

Assessing the Impact of Context Inference Error and Partial Observability on RL Methods for Just-In-Time Adaptive Interventions
- PMID: 37724310
- PMCID: PMC10506656
Assessing the Impact of Context Inference Error and Partial Observability on RL Methods for Just-In-Time Adaptive Interventions
Abstract
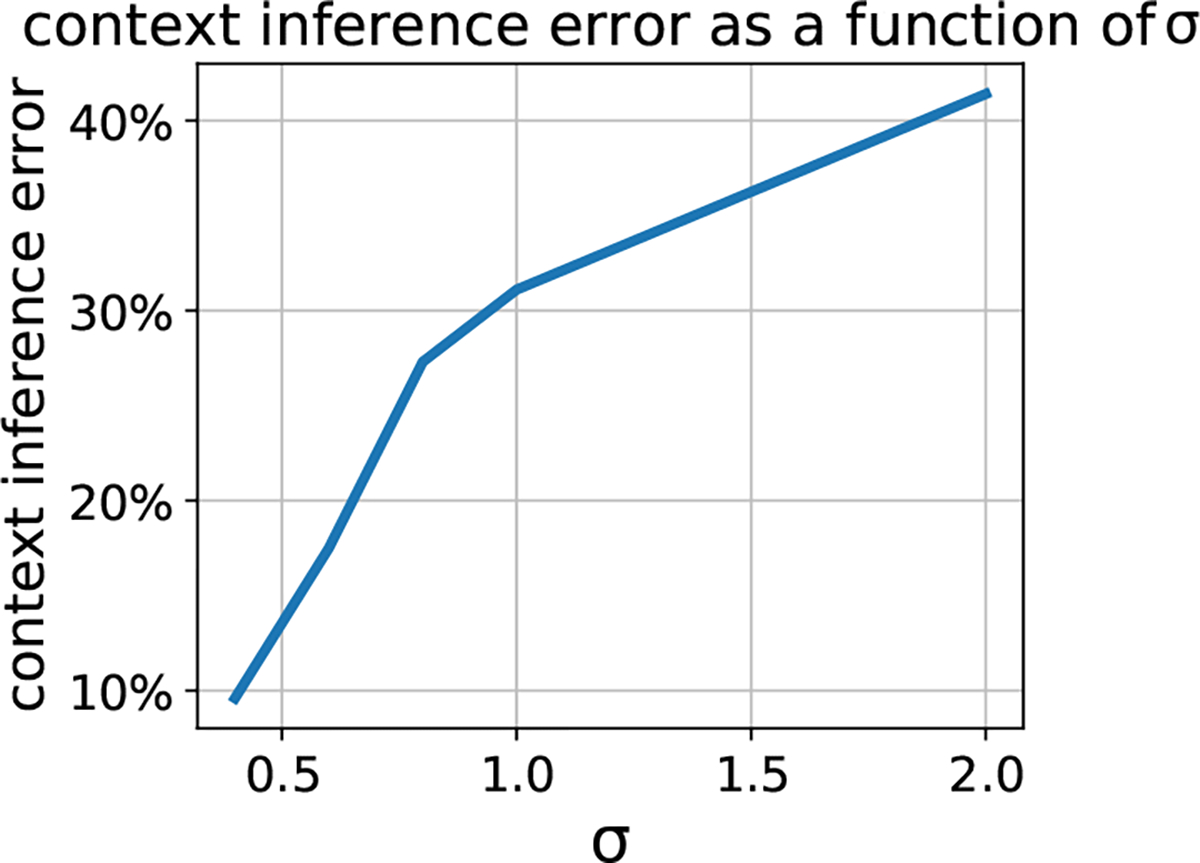
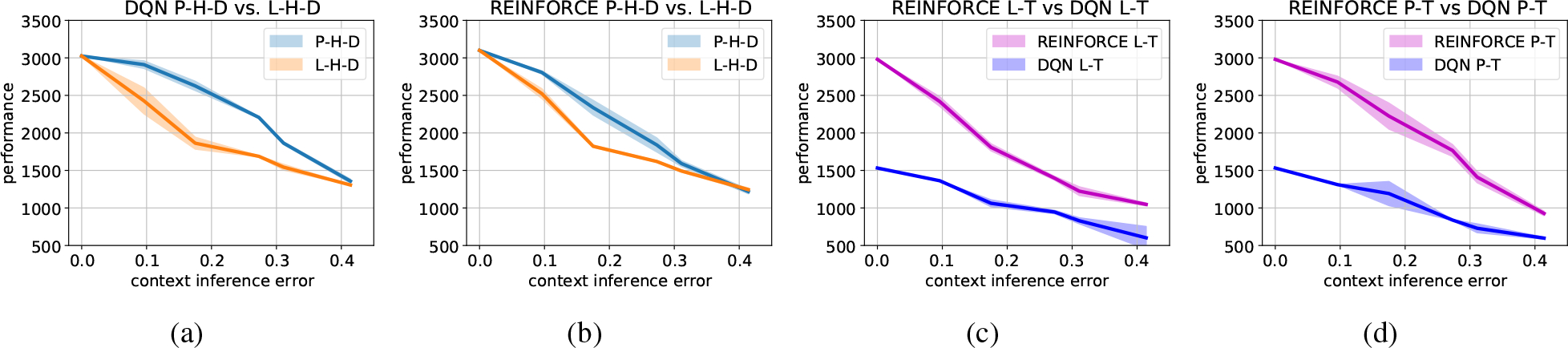
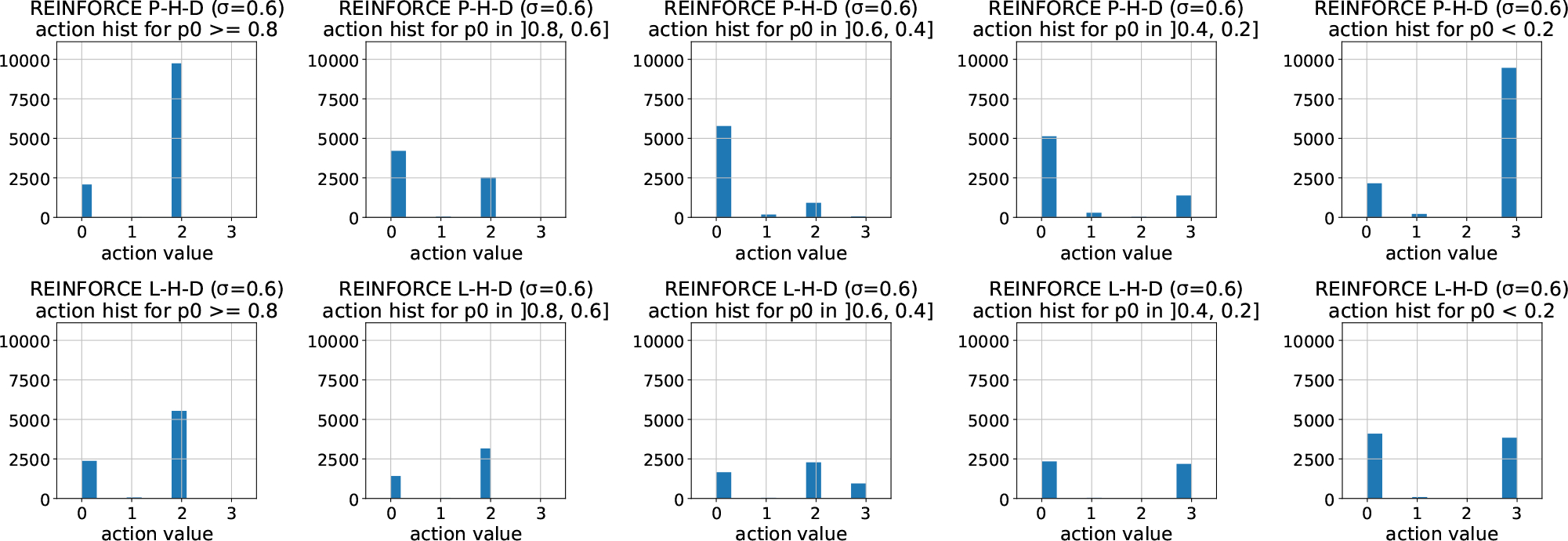
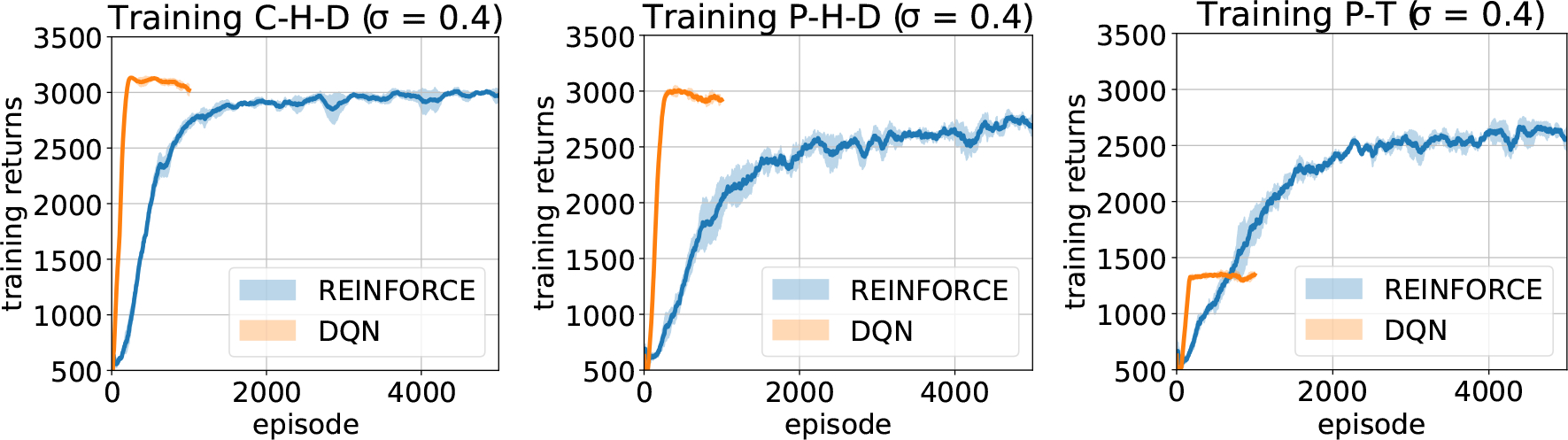
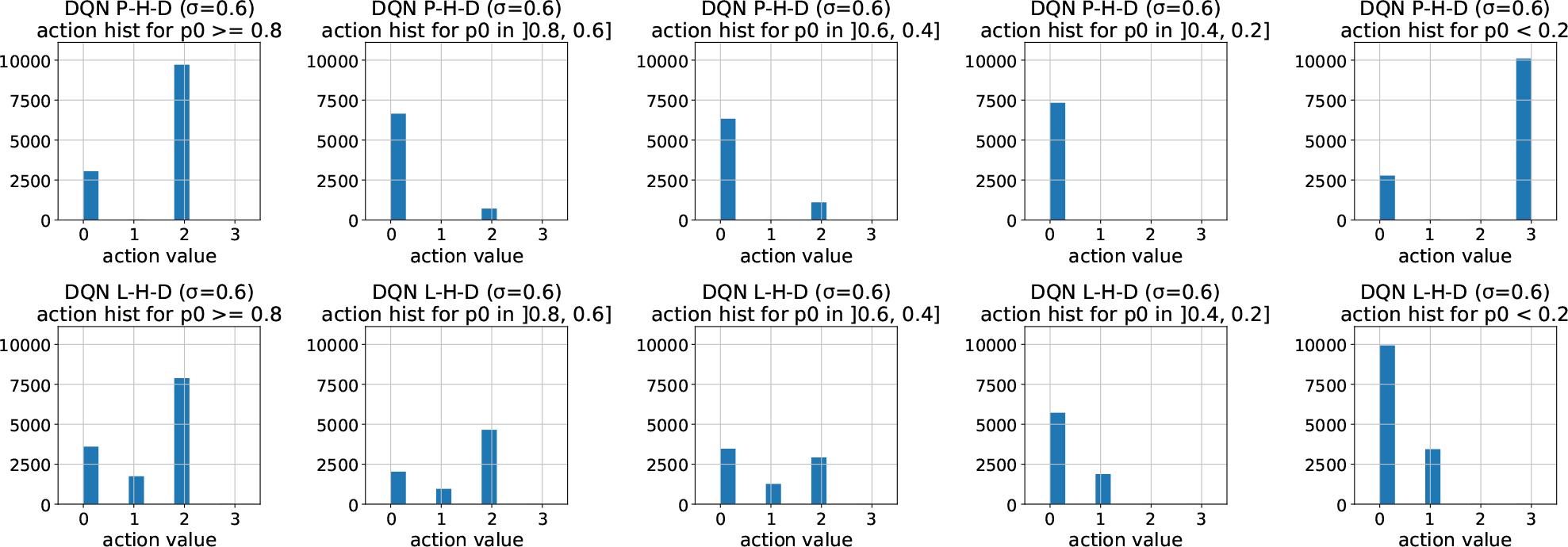
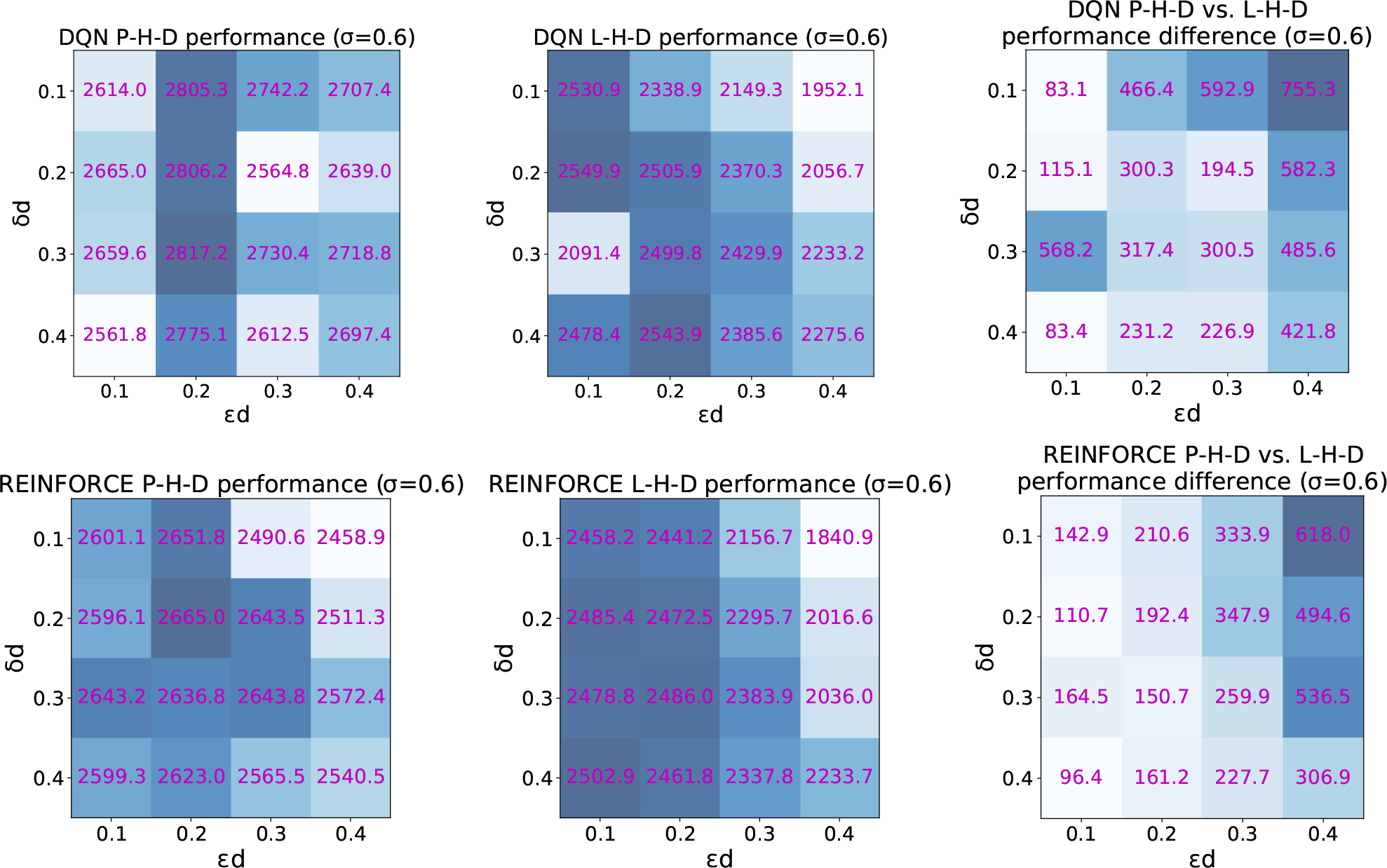
Just-in-Time Adaptive Interventions (JITAIs) are a class of personalized health interventions developed within the behavioral science community. JITAIs aim to provide the right type and amount of support by iteratively selecting a sequence of intervention options from a pre-defined set of components in response to each individual's time varying state. In this work, we explore the application of reinforcement learning methods to the problem of learning intervention option selection policies. We study the effect of context inference error and partial observability on the ability to learn effective policies. Our results show that the propagation of uncertainty from context inferences is critical to improving intervention efficacy as context uncertainty increases, while policy gradient algorithms can provide remarkable robustness to partially observed behavioral state information.
Keywords: Reinforcement learning; adaptive interventions; context inference; empirical evaluation; mobile health; partial observability.
Figures
Similar articles
-
Personalized HeartSteps: A Reinforcement Learning Algorithm for Optimizing Physical Activity.Proc ACM Interact Mob Wearable Ubiquitous Technol. 2020 Mar;4(1):18. doi: 10.1145/3381007. Proc ACM Interact Mob Wearable Ubiquitous Technol. 2020. PMID: 34527853 Free PMC article.
-
Just-in-Time Adaptive Interventions (JITAIs) in Mobile Health: Key Components and Design Principles for Ongoing Health Behavior Support.Ann Behav Med. 2018 May 18;52(6):446-462. doi: 10.1007/s12160-016-9830-8. Ann Behav Med. 2018. PMID: 27663578 Free PMC article.
-
Modeling the effects of environmental and perceptual uncertainty using deterministic reinforcement learning dynamics with partial observability.Phys Rev E. 2022 Mar;105(3-1):034409. doi: 10.1103/PhysRevE.105.034409. Phys Rev E. 2022. PMID: 35428165
-
Just-in-Time Adaptive Mechanisms of Popular Mobile Apps for Individuals With Depression: Systematic App Search and Literature Review.J Med Internet Res. 2021 Sep 28;23(9):e29412. doi: 10.2196/29412. J Med Internet Res. 2021. PMID: 34309569 Free PMC article.
-
Causal evidence in health decision making: methodological approaches of causal inference and health decision science.Ger Med Sci. 2022 Dec 21;20:Doc12. doi: 10.3205/000314. eCollection 2022. Ger Med Sci. 2022. PMID: 36742460 Free PMC article. Review.
References
-
- Battalio Samuel L, Conroy David E, Dempsey Walter, Liao Peng, Menictas Marianne, Murphy Susan, Nahum-Shani Inbal, Qian Tianchen, Kumar Santosh, and Spring. Bonnie Sense2stop: a micro-randomized trial using wearable sensors to optimize a just-in-time-adaptive stress management intervention for smoking relapse prevention. Contemporary Clinical Trials, 109:106534, 2021. - PMC - PubMed
-
- Bruin Tim de, Kober Jens, Tuyls Karl, and Babuška. Robert The importance of experience replay database composition in deep reinforcement learning. In Deep Reinforcement Learning Workshop, Advances in Neural Information Processing Systems, 2015.
-
- Ertin Emre, Stohs Nathan, Kumar Santosh, Raij Andrew, Al’Absi Mustafa, and Shah. Siddharth Autosense: unobtrusively wearable sensor suite for inferring the onset, causality, and consequences of stress in the field. In Proceedings of the 9th ACM conference on embedded networked sensor systems, pages 274–287, 2011.
-
- Gönül Suat, Namlı Tuncay, Coşar Ahmet, and Toroslu İsmail Hakkı. A reinforcement learning based algorithm for personalization of digital, just-in-time, adaptive interventions. Artificial Intelligence in Medicine, 115:102062, 2021. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources