

The location and development of Replicon Cluster Domains in early replicating DNA
- PMID: 37766844
- PMCID: PMC10521077
- DOI: 10.12688/wellcomeopenres.18742.2
The location and development of Replicon Cluster Domains in early replicating DNA
Abstract
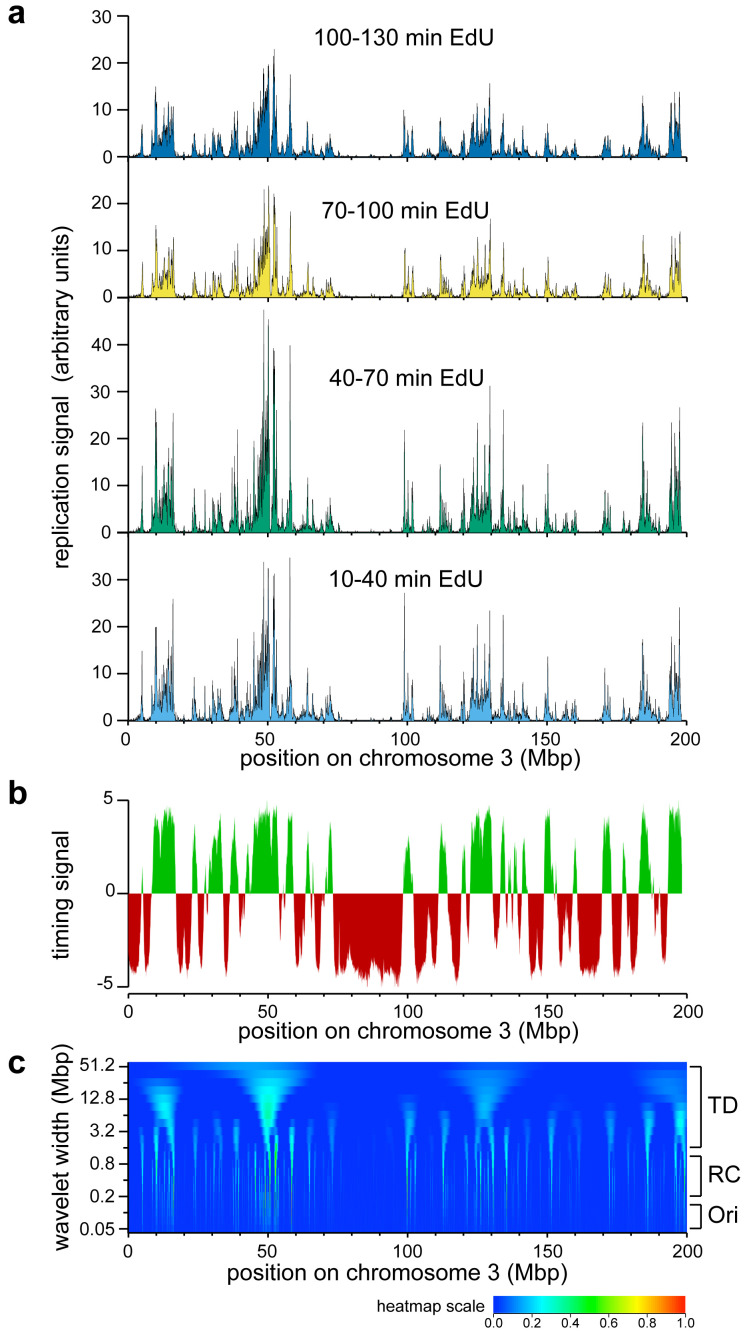
Background: It has been known for many years that in metazoan cells, replication origins are organised into clusters where origins within each cluster fire near-synchronously. Despite clusters being a fundamental organising principle of metazoan DNA replication, the genomic location of origin clusters has not been documented. Methods: We synchronised human U2OS by thymidine block and release followed by L-mimosine block and release to create a population of cells progressing into S phase with a high degree of synchrony. At different times after release into S phase, cells were pulsed with EdU; the EdU-labelled DNA was then pulled down, sequenced and mapped onto the human genome. Results: The early replicating DNA showed features at a range of scales. Wavelet analysis showed that the major feature of the early replicating DNA was at a size of 500 kb, consistent with clusters of replication origins. Over the first two hours of S phase, these Replicon Cluster Domains broadened in width, consistent with their being enlarged by the progression of replication forks at their outer boundaries. The total replication signal associated with each Replicon Cluster Domain varied considerably, and this variation was reproducible and conserved over time. We provide evidence that this variability in replication signal was at least in part caused by Replicon Cluster Domains being activated at different times in different cells in the population. We also provide evidence that adjacent clusters had a statistical preference for being activated in sequence across a group, consistent with the 'domino' model of replication focus activation order observed by microscopy. Conclusions: We show that early replicating DNA is organised into Replicon Cluster Domains that behave as expected of replicon clusters observed by DNA fibre analysis. The coordinated activation of different Replicon Cluster Domains can generate the replication timing programme by which the genome is duplicated.
Keywords: DNA replication; S phase; cell cycle; replication timing; replicon clusters.
Copyright: © 2023 da Costa-Nunes JA et al.
Conflict of interest statement
No competing interests were disclosed.
Figures









Similar articles
-
Clusters, factories and domains: The complex structure of S-phase comes into focus.Cell Cycle. 2010 Aug 15;9(16):3218-26. doi: 10.4161/cc.9.16.12644. Epub 2010 Aug 11. Cell Cycle. 2010. PMID: 20724827 Free PMC article.
-
Evidence for sequential and increasing activation of replication origins along replication timing gradients in the human genome.PLoS Comput Biol. 2011 Dec;7(12):e1002322. doi: 10.1371/journal.pcbi.1002322. Epub 2011 Dec 29. PLoS Comput Biol. 2011. PMID: 22219720 Free PMC article.
-
Replicon clusters are stable units of chromosome structure: evidence that nuclear organization contributes to the efficient activation and propagation of S phase in human cells.J Cell Biol. 1998 Mar 23;140(6):1285-95. doi: 10.1083/jcb.140.6.1285. J Cell Biol. 1998. PMID: 9508763 Free PMC article.
-
[Is the replicon model applicable to higher eukaryotes?].C R Acad Sci III. 1998 Dec;321(12):961-78. doi: 10.1016/s0764-4469(99)80052-3. C R Acad Sci III. 1998. PMID: 9929779 Review. French.
-
Replication Domains: Genome Compartmentalization into Functional Replication Units.Adv Exp Med Biol. 2017;1042:229-257. doi: 10.1007/978-981-10-6955-0_11. Adv Exp Med Biol. 2017. PMID: 29357061 Review.
Cited by
-
Mechanisms of tandem duplication in the cancer genome.DNA Repair (Amst). 2025 Jan;145:103802. doi: 10.1016/j.dnarep.2024.103802. Epub 2024 Dec 25. DNA Repair (Amst). 2025. PMID: 39742573 Review.
References
Grants and funding
LinkOut - more resources
Full Text Sources
