

scIBD: a self-supervised iterative-optimizing model for boosting the detection of heterotypic doublets in single-cell chromatin accessibility data
- PMID: 37814314
- PMCID: PMC10561408
- DOI: 10.1186/s13059-023-03072-y
scIBD: a self-supervised iterative-optimizing model for boosting the detection of heterotypic doublets in single-cell chromatin accessibility data
Abstract
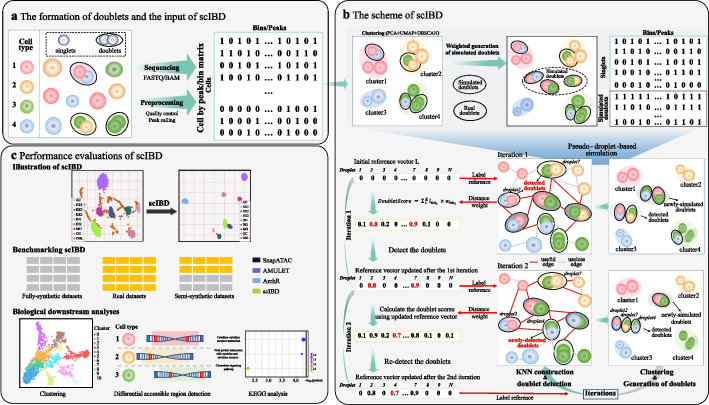
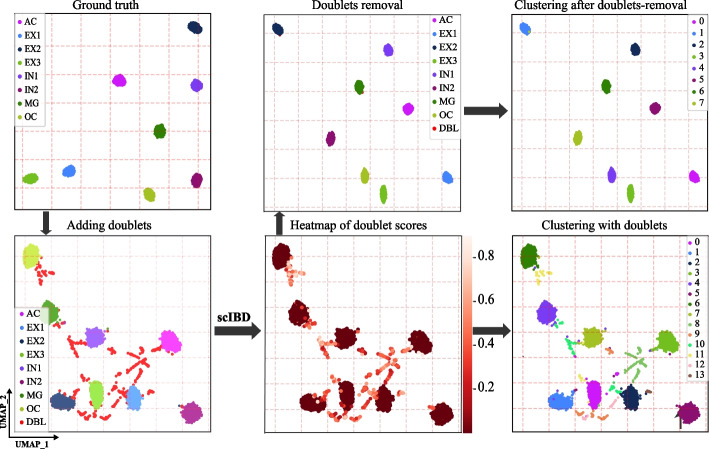
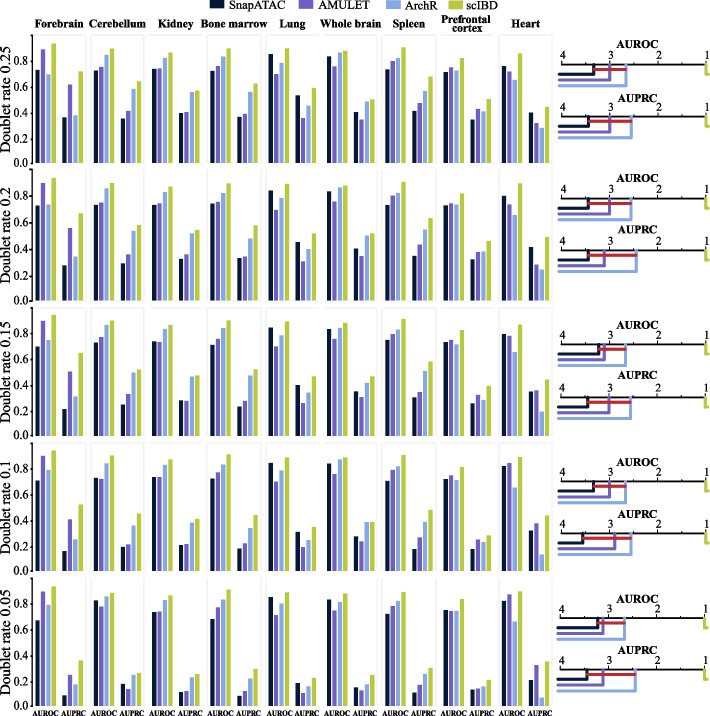
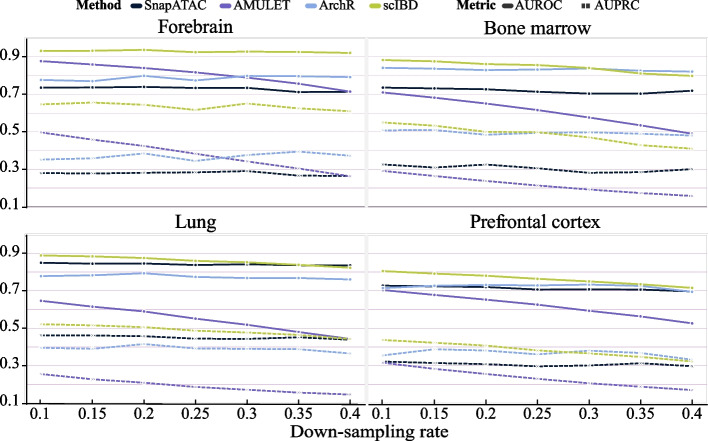
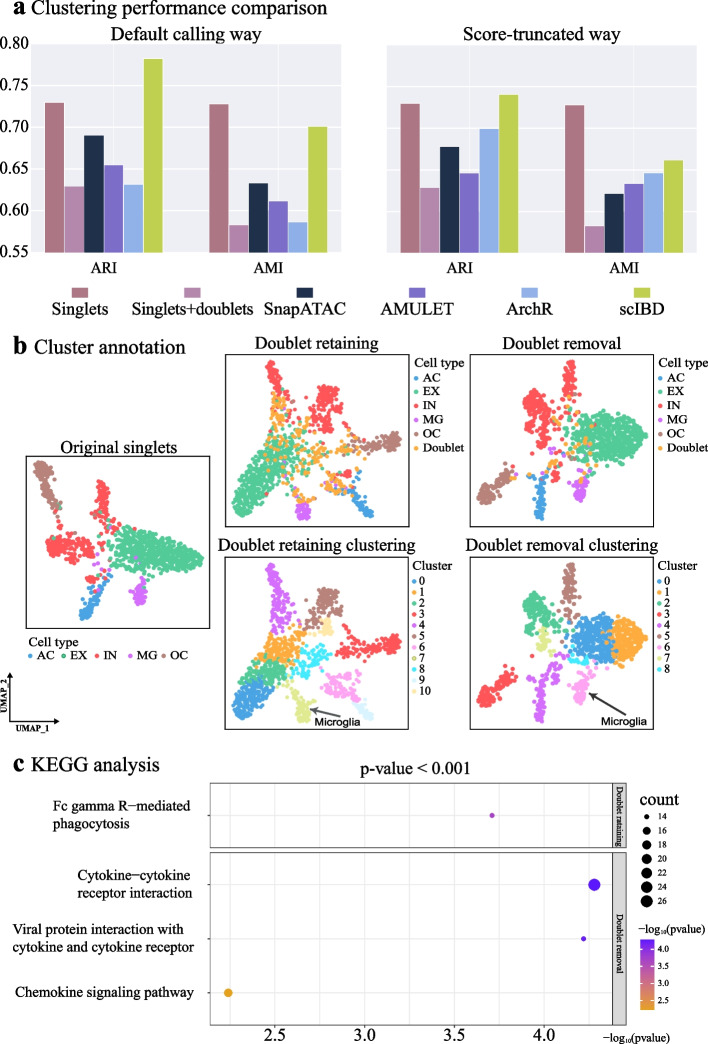
Application of the widely used droplet-based microfluidic technologies in single-cell sequencing often yields doublets, introducing bias to downstream analyses. Especially, doublet-detection methods for single-cell chromatin accessibility sequencing (scCAS) data have multiple assay-specific challenges. Therefore, we propose scIBD, a self-supervised iterative-optimizing model for boosting heterotypic doublet detection in scCAS data. scIBD introduces an adaptive strategy to simulate high-confident heterotypic doublets and self-supervise for doublet-detection in an iteratively optimizing manner. Comprehensive benchmarking on various simulated and real datasets demonstrates the outperformance and robustness of scIBD. Moreover, the downstream biological analyses suggest the efficacy of doublet-removal by scIBD.
Keywords: Chromatin accessibility; Detection; Doublets; Single-cell.
© 2023. BioMed Central Ltd., part of Springer Nature.
Conflict of interest statement
The authors declare no competing interests.
Figures



Similar articles
-
Benchmarking Computational Doublet-Detection Methods for Single-Cell RNA Sequencing Data.Cell Syst. 2021 Feb 17;12(2):176-194.e6. doi: 10.1016/j.cels.2020.11.008. Epub 2020 Dec 17. Cell Syst. 2021. PMID: 33338399 Free PMC article.
-
scCASE: accurate and interpretable enhancement for single-cell chromatin accessibility sequencing data.Nat Commun. 2024 Feb 22;15(1):1629. doi: 10.1038/s41467-024-46045-w. Nat Commun. 2024. PMID: 38388573 Free PMC article.
-
Improving doublet cell removal efficiency through multiple algorithm runs.Comput Struct Biotechnol J. 2025 Jan 15;27:451-460. doi: 10.1016/j.csbj.2025.01.009. eCollection 2025. Comput Struct Biotechnol J. 2025. PMID: 39911841 Free PMC article.
-
A plate-based single-cell ATAC-seq workflow for fast and robust profiling of chromatin accessibility.Nat Protoc. 2021 Aug;16(8):4084-4107. doi: 10.1038/s41596-021-00583-5. Epub 2021 Jul 19. Nat Protoc. 2021. PMID: 34282334 Review.
-
Platinum-doublet chemotherapy as second-line treatment for relapsed patients with small-cell lung cancer: A systematic review and meta-analysis.Lung Cancer. 2021 Jun;156:59-67. doi: 10.1016/j.lungcan.2021.04.013. Epub 2021 Apr 19. Lung Cancer. 2021. PMID: 33894495
References
-
- Stuart T, Satija R. Integrative single-cell analysis. Nat Rev Genetics. 2019;20:257–272. - PubMed
-
- Zilionis R, Nainys J, Veres A, Savova V, Zemmour D, Klein AM, Mazutis L. Single-cell barcoding and sequencing using droplet microfluidics. Nat Protocols. 2017;12:44–73. - PubMed
-
- Guo MT, Rotem A, Heyman JA, Weitz DA. Droplet microfluidics for high-throughput biological assays. Lab Chip. 2012;12:2146–2155. - PubMed
-
- Kang HM, Subramaniam M, Targ S, Nguyen M, Maliskova L, McCarthy E, Wan E, Wong S, Byrnes L, Lanata CM, et al. Multiplexed droplet single-cell RNA-sequencing using natural genetic variation (vol 36, pg 89, 2018) Nat Biotechnol. 2020;38:1356–1356. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
