

This is a preprint.
Neural Data Transformer 2: Multi-context Pretraining for Neural Spiking Activity
- PMID: 37781630
- PMCID: PMC10541112
- DOI: 10.1101/2023.09.18.558113
Neural Data Transformer 2: Multi-context Pretraining for Neural Spiking Activity
Abstract
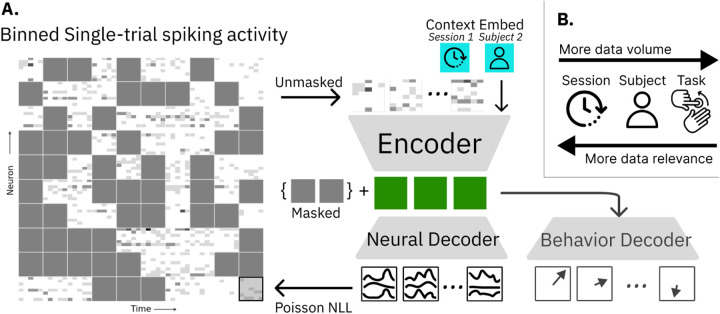
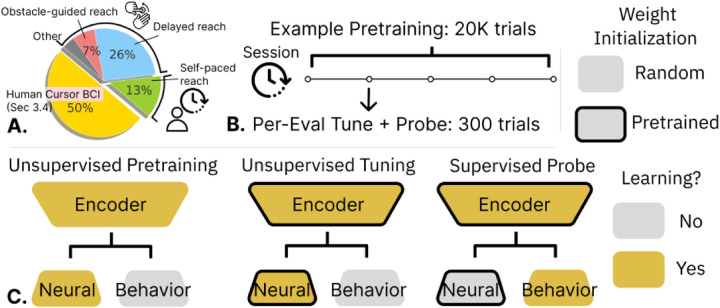
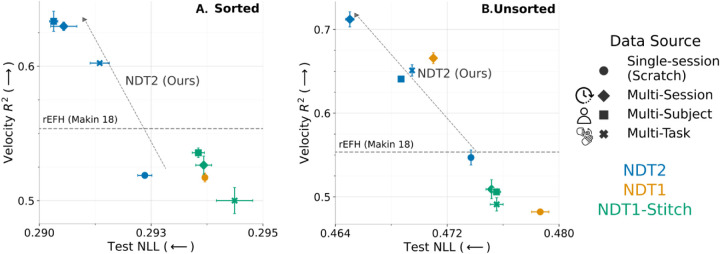
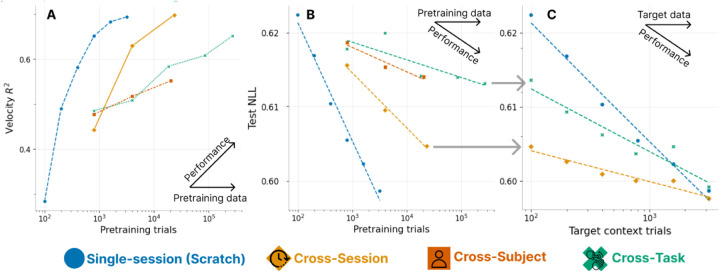
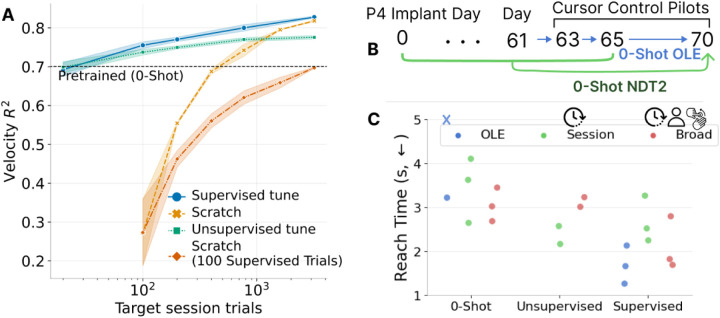
The neural population spiking activity recorded by intracortical brain-computer interfaces (iBCIs) contain rich structure. Current models of such spiking activity are largely prepared for individual experimental contexts, restricting data volume to that collectable within a single session and limiting the effectiveness of deep neural networks (DNNs). The purported challenge in aggregating neural spiking data is the pervasiveness of context-dependent shifts in the neural data distributions. However, large scale unsupervised pretraining by nature spans heterogeneous data, and has proven to be a fundamental recipe for successful representation learning across deep learning. We thus develop Neural Data Transformer 2 (NDT2), a spatiotemporal Transformer for neural spiking activity, and demonstrate that pretraining can leverage motor BCI datasets that span sessions, subjects, and experimental tasks. NDT2 enables rapid adaptation to novel contexts in downstream decoding tasks and opens the path to deployment of pretrained DNNs for iBCI control. Code: https://github.com/joel99/context_general_bci.
Figures
Similar articles
-
Validation of a non-invasive, real-time, human-in-the-loop model of intracortical brain-computer interfaces.J Neural Eng. 2022 Oct 18;19(5):056038. doi: 10.1088/1741-2552/ac97c3. J Neural Eng. 2022. PMID: 36198278 Free PMC article.
-
Increasing Robustness of Intracortical Brain-Computer Interfaces for Recording Condition Changes via Data Augmentation.Comput Methods Programs Biomed. 2024 Jun;251:108208. doi: 10.1016/j.cmpb.2024.108208. Epub 2024 May 3. Comput Methods Programs Biomed. 2024. PMID: 38754326
-
Spiking generative adversarial network with attention scoring decoding.Neural Netw. 2024 Oct;178:106423. doi: 10.1016/j.neunet.2024.106423. Epub 2024 Jun 1. Neural Netw. 2024. PMID: 38906053
-
Population Transformer: Learning Population-level Representations of Neural Activity.ArXiv [Preprint]. 2025 Mar 28:arXiv:2406.03044v4. ArXiv. 2025. PMID: 38883237 Free PMC article. Preprint.
-
AMMU: A survey of transformer-based biomedical pretrained language models.J Biomed Inform. 2022 Feb;126:103982. doi: 10.1016/j.jbi.2021.103982. Epub 2021 Dec 31. J Biomed Inform. 2022. PMID: 34974190 Review.
Cited by
-
Multiscale fusion enhanced spiking neural network for invasive BCI neural signal decoding.Front Neurosci. 2025 Feb 21;19:1551656. doi: 10.3389/fnins.2025.1551656. eCollection 2025. Front Neurosci. 2025. PMID: 40061257 Free PMC article.
References
-
- Altan Ege, Solla Sara A., Miller Lee E., and Perreault Eric J.. Estimating the dimensionality of the manifold underlying multi-electrode neural recordings. PLOS Computational Biology, 17(11):1–23, 11 2021. doi: 10.1371/journal.pcbi.1008591. URL 10.1371/journal.pcbi.1008591. - DOI - DOI - PMC - PubMed
-
- O’Shea Daniel J, Duncker Lea, Goo Werapong, Sun Xulu, Vyas Saurabh, Trautmann Eric M, Diester Ilka, Ramakrishnan Charu, Deisseroth Karl, Sahani Maneesh, et al. Direct neural perturbations reveal a dynamical mechanism for robust computation. bioRxiv, pages 2022–12, 2022.
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources