

ChatGPT-Generated Differential Diagnosis Lists for Complex Case-Derived Clinical Vignettes: Diagnostic Accuracy Evaluation
- PMID: 37812468
- PMCID: PMC10594139
- DOI: 10.2196/48808
ChatGPT-Generated Differential Diagnosis Lists for Complex Case-Derived Clinical Vignettes: Diagnostic Accuracy Evaluation
Abstract
Background: The diagnostic accuracy of differential diagnoses generated by artificial intelligence chatbots, including ChatGPT models, for complex clinical vignettes derived from general internal medicine (GIM) department case reports is unknown.
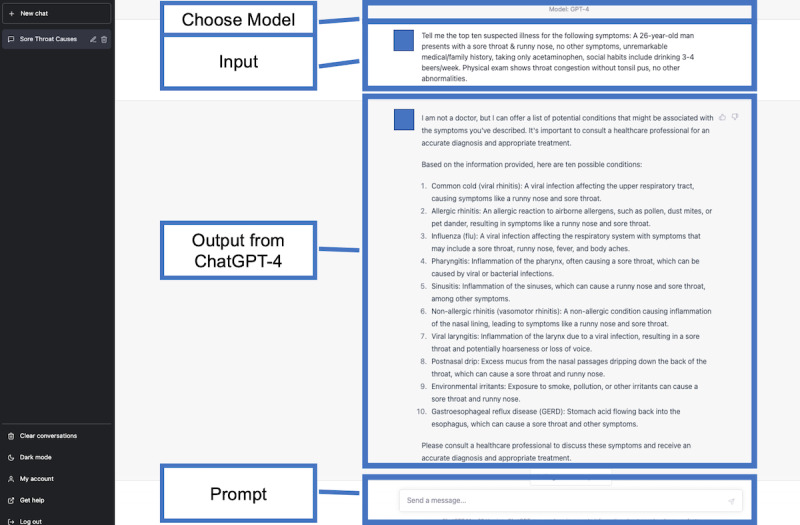
Objective: This study aims to evaluate the accuracy of the differential diagnosis lists generated by both third-generation ChatGPT (ChatGPT-3.5) and fourth-generation ChatGPT (ChatGPT-4) by using case vignettes from case reports published by the Department of GIM of Dokkyo Medical University Hospital, Japan.
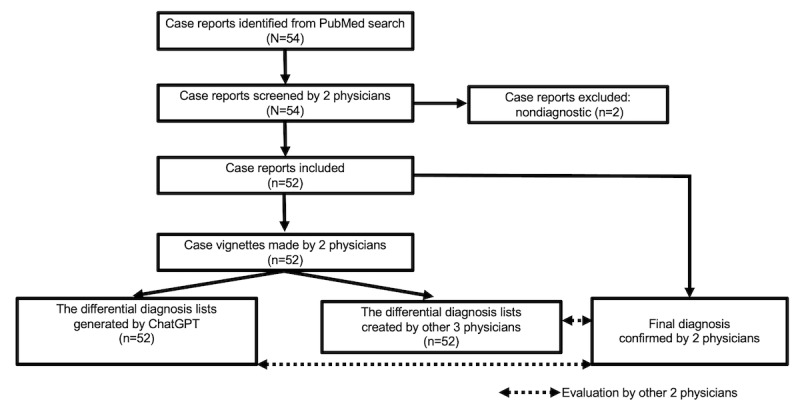
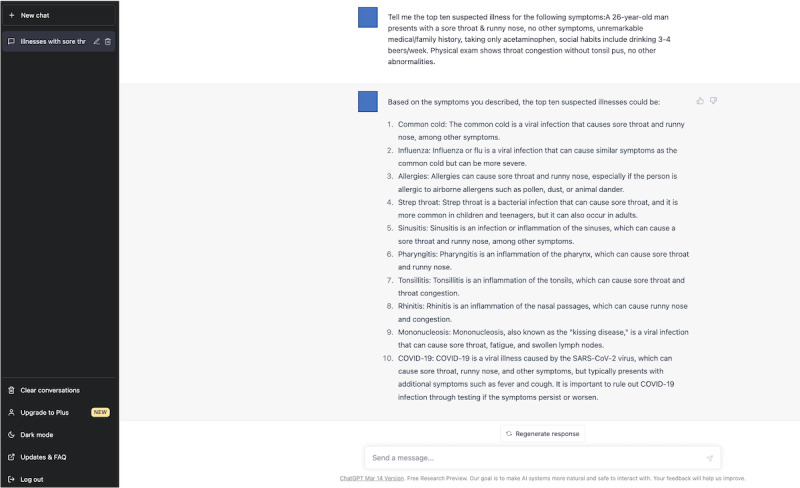
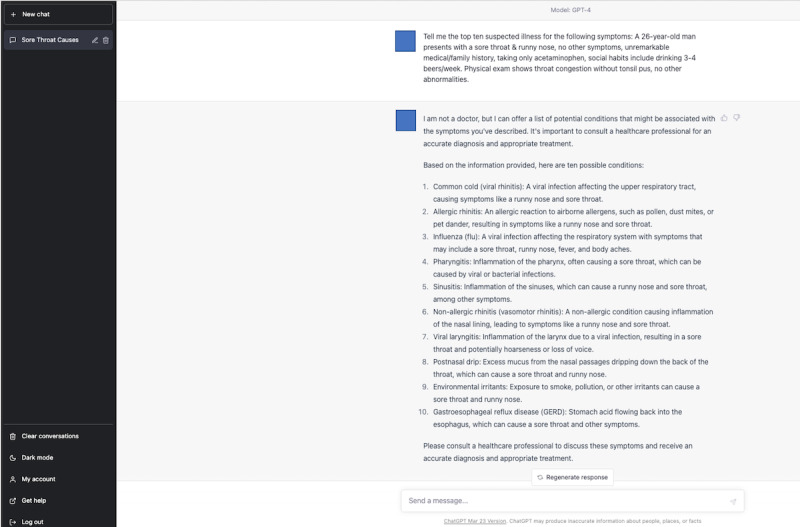
Methods: We searched PubMed for case reports. Upon identification, physicians selected diagnostic cases, determined the final diagnosis, and displayed them into clinical vignettes. Physicians typed the determined text with the clinical vignettes in the ChatGPT-3.5 and ChatGPT-4 prompts to generate the top 10 differential diagnoses. The ChatGPT models were not specially trained or further reinforced for this task. Three GIM physicians from other medical institutions created differential diagnosis lists by reading the same clinical vignettes. We measured the rate of correct diagnosis within the top 10 differential diagnosis lists, top 5 differential diagnosis lists, and the top diagnosis.
Results: In total, 52 case reports were analyzed. The rates of correct diagnosis by ChatGPT-4 within the top 10 differential diagnosis lists, top 5 differential diagnosis lists, and top diagnosis were 83% (43/52), 81% (42/52), and 60% (31/52), respectively. The rates of correct diagnosis by ChatGPT-3.5 within the top 10 differential diagnosis lists, top 5 differential diagnosis lists, and top diagnosis were 73% (38/52), 65% (34/52), and 42% (22/52), respectively. The rates of correct diagnosis by ChatGPT-4 were comparable to those by physicians within the top 10 (43/52, 83% vs 39/52, 75%, respectively; P=.47) and within the top 5 (42/52, 81% vs 35/52, 67%, respectively; P=.18) differential diagnosis lists and top diagnosis (31/52, 60% vs 26/52, 50%, respectively; P=.43) although the difference was not significant. The ChatGPT models' diagnostic accuracy did not significantly vary based on open access status or the publication date (before 2011 vs 2022).
Conclusions: This study demonstrates the potential diagnostic accuracy of differential diagnosis lists generated using ChatGPT-3.5 and ChatGPT-4 for complex clinical vignettes from case reports published by the GIM department. The rate of correct diagnoses within the top 10 and top 5 differential diagnosis lists generated by ChatGPT-4 exceeds 80%. Although derived from a limited data set of case reports from a single department, our findings highlight the potential utility of ChatGPT-4 as a supplementary tool for physicians, particularly for those affiliated with the GIM department. Further investigations should explore the diagnostic accuracy of ChatGPT by using distinct case materials beyond its training data. Such efforts will provide a comprehensive insight into the role of artificial intelligence in enhancing clinical decision-making.
Keywords: AI chatbot; ChatGPT; accuracy; artificial intelligence; case study; clinical decision support; decision support; diagnosis; diagnostic; diagnostic excellence; language model; large language models; natural language processing; vignette.
©Takanobu Hirosawa, Ren Kawamura, Yukinori Harada, Kazuya Mizuta, Kazuki Tokumasu, Yuki Kaji, Tomoharu Suzuki, Taro Shimizu. Originally published in JMIR Medical Informatics (https://medinform.jmir.org), 09.10.2023.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
References
-
- Holmboe E, Durning S. Assessing clinical reasoning: moving from in vitro to in vivo. Diagnosis (Berl) 2014 Jan 01;1(1):111–117. doi: 10.1515/dx-2013-0029. https://www.degruyter.com/document/doi/10.1515/dx-2013-0029 /j/dx.2014.1.issue-1/dx-2013-0029/dx-2013-0029.xml - DOI - DOI - PubMed
-
- Harada Y, Otaka Y, Katsukura S, Shimizu T. Effect of contextual factors on the prevalence of diagnostic errors among patients managed by physicians of the same specialty: a single-centre retrospective observational study. BMJ Qual Saf. 2023 Jan 23;:bmjqs-2022-015436. doi: 10.1136/bmjqs-2022-015436. - DOI - PubMed
-
- Committee on Diagnostic Error in Health Care. Board on Health Care Services. Balogh EP, Miller BT. Improving Diagnosis in Health Care. Washington DC: National Academies Press (US); 2015. Dec 29, Technology and tools in the diagnostic process. - PubMed
-
- Schmieding ML, Kopka M, Schmidt K, Schulz-Niethammer S, Balzer F, Feufel MA. Triage accuracy of symptom checker apps: 5-year follow-up evaluation. J Med Internet Res. 2022 May 10;24(5):e31810. doi: 10.2196/31810. https://www.jmir.org/2022/5/e31810/ v24i5e31810 - DOI - PMC - PubMed
LinkOut - more resources
Full Text Sources
