Unraveling the functional dark matter through global metagenomics
- PMID: 37821698
- PMCID: PMC10584684
- DOI: 10.1038/s41586-023-06583-7
Unraveling the functional dark matter through global metagenomics
Abstract
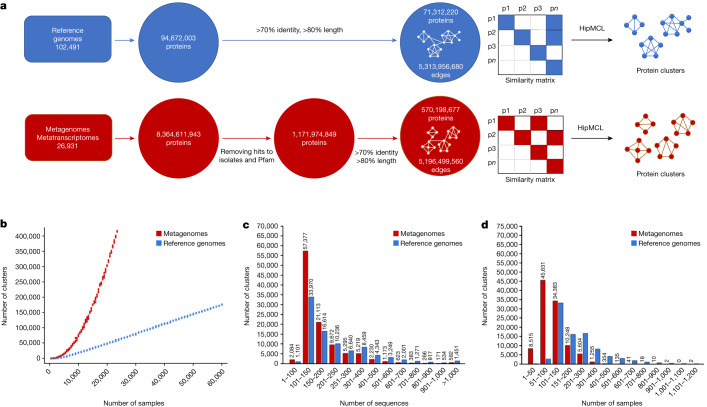
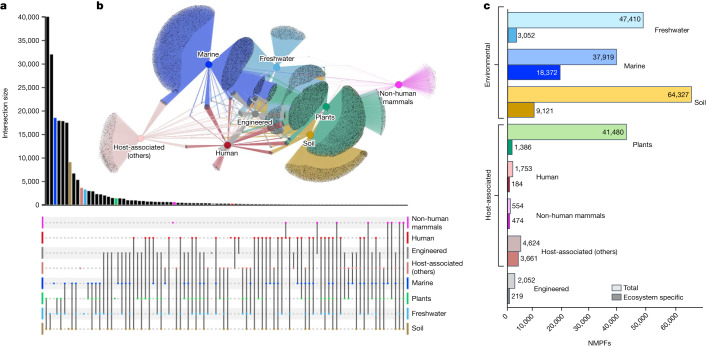
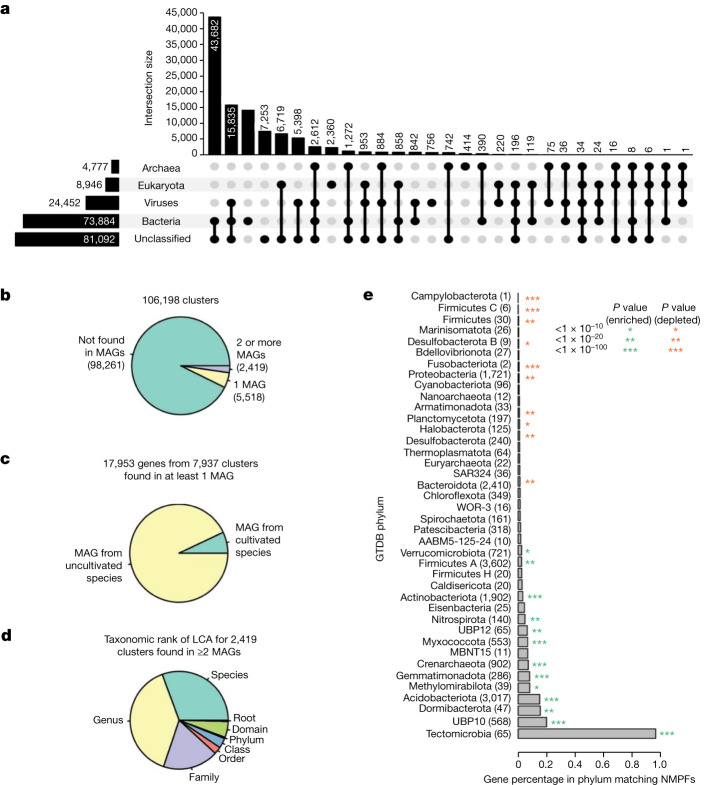
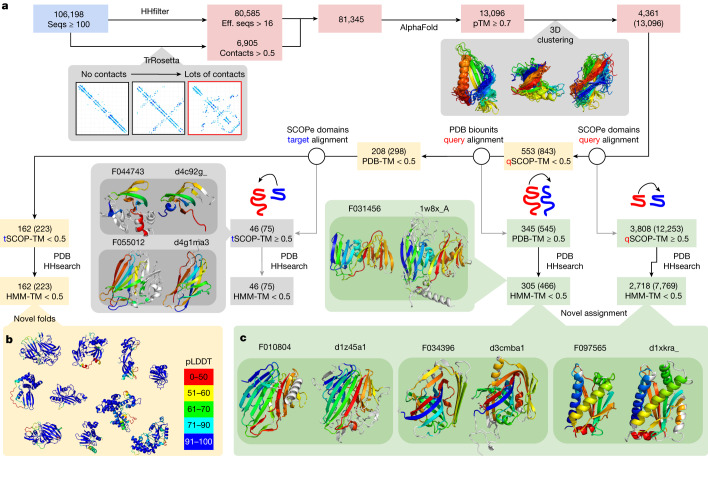
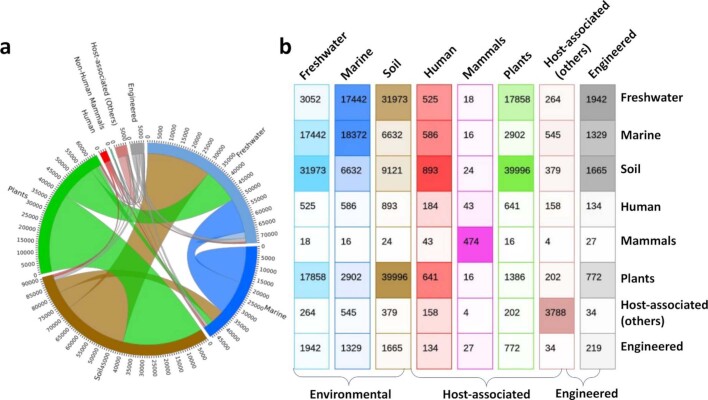
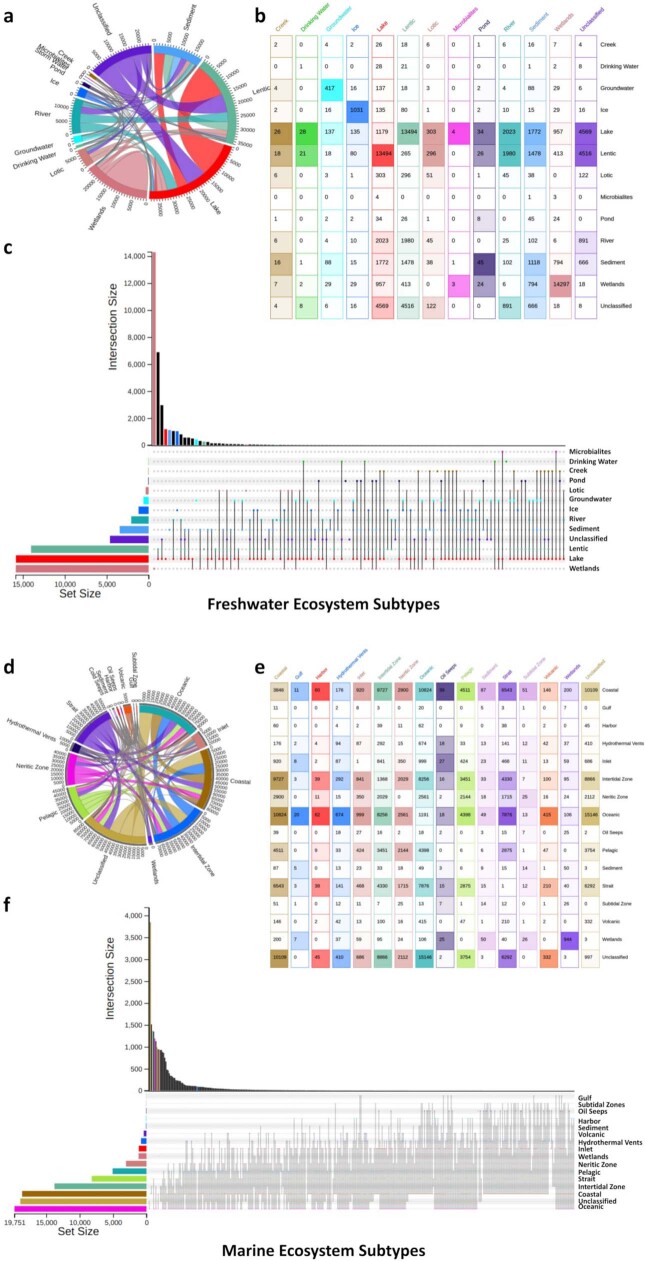
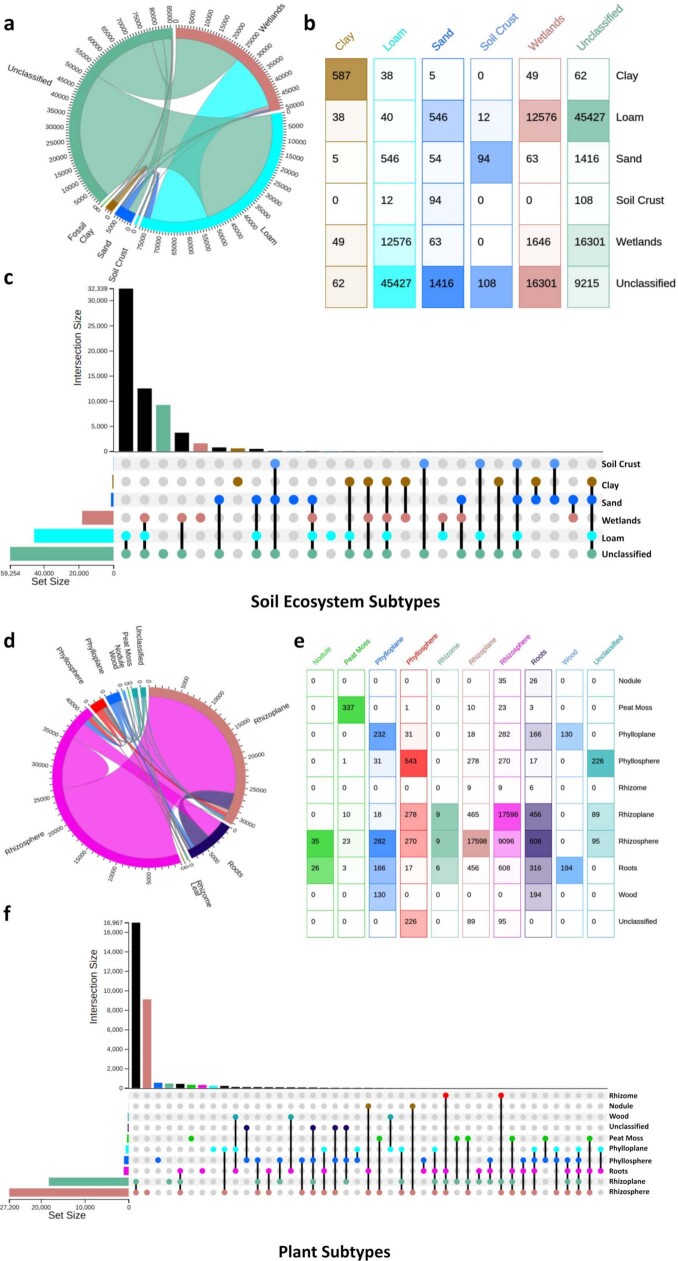
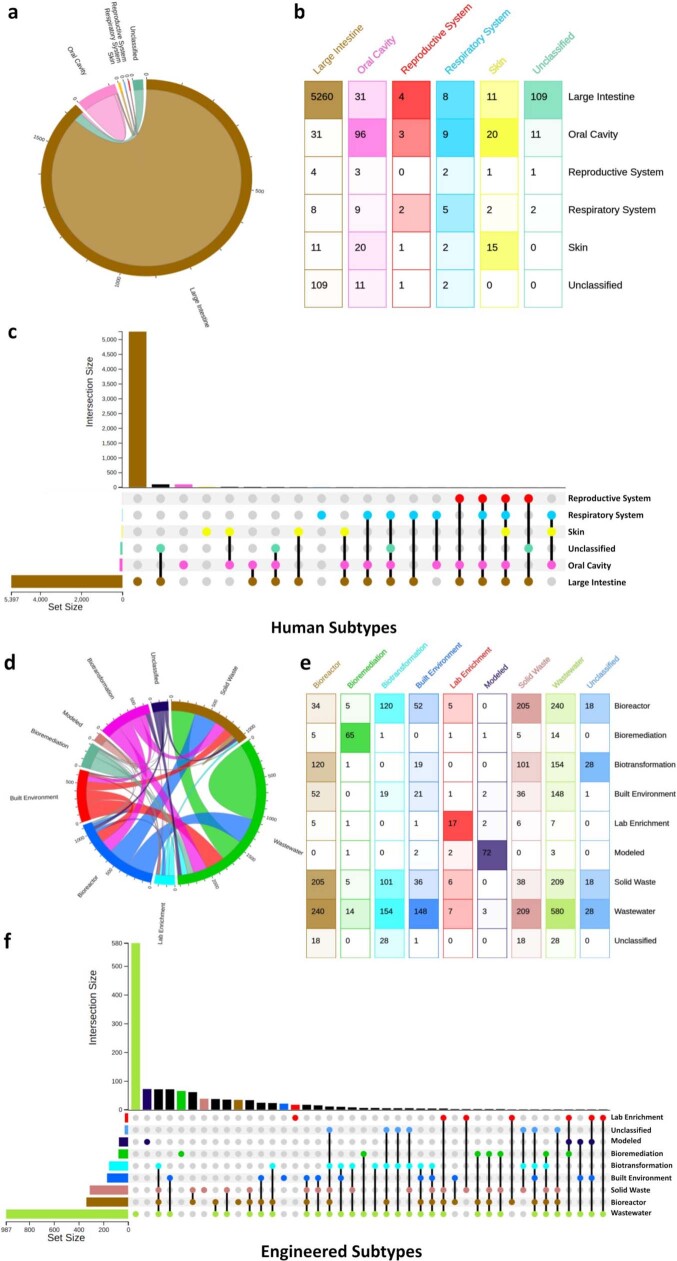
Metagenomes encode an enormous diversity of proteins, reflecting a multiplicity of functions and activities1,2. Exploration of this vast sequence space has been limited to a comparative analysis against reference microbial genomes and protein families derived from those genomes. Here, to examine the scale of yet untapped functional diversity beyond what is currently possible through the lens of reference genomes, we develop a computational approach to generate reference-free protein families from the sequence space in metagenomes. We analyse 26,931 metagenomes and identify 1.17 billion protein sequences longer than 35 amino acids with no similarity to any sequences from 102,491 reference genomes or the Pfam database3. Using massively parallel graph-based clustering, we group these proteins into 106,198 novel sequence clusters with more than 100 members, doubling the number of protein families obtained from the reference genomes clustered using the same approach. We annotate these families on the basis of their taxonomic, habitat, geographical and gene neighbourhood distributions and, where sufficient sequence diversity is available, predict protein three-dimensional models, revealing novel structures. Overall, our results uncover an enormously diverse functional space, highlighting the importance of further exploring the microbial functional dark matter.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures