counts, making it a versatile feature selection tool that reduces false discoveries.
Keywords: Empirical Bayes; Feature selection; Genetic analysis; Local FDR; Machine learning significance; Random forest.
Crown Copyright © 2023 Published by Elsevier B.V. on behalf of Research Network of Computational and Structural Biotechnology.
Conflict of interest statement
The authors declare no conflict of interest.
Figures




References
-
- Lundberg S.M., Erion G.G., Lee S.-I. Consistent Individualized Feature Attribution for Tree Ensembles. ArXiv180203888 Cs Stat 2019.
-
- Grömping U. Variable importance assessment in regression: linear regression versus random forest. Am Stat. 2009;63:308–319. doi: 10.1198/tast.2009.08199. - DOI
-
- Lundberg S.M., Lee S.-I. A unified approach to interpreting model predictions. Adv Neural Inf Process Syst. 2017;30:4765–4774.
LinkOut - more resources
Full Text Sources
Miscellaneous