

Learning single-cell perturbation responses using neural optimal transport
- PMID: 37770709
- PMCID: PMC10630137
- DOI: 10.1038/s41592-023-01969-x
Learning single-cell perturbation responses using neural optimal transport
Erratum in
-
Author Correction: Learning single-cell perturbation responses using neural optimal transport.Nat Methods. 2023 Nov;20(11):1830. doi: 10.1038/s41592-023-02073-w. Nat Methods. 2023. PMID: 37903912 Free PMC article. No abstract available.
Abstract
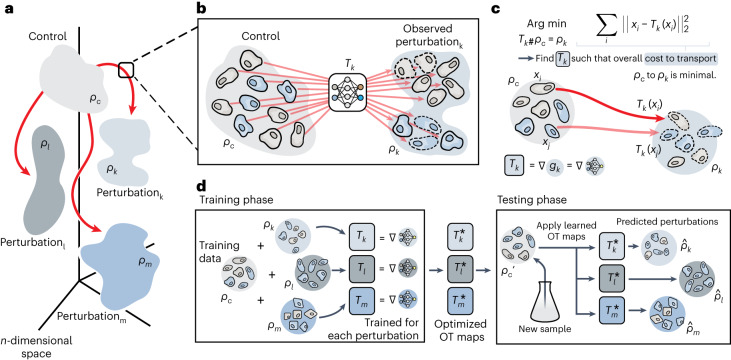
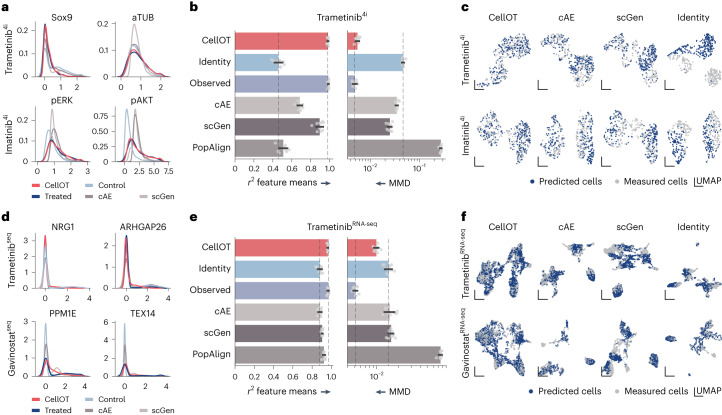
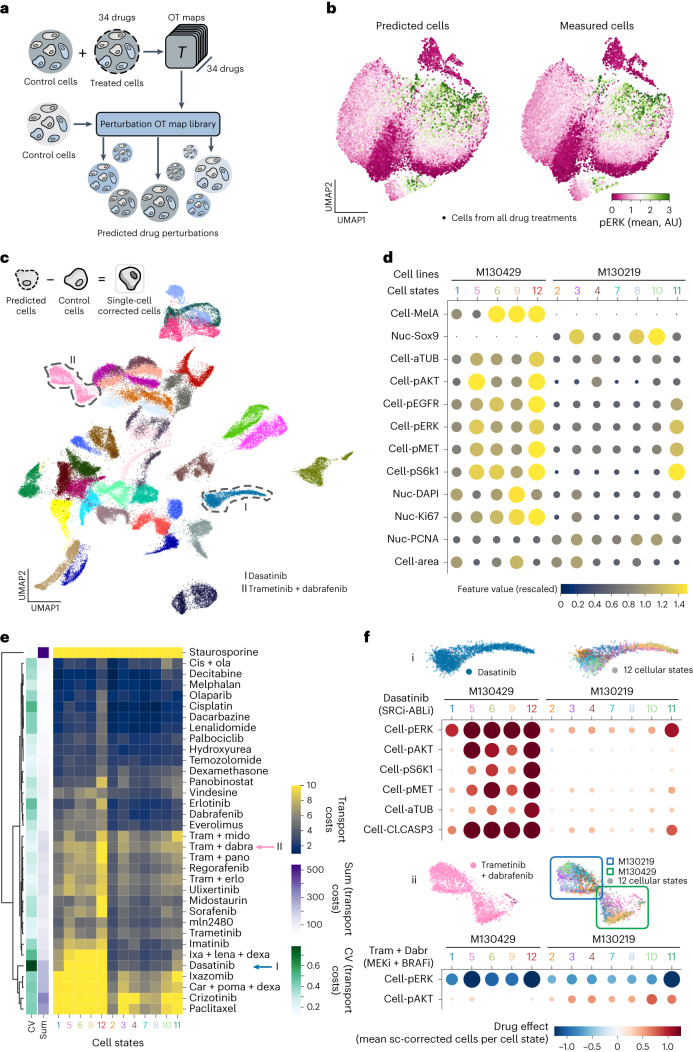
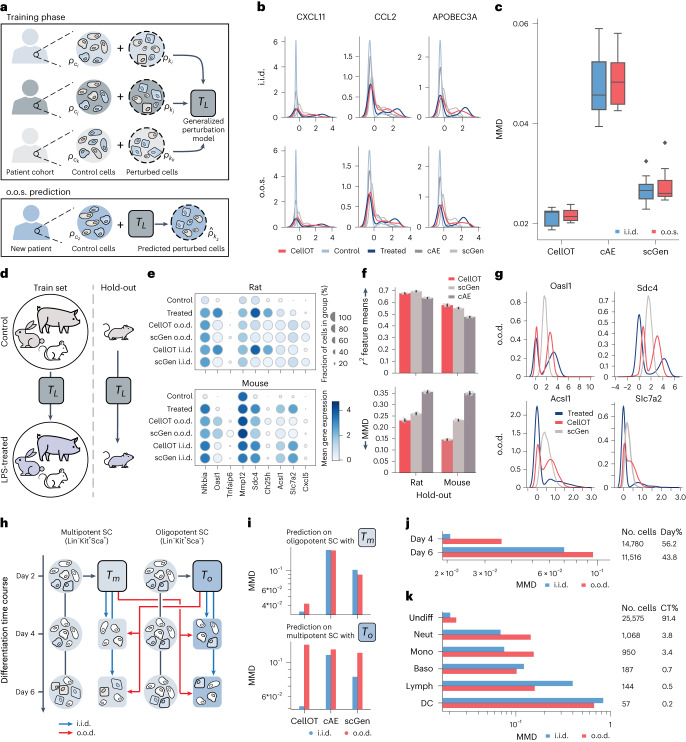
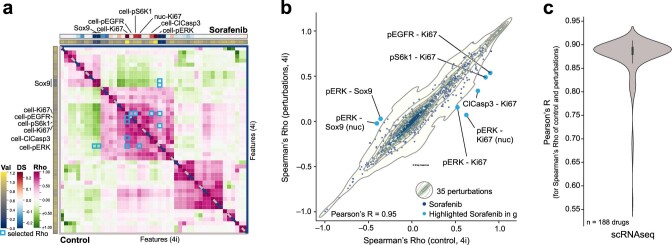
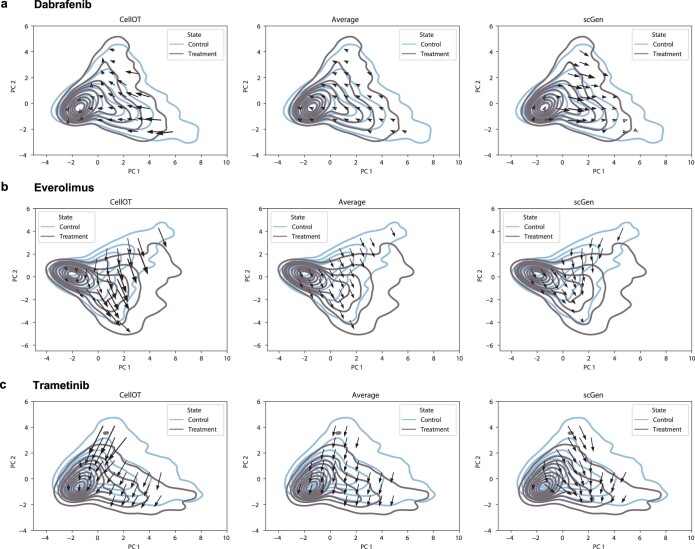
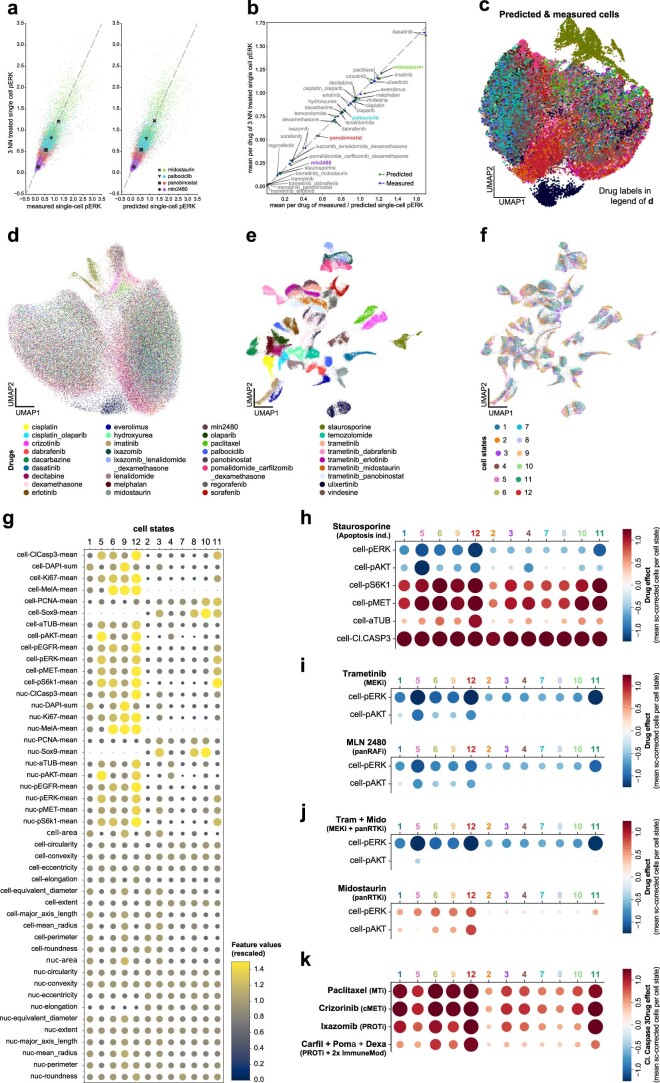
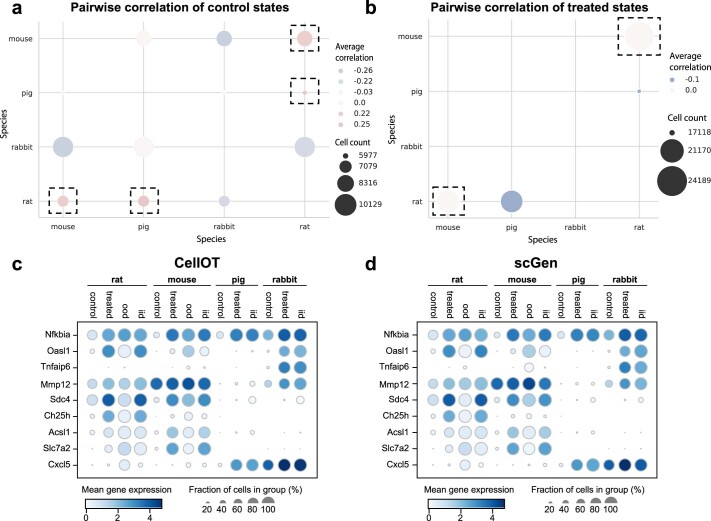
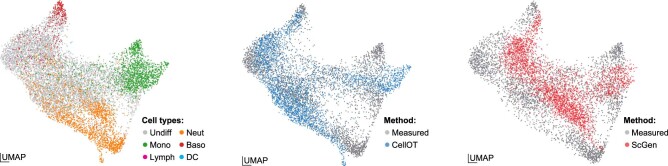
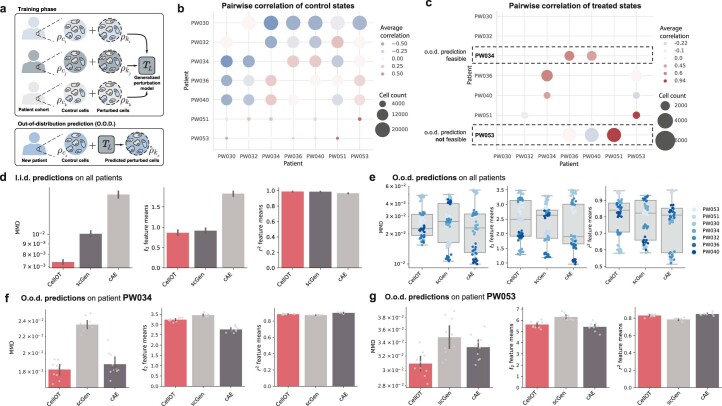
Understanding and predicting molecular responses in single cells upon chemical, genetic or mechanical perturbations is a core question in biology. Obtaining single-cell measurements typically requires the cells to be destroyed. This makes learning heterogeneous perturbation responses challenging as we only observe unpaired distributions of perturbed or non-perturbed cells. Here we leverage the theory of optimal transport and the recent advent of input convex neural architectures to present CellOT, a framework for learning the response of individual cells to a given perturbation by mapping these unpaired distributions. CellOT outperforms current methods at predicting single-cell drug responses, as profiled by scRNA-seq and a multiplexed protein-imaging technology. Further, we illustrate that CellOT generalizes well on unseen settings by (1) predicting the scRNA-seq responses of holdout patients with lupus exposed to interferon-β and patients with glioblastoma to panobinostat; (2) inferring lipopolysaccharide responses across different species; and (3) modeling the hematopoietic developmental trajectories of different subpopulations.
© 2023. The Author(s).
Conflict of interest statement
G.G. and L.P. have filed a patent on the 4i technology (patent WO2019207004A1). The other authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Grants and funding
- ERC-2019-AdG-885579/EC | EU Framework Programme for Research and Innovation H2020 | H2020 Priority Excellent Science | H2020 European Research Council (H2020 Excellent Science - European Research Council)
- 310030_192622/Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung (Swiss National Science Foundation)
LinkOut - more resources
Full Text Sources
Other Literature Sources
