

This is a preprint.
Deep Learning Model for Tumor Type Prediction using Targeted Clinical Genomic Sequencing Data
- PMID: 37732244
- PMCID: PMC10508812
- DOI: 10.1101/2023.09.08.23295131
Deep Learning Model for Tumor Type Prediction using Targeted Clinical Genomic Sequencing Data
Update in
-
Deep-Learning Model for Tumor-Type Prediction Using Targeted Clinical Genomic Sequencing Data.Cancer Discov. 2024 Jun 3;14(6):1064-1081. doi: 10.1158/2159-8290.CD-23-0996. Cancer Discov. 2024. PMID: 38416134 Free PMC article.
Abstract
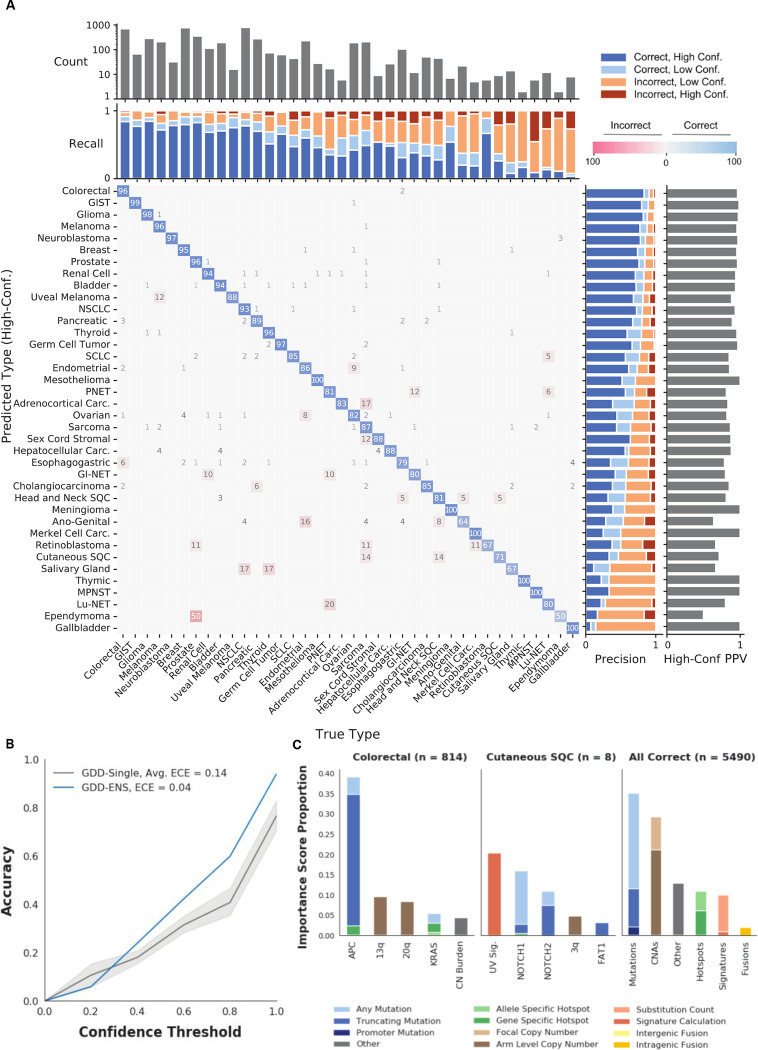
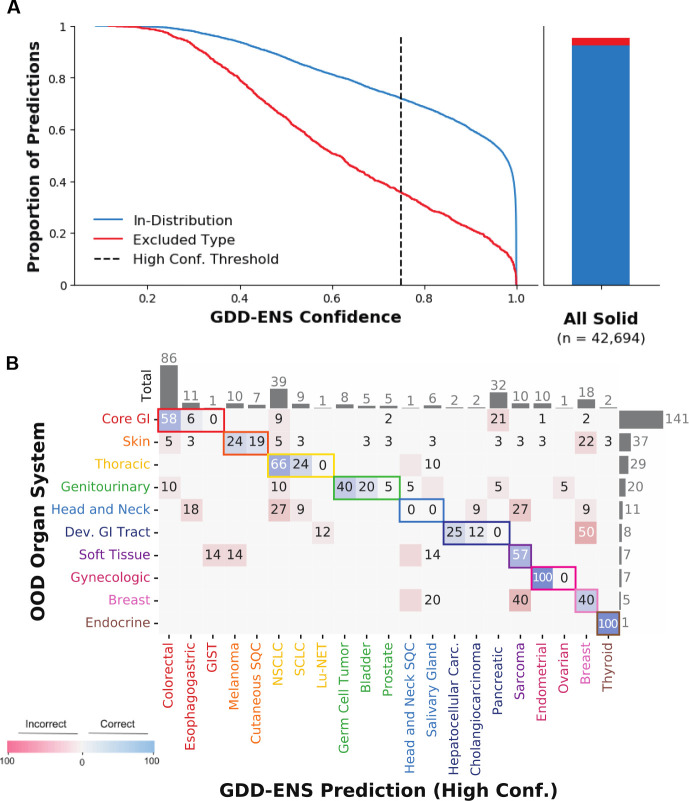
Tumor type guides clinical treatment decisions in cancer, but histology-based diagnosis remains challenging. Genomic alterations are highly diagnostic of tumor type, and tumor type classifiers trained on genomic features have been explored, but the most accurate methods are not clinically feasible, relying on features derived from whole genome sequencing (WGS), or predicting across limited cancer types. We use genomic features from a dataset of 39,787 solid tumors sequenced using a clinical targeted cancer gene panel to develop Genome-Derived-Diagnosis Ensemble (GDD-ENS): a hyperparameter ensemble for classifying tumor type using deep neural networks. GDD-ENS achieves 93% accuracy for high-confidence predictions across 38 cancer types, rivalling performance of WGS-based methods. GDD-ENS can also guide diagnoses on rare type and cancers of unknown primary, and incorporate patient-specific clinical information for improved predictions. Overall, integrating GDD-ENS into prospective clinical sequencing workflows has enabled clinically-relevant tumor type predictions to guide treatment decisions in real time.
Conflict of interest statement
Conflict of interest: M.B. reported receiving personal fees from Eli Lilly, AstraZeneca and Paige.AI all unrelated to this study. All other authors declared that they have no competing interests.
Figures



References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources