

Plasma proteomic associations with genetics and health in the UK Biobank
- PMID: 37794186
- PMCID: PMC10567551
- DOI: 10.1038/s41586-023-06592-6
Plasma proteomic associations with genetics and health in the UK Biobank
Abstract
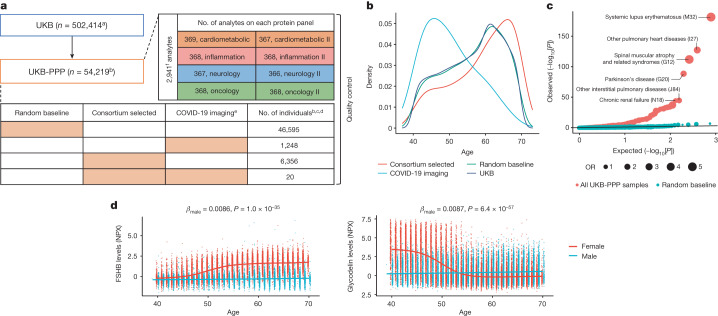
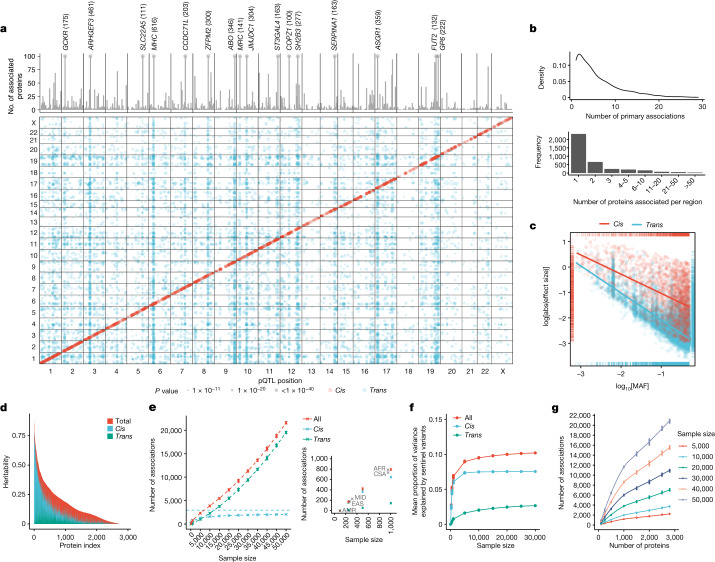
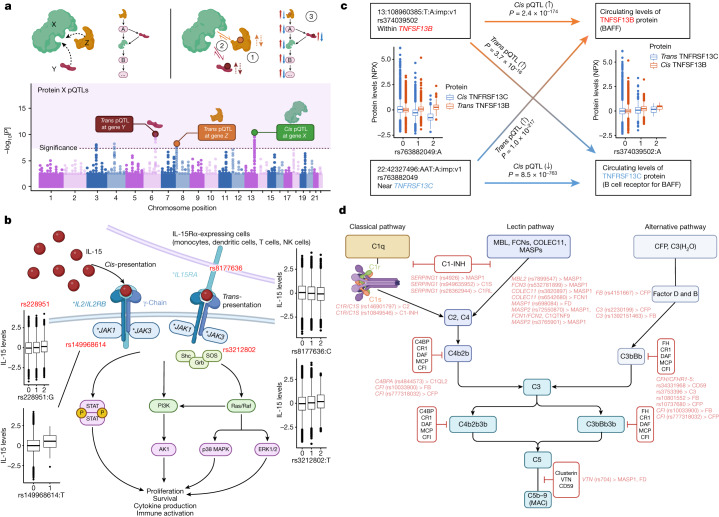
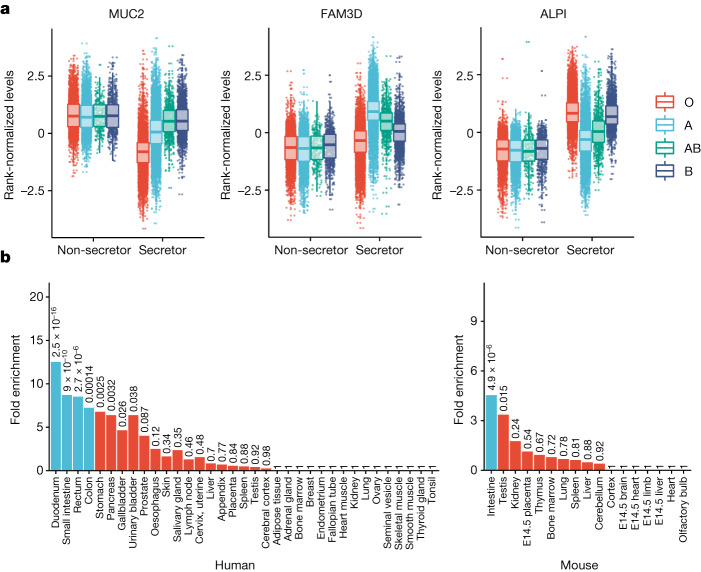
The Pharma Proteomics Project is a precompetitive biopharmaceutical consortium characterizing the plasma proteomic profiles of 54,219 UK Biobank participants. Here we provide a detailed summary of this initiative, including technical and biological validations, insights into proteomic disease signatures, and prediction modelling for various demographic and health indicators. We present comprehensive protein quantitative trait locus (pQTL) mapping of 2,923 proteins that identifies 14,287 primary genetic associations, of which 81% are previously undescribed, alongside ancestry-specific pQTL mapping in non-European individuals. The study provides an updated characterization of the genetic architecture of the plasma proteome, contextualized with projected pQTL discovery rates as sample sizes and proteomic assay coverages increase over time. We offer extensive insights into trans pQTLs across multiple biological domains, highlight genetic influences on ligand-receptor interactions and pathway perturbations across a diverse collection of cytokines and complement networks, and illustrate long-range epistatic effects of ABO blood group and FUT2 secretor status on proteins with gastrointestinal tissue-enriched expression. We demonstrate the utility of these data for drug discovery by extending the genetic proxied effects of protein targets, such as PCSK9, on additional endpoints, and disentangle specific genes and proteins perturbed at loci associated with COVID-19 susceptibility. This public-private partnership provides the scientific community with an open-access proteomics resource of considerable breadth and depth to help to elucidate the biological mechanisms underlying proteo-genomic discoveries and accelerate the development of biomarkers, predictive models and therapeutics1.
© 2023. The Author(s).
Conflict of interest statement
L.D.W., P.N., C.M.W. and A.M.D. are employees and/or stockholders of Alnylam. Y.-H.H. and B.W.G. are employees and/or stockholders of Amgen. S.P., O.S.B. and B.P. are employees and/or stockholders of AstraZeneca. B.B.S., T.L., K.L.F., D.B. and C.-Y.C. are employees and/or stockholders of Biogen. E.M.K., J.D.S. and S.G.V.-G. are employees and/or stockholders of Bristol Myers Squibb. M.C., A.R., A.S. and E.M. are employees and/or stockholders of Calico. R.K.P., M.I.M., A.M. and C.B. are employees of Genentech and holders of Roche stock. C.R., P.S., R.A.S., T.G.R. and J.D. are employees and/or stockholders of GlaxoSmithKline. M.H.B., L.H., D.M.W. and C.D.W. are employees and/or stockholders of Janssen Research & Development. J.M.M.H., S.H. and M.T. are employees and/or stockholders of Novo Nordisk. Å.K.H., E.B.F., J.C. and M.R.M. are employees and/or stockholders of Pfizer. H.M.K., L.J.M. and C.E.G. are employees and/or stockholders of Regeneron. E.N.S., S.S. and R.M. are employees and/or stockholders of Takeda. L.B.-G., C.P. and S.W. are employees of the UK Biobank. The other authors declare no competing interests.
Figures
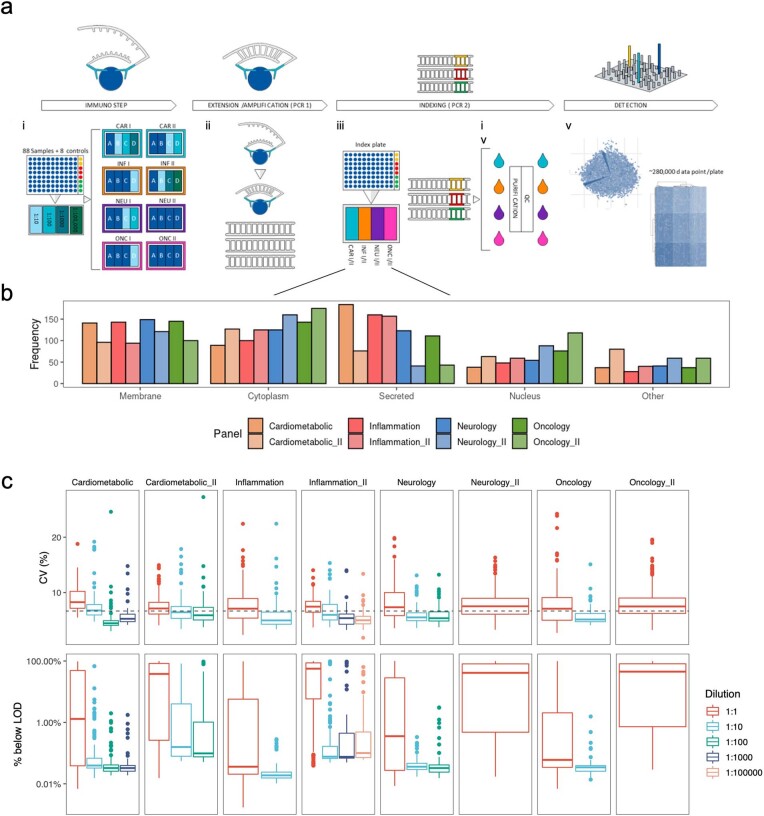
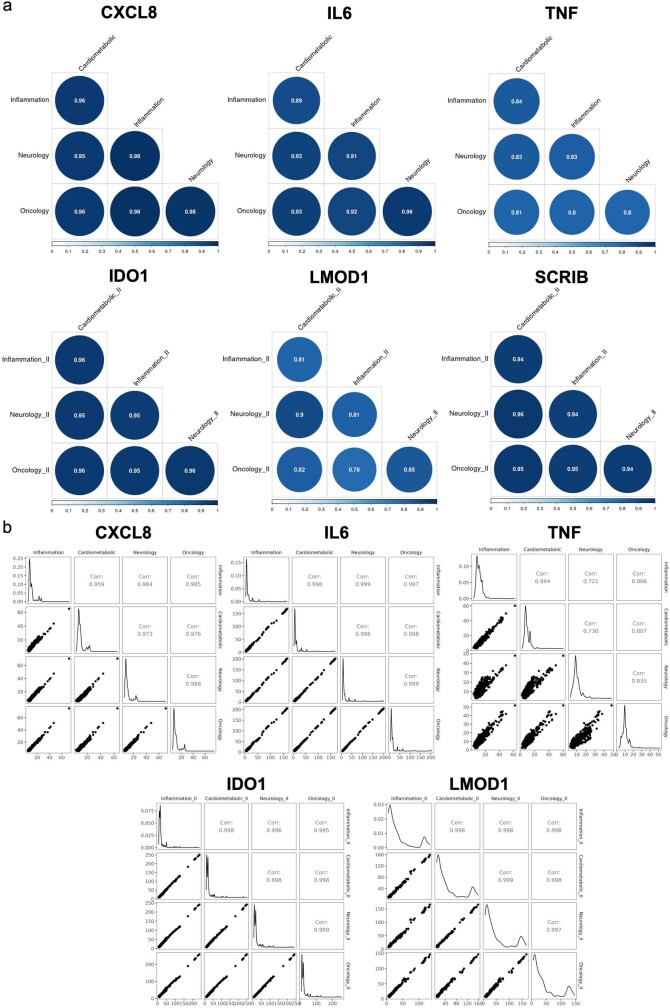
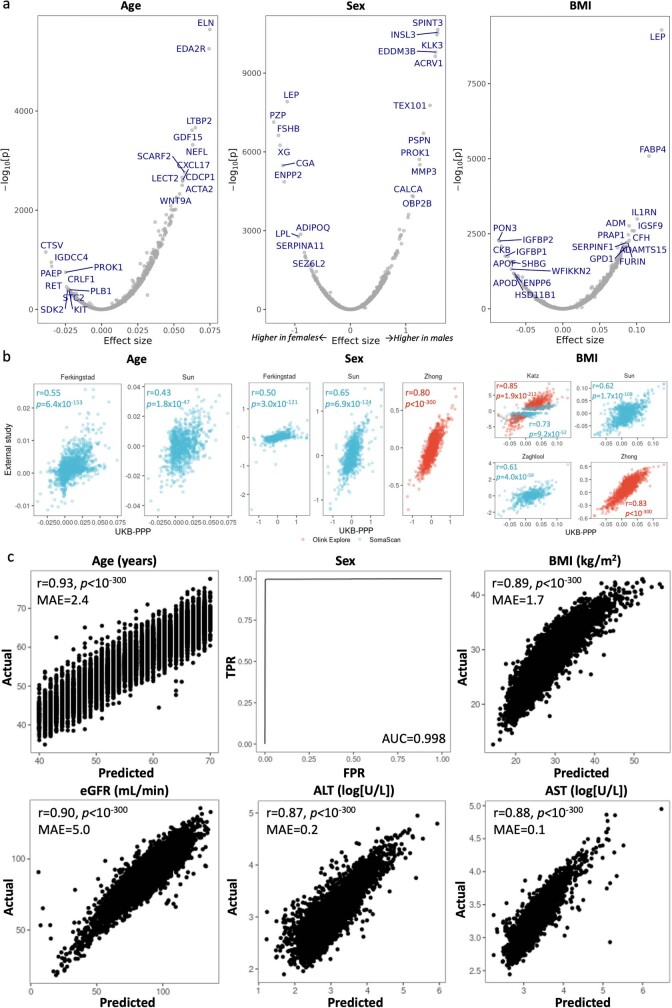
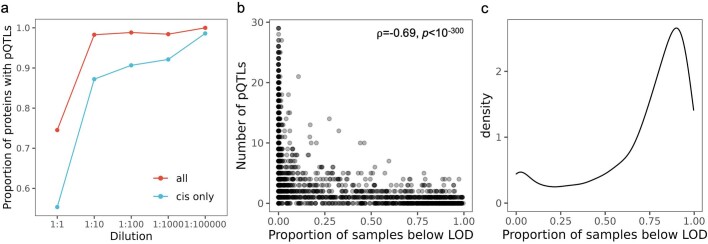
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Miscellaneous
