

Active Vision in Binocular Depth Estimation: A Top-Down Perspective
- PMID: 37754196
- PMCID: PMC10526497
- DOI: 10.3390/biomimetics8050445
Active Vision in Binocular Depth Estimation: A Top-Down Perspective
Abstract
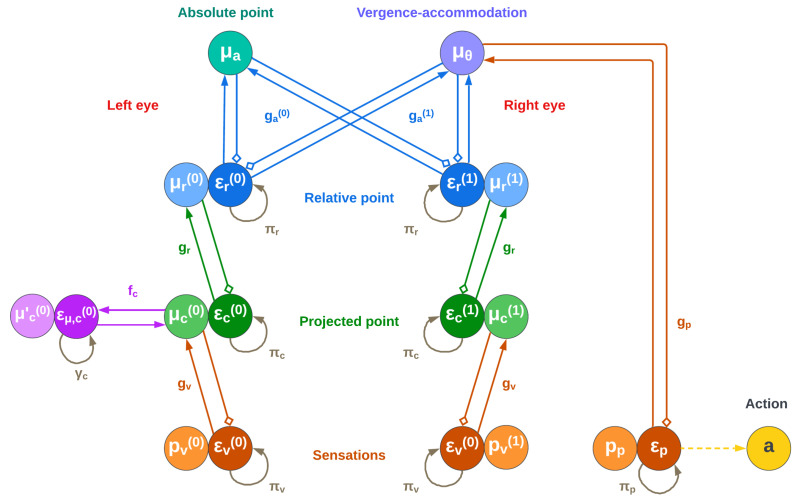
Depth estimation is an ill-posed problem; objects of different shapes or dimensions, even if at different distances, may project to the same image on the retina. Our brain uses several cues for depth estimation, including monocular cues such as motion parallax and binocular cues such as diplopia. However, it remains unclear how the computations required for depth estimation are implemented in biologically plausible ways. State-of-the-art approaches to depth estimation based on deep neural networks implicitly describe the brain as a hierarchical feature detector. Instead, in this paper we propose an alternative approach that casts depth estimation as a problem of active inference. We show that depth can be inferred by inverting a hierarchical generative model that simultaneously predicts the eyes' projections from a 2D belief over an object. Model inversion consists of a series of biologically plausible homogeneous transformations based on Predictive Coding principles. Under the plausible assumption of a nonuniform fovea resolution, depth estimation favors an active vision strategy that fixates the object with the eyes, rendering the depth belief more accurate. This strategy is not realized by first fixating on a target and then estimating the depth; instead, it combines the two processes through action-perception cycles, with a similar mechanism of the saccades during object recognition. The proposed approach requires only local (top-down and bottom-up) message passing, which can be implemented in biologically plausible neural circuits.
Keywords: action-perception cycles; active inference; active vision; depth perception; predictive coding.
Conflict of interest statement
The authors declare no conflict of interest. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Figures






Similar articles
-
The dichoptiscope: an instrument for investigating cues to motion in depth.J Vis. 2013 Dec 2;13(14):1. doi: 10.1167/13.14.1. J Vis. 2013. PMID: 24297775
-
Deep Learning-Based Monocular Depth Estimation Methods-A State-of-the-Art Review.Sensors (Basel). 2020 Apr 16;20(8):2272. doi: 10.3390/s20082272. Sensors (Basel). 2020. PMID: 32316336 Free PMC article. Review.
-
Object Detection and Depth Estimation Approach Based on Deep Convolutional Neural Networks.Sensors (Basel). 2021 Jul 12;21(14):4755. doi: 10.3390/s21144755. Sensors (Basel). 2021. PMID: 34300491 Free PMC article.
-
Monocular cues are superior to binocular cues for size perception when they are in conflict in virtual reality.Cortex. 2023 Sep;166:80-90. doi: 10.1016/j.cortex.2023.05.010. Epub 2023 May 31. Cortex. 2023. PMID: 37343313
-
The neural basis of depth perception from motion parallax.Philos Trans R Soc Lond B Biol Sci. 2016 Jun 19;371(1697):20150256. doi: 10.1098/rstb.2015.0256. Philos Trans R Soc Lond B Biol Sci. 2016. PMID: 27269599 Free PMC article. Review.
Cited by
-
Deep kinematic inference affords efficient and scalable control of bodily movements.Proc Natl Acad Sci U S A. 2023 Dec 19;120(51):e2309058120. doi: 10.1073/pnas.2309058120. Epub 2023 Dec 12. Proc Natl Acad Sci U S A. 2023. PMID: 38085784 Free PMC article.
-
Embodied decisions as active inference.PLoS Comput Biol. 2025 Jun 18;21(6):e1013180. doi: 10.1371/journal.pcbi.1013180. eCollection 2025 Jun. PLoS Comput Biol. 2025. PMID: 40531985 Free PMC article.
-
Deep Hybrid Models: Infer and Plan in a Dynamic World.Entropy (Basel). 2025 May 27;27(6):570. doi: 10.3390/e27060570. Entropy (Basel). 2025. PMID: 40566157 Free PMC article.
-
Pose Estimation of a Cobot Implemented on a Small AI-Powered Computing System and a Stereo Camera for Precision Evaluation.Biomimetics (Basel). 2024 Oct 9;9(10):610. doi: 10.3390/biomimetics9100610. Biomimetics (Basel). 2024. PMID: 39451816 Free PMC article.
References
Grants and funding
LinkOut - more resources
Full Text Sources
