

Comparing ChatGPT and GPT-4 performance in USMLE soft skill assessments
- PMID: 37779171
- PMCID: PMC10543445
- DOI: 10.1038/s41598-023-43436-9
Comparing ChatGPT and GPT-4 performance in USMLE soft skill assessments
Abstract
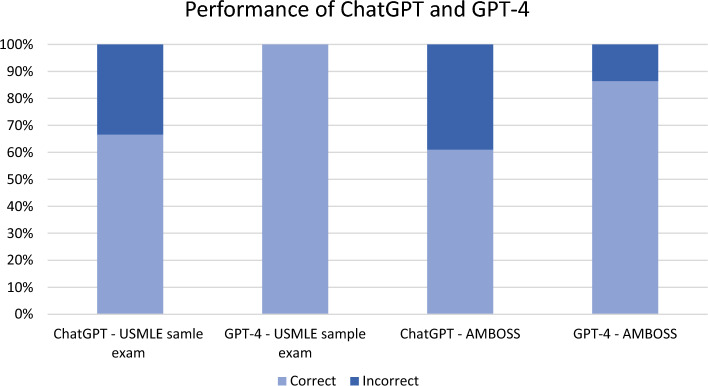
The United States Medical Licensing Examination (USMLE) has been a subject of performance study for artificial intelligence (AI) models. However, their performance on questions involving USMLE soft skills remains unexplored. This study aimed to evaluate ChatGPT and GPT-4 on USMLE questions involving communication skills, ethics, empathy, and professionalism. We used 80 USMLE-style questions involving soft skills, taken from the USMLE website and the AMBOSS question bank. A follow-up query was used to assess the models' consistency. The performance of the AI models was compared to that of previous AMBOSS users. GPT-4 outperformed ChatGPT, correctly answering 90% compared to ChatGPT's 62.5%. GPT-4 showed more confidence, not revising any responses, while ChatGPT modified its original answers 82.5% of the time. The performance of GPT-4 was higher than that of AMBOSS's past users. Both AI models, notably GPT-4, showed capacity for empathy, indicating AI's potential to meet the complex interpersonal, ethical, and professional demands intrinsic to the practice of medicine.
© 2023. Springer Nature Limited.
Conflict of interest statement
The authors declare no competing interests.
Figures
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
