

APPRAISE-AI Tool for Quantitative Evaluation of AI Studies for Clinical Decision Support
- PMID: 37747733
- PMCID: PMC10520738
- DOI: 10.1001/jamanetworkopen.2023.35377
APPRAISE-AI Tool for Quantitative Evaluation of AI Studies for Clinical Decision Support
Abstract
Importance: Artificial intelligence (AI) has gained considerable attention in health care, yet concerns have been raised around appropriate methods and fairness. Current AI reporting guidelines do not provide a means of quantifying overall quality of AI research, limiting their ability to compare models addressing the same clinical question.
Objective: To develop a tool (APPRAISE-AI) to evaluate the methodological and reporting quality of AI prediction models for clinical decision support.
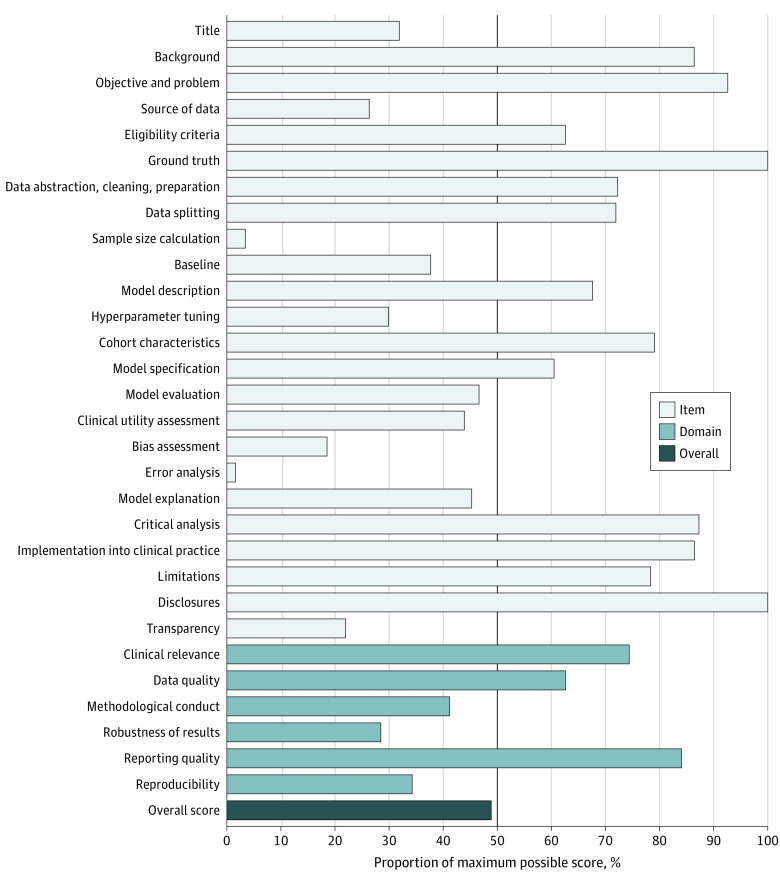
Design, setting, and participants: This quality improvement study evaluated AI studies in the model development, silent, and clinical trial phases using the APPRAISE-AI tool, a quantitative method for evaluating quality of AI studies across 6 domains: clinical relevance, data quality, methodological conduct, robustness of results, reporting quality, and reproducibility. These domains included 24 items with a maximum overall score of 100 points. Points were assigned to each item, with higher points indicating stronger methodological or reporting quality. The tool was applied to a systematic review on machine learning to estimate sepsis that included articles published until September 13, 2019. Data analysis was performed from September to December 2022.
Main outcomes and measures: The primary outcomes were interrater and intrarater reliability and the correlation between APPRAISE-AI scores and expert scores, 3-year citation rate, number of Quality Assessment of Diagnostic Accuracy Studies (QUADAS-2) low risk-of-bias domains, and overall adherence to the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD) statement.
Results: A total of 28 studies were included. Overall APPRAISE-AI scores ranged from 33 (low quality) to 67 (high quality). Most studies were moderate quality. The 5 lowest scoring items included source of data, sample size calculation, bias assessment, error analysis, and transparency. Overall APPRAISE-AI scores were associated with expert scores (Spearman ρ, 0.82; 95% CI, 0.64-0.91; P < .001), 3-year citation rate (Spearman ρ, 0.69; 95% CI, 0.43-0.85; P < .001), number of QUADAS-2 low risk-of-bias domains (Spearman ρ, 0.56; 95% CI, 0.24-0.77; P = .002), and adherence to the TRIPOD statement (Spearman ρ, 0.87; 95% CI, 0.73-0.94; P < .001). Intraclass correlation coefficient ranges for interrater and intrarater reliability were 0.74 to 1.00 for individual items, 0.81 to 0.99 for individual domains, and 0.91 to 0.98 for overall scores.
Conclusions and relevance: In this quality improvement study, APPRAISE-AI demonstrated strong interrater and intrarater reliability and correlated well with several study quality measures. This tool may provide a quantitative approach for investigators, reviewers, editors, and funding organizations to compare the research quality across AI studies for clinical decision support.
Conflict of interest statement
Figures
References
-
- Collins GS, Dhiman P, Andaur Navarro CL, et al. . Protocol for development of a reporting guideline (TRIPOD-AI) and risk of bias tool (PROBAST-AI) for diagnostic and prognostic prediction model studies based on artificial intelligence. BMJ Open. 2021;11(7):e048008. doi:10.1136/bmjopen-2020-048008 - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
