

Medical Image Retrieval via Nearest Neighbor Search on Pre-trained Image Features
- PMID: 37780058
- PMCID: PMC10540469
- DOI: 10.1016/j.knosys.2023.110907
Medical Image Retrieval via Nearest Neighbor Search on Pre-trained Image Features
Abstract
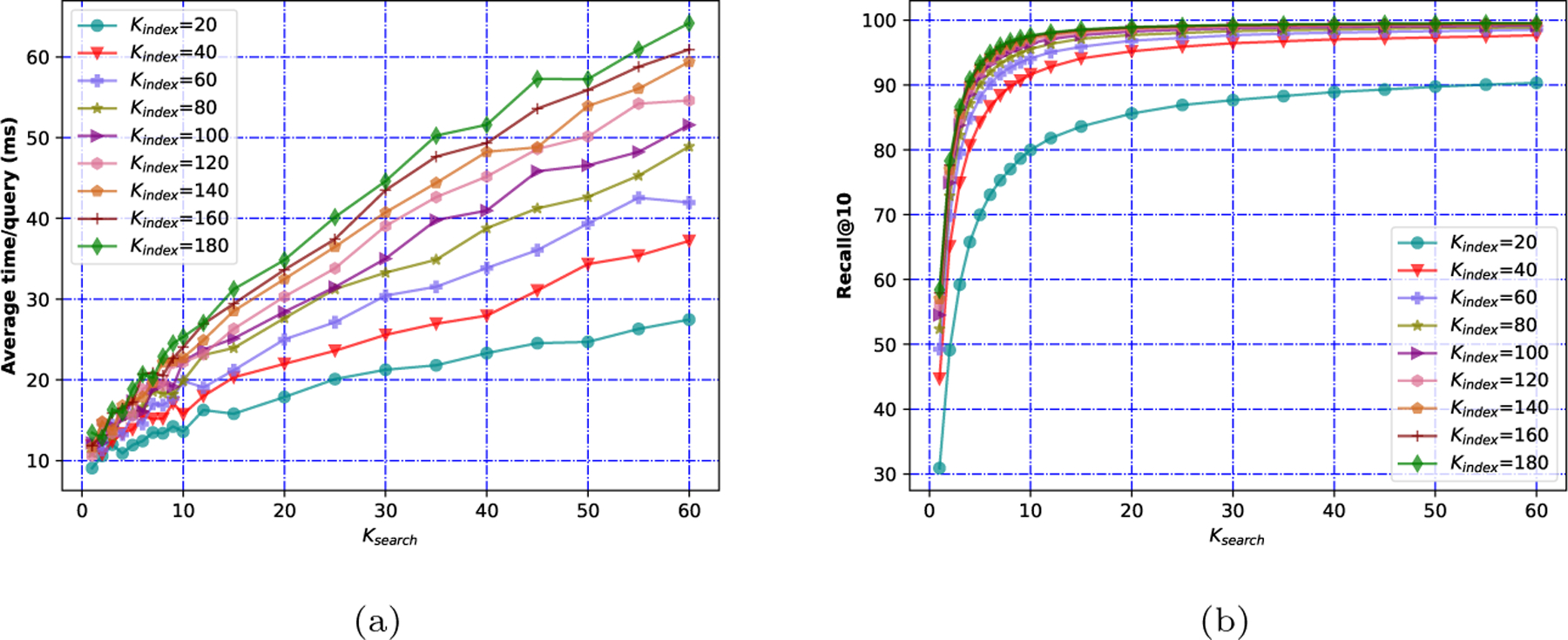
Nearest neighbor search, also known as NNS, is a technique used to locate the points in a high-dimensional space closest to a given query point. This technique has multiple applications in medicine, such as searching large medical imaging databases, disease classification, and diagnosis. However, when the number of points is significantly large, the brute-force approach for finding the nearest neighbor becomes computationally infeasible. Therefore, various approaches have been developed to make the search faster and more efficient to support the applications. With a focus on medical imaging, this paper proposes DenseLinkSearch (DLS), an effective and efficient algorithm that searches and retrieves the relevant images from heterogeneous sources of medical images. Towards this, given a medical database, the proposed algorithm builds an index that consists of pre-computed links of each point in the database. The search algorithm utilizes the index to efficiently traverse the database in search of the nearest neighbor. We also explore the role of medical image feature representation in content-based medical image retrieval tasks. We propose a Transformer-based feature representation technique that outperformed the existing pre-trained Transformer-based approaches on benchmark medical image retrieval datasets. We extensively tested the proposed NNS approach and compared the performance with state-of-the-art NNS approaches on benchmark datasets and our created medical image datasets. The proposed approach outperformed the existing approaches in terms of retrieving accurate neighbors and retrieval speed. In comparison to the existing approximate NNS approaches, our proposed DLS approach outperformed them in terms of lower average time per query and ≥ 99% on 11 out of 13 benchmark datasets. We also found that the proposed medical feature representation approach is better for representing medical images compared to the existing pre-trained image models. The proposed feature extraction strategy obtained an improvement of 9.37%, 7.0%, and 13.33% in terms of P@5, P@10, and P@20, respectively, in comparison to the best-performing pre-trained image model. The source code and datasets of our experiments are available at https://github.com/deepaknlp/DLS.
Keywords: Content-based image retrieval; Image feature representation; Indexing; Nearest neighbor search; Searching in High Dimensions.
Conflict of interest statement
Declarations of interest The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures

 . The algorithm initializes a heap data structure of size and a list. The heap holds links to the nearest vectors known so far. The list holds links to other vectors that consider this vector near. The top link in a heap defines the neighborhood radius, also known as the near distance. Subfigure (b) represents a snapshot of the index after the data point E became a node, and its heap and list are updated based on distances between the node and its neighbors. The existing nodes and edges are shown as
. The algorithm initializes a heap data structure of size and a list. The heap holds links to the nearest vectors known so far. The list holds links to other vectors that consider this vector near. The top link in a heap defines the neighborhood radius, also known as the near distance. Subfigure (b) represents a snapshot of the index after the data point E became a node, and its heap and list are updated based on distances between the node and its neighbors. The existing nodes and edges are shown as  respectively. The recently processed node E and added edges are shown as
respectively. The recently processed node E and added edges are shown as  respectively. Subfigure (c) demonstrates each node’s heap and list items and the index graph with nodes and edges after the index is built. The created links and distances are shown in subfigure (d). The final index contains the descend and spread links for each node in the dataset. The descend links contain the endpoints vertices and distances from the heap just before the vertex becomes a node while building the indexes. Similarly, the spread links of a given vertex store the endpoints vertices and distances from the heap and list once the algorithm ends.
respectively. Subfigure (c) demonstrates each node’s heap and list items and the index graph with nodes and edges after the index is built. The created links and distances are shown in subfigure (d). The final index contains the descend and spread links for each node in the dataset. The descend links contain the endpoints vertices and distances from the heap just before the vertex becomes a node while building the indexes. Similarly, the spread links of a given vertex store the endpoints vertices and distances from the heap and list once the algorithm ends.

 and the pre-built index with the links. In the subfigure (a), the search starts with a random node (here
and the pre-built index with the links. In the subfigure (a), the search starts with a random node (here  ) and compute the distance between the query and the node . In each step of the Descend stage, the algorithm keeps track of the closest vector to the query. Also, a heap of size is maintained to track nearest neighbors throughout the search process. Initially, the node is the nearest neighbor to the query, therefore, the node is pushed into the heap . In the subfigure (b), the distance between the query vector and the links (
) and compute the distance between the query and the node . In each step of the Descend stage, the algorithm keeps track of the closest vector to the query. Also, a heap of size is maintained to track nearest neighbors throughout the search process. Initially, the node is the nearest neighbor to the query, therefore, the node is pushed into the heap . In the subfigure (b), the distance between the query vector and the links ( ,
,  , and
, and  ) of are computed, and the closest vector is updated accordingly. The subfigure (c) shows that the closest node is chosen for the next stage of the Descend. Since the distances (23 and 32) between the query and the links of the node
) of are computed, and the closest vector is updated accordingly. The subfigure (c) shows that the closest node is chosen for the next stage of the Descend. Since the distances (23 and 32) between the query and the links of the node  are greater than distance (18) between query and node , the search switches to the Spread stage. The Spread stage is demonstrated in subfigure (d), where we aim to compute the distance between the query and the links (
are greater than distance (18) between query and node , the search switches to the Spread stage. The Spread stage is demonstrated in subfigure (d), where we aim to compute the distance between the query and the links ( and
and  ) of node , those have already been computed. At the end of the algorithm, the nearest neighbors can be found in the heap .
) of node , those have already been computed. At the end of the algorithm, the nearest neighbors can be found in the heap .






References
-
- Almalawi AM, Fahad A, Tari Z, Cheema MA, & Khalil I (2015). k nnvwc: An efficient k-nearest neighbors approach based on various-widths clustering. IEEE Transactions on Knowledge and Data Engineering, 28, 68–81.
-
- Antani S, Long LR, & Thoma GR (2004). Content-based image retrieval for large biomedical image archives. In MEDINFO 2004 (pp. 829–833). IOS Press. - PubMed
-
- Antani SK, Deserno TM, Long LR, Güld MO, Neve L, & Thoma GR (2007). Interfacing global and local cbir systems for medical image retrieval. In Bildverarbeitung für die Medizin 2007 (pp. 166–171). Springer.
-
- Ba JL, Kiros JR, & Hinton GE (2016). Layer normalization. arXiv preprint arXiv:1607.06450
-
- Babenko A, & Lempitsky V (2014). The inverted multi-index. IEEE transactions on pattern analysis and machine intelligence, 37, 1247–1260. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources