

Preliminary assessment of automated radiology report generation with generative pre-trained transformers: comparing results to radiologist-generated reports
- PMID: 37713022
- PMCID: PMC10811038
- DOI: 10.1007/s11604-023-01487-y
Preliminary assessment of automated radiology report generation with generative pre-trained transformers: comparing results to radiologist-generated reports
Abstract
Purpose: In this preliminary study, we aimed to evaluate the potential of the generative pre-trained transformer (GPT) series for generating radiology reports from concise imaging findings and compare its performance with radiologist-generated reports.
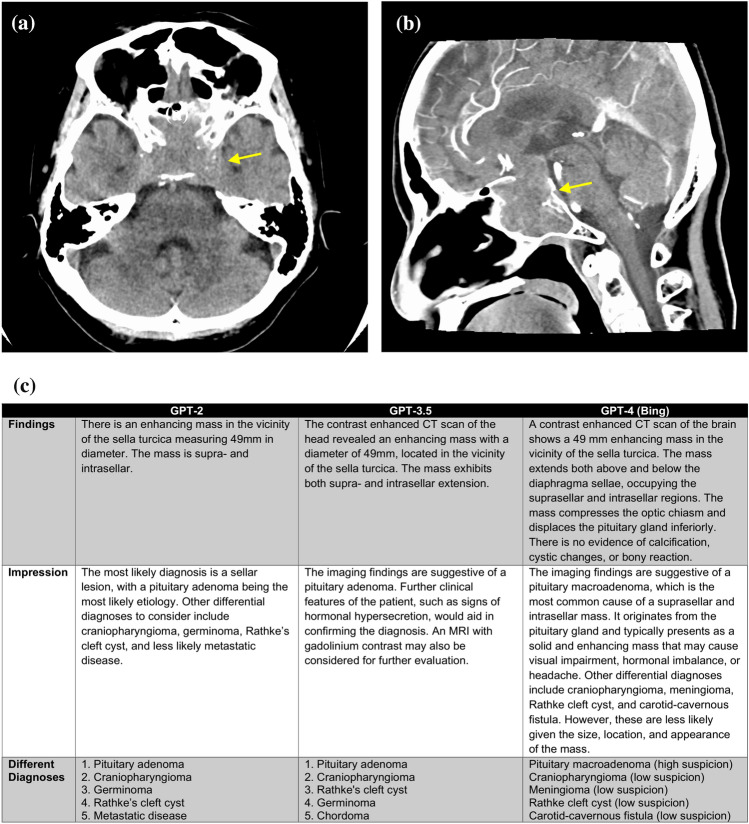
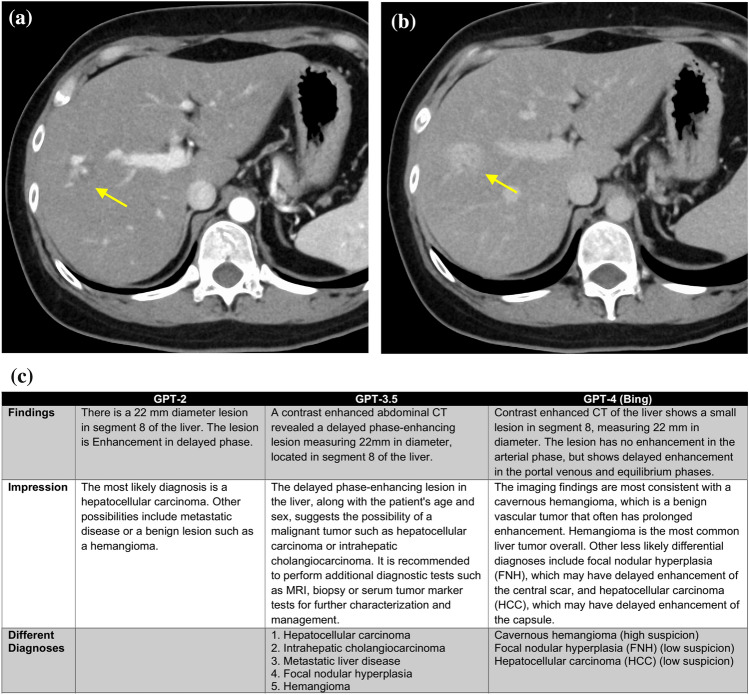
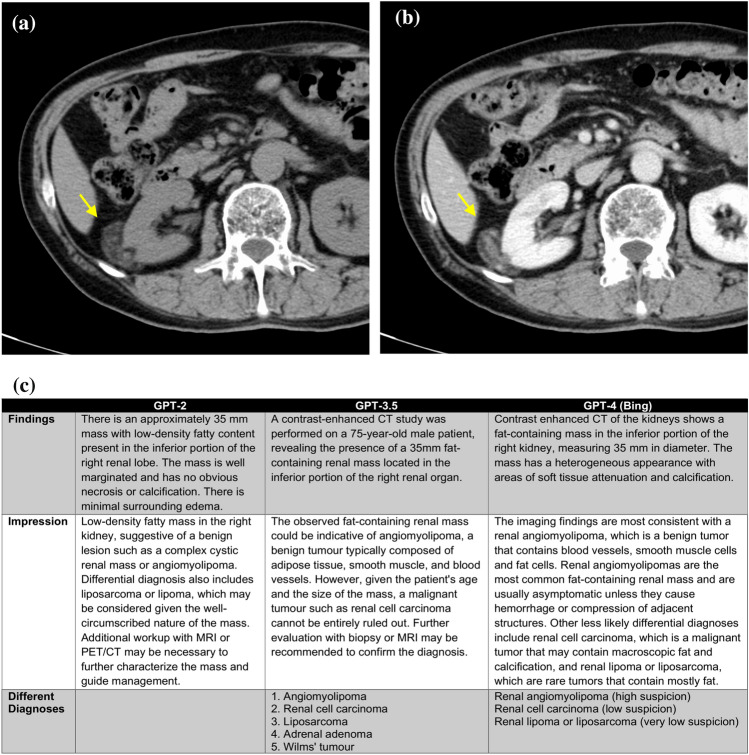
Methods: This retrospective study involved 28 patients who underwent computed tomography (CT) scans and had a diagnosed disease with typical imaging findings. Radiology reports were generated using GPT-2, GPT-3.5, and GPT-4 based on the patient's age, gender, disease site, and imaging findings. We calculated the top-1, top-5 accuracy, and mean average precision (MAP) of differential diagnoses for GPT-2, GPT-3.5, GPT-4, and radiologists. Two board-certified radiologists evaluated the grammar and readability, image findings, impression, differential diagnosis, and overall quality of all reports using a 4-point scale.
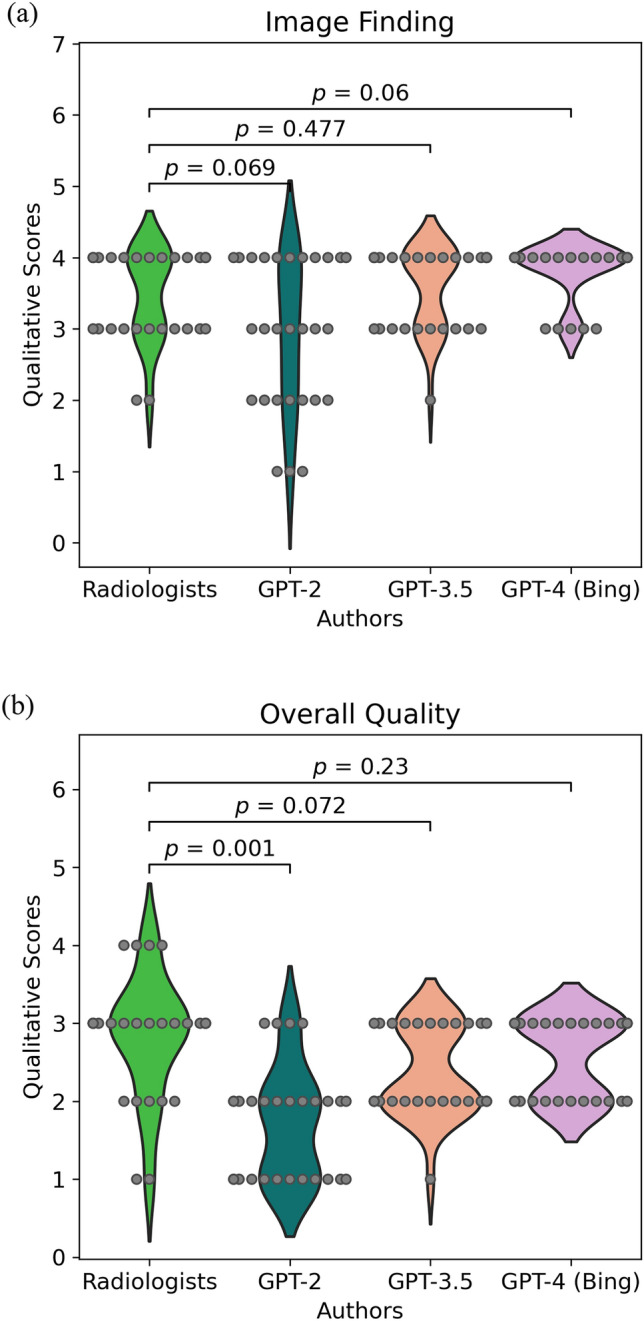
Results: Top-1 and Top-5 accuracies for the different diagnoses were highest for radiologists, followed by GPT-4, GPT-3.5, and GPT-2, in that order (Top-1: 1.00, 0.54, 0.54, and 0.21, respectively; Top-5: 1.00, 0.96, 0.89, and 0.54, respectively). There were no significant differences in qualitative scores about grammar and readability, image findings, and overall quality between radiologists and GPT-3.5 or GPT-4 (p > 0.05). However, qualitative scores of the GPT series in impression and differential diagnosis scores were significantly lower than those of radiologists (p < 0.05).
Conclusions: Our preliminary study suggests that GPT-3.5 and GPT-4 have the possibility to generate radiology reports with high readability and reasonable image findings from very short keywords; however, concerns persist regarding the accuracy of impressions and differential diagnoses, thereby requiring verification by radiologists.
Keywords: Computed tomography; Deep learning; Generative pre-trained transformer; Large language model; Radiology report.
© 2023. The Author(s).
Conflict of interest statement
Toshinori Hirai has received research support from Canon Medical Systems.
Figures


References
-
- Kitahara H, Nagatani Y, Otani H, Nakayama R, Kida Y, Sonoda A, et al. A novel strategy to develop deep learning for image super-resolution using original ultra-high-resolution computed tomography images of lung as training dataset. Jpn J Radiol. 2022;40:38–47. doi: 10.1007/s11604-021-01184-8. - DOI - PMC - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Research Materials
