

Multi-object detection for crowded road scene based on ML-AFP of YOLOv5
- PMID: 37828051
- PMCID: PMC10570361
- DOI: 10.1038/s41598-023-43458-3
Multi-object detection for crowded road scene based on ML-AFP of YOLOv5
Abstract
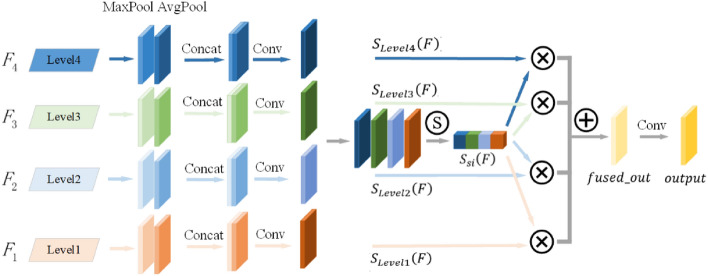
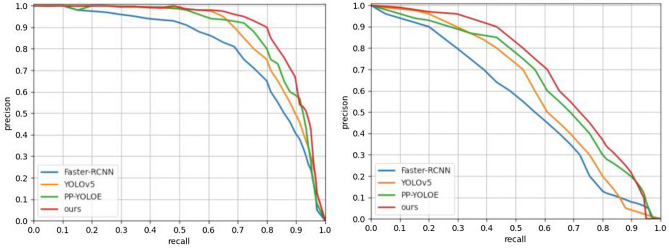
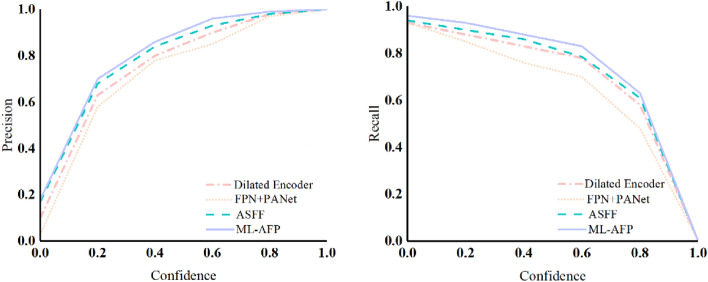
Aiming at the problem of multi-object detection such as target occlusion and tiny targets in road scenes, this paper proposes an improved YOLOv5 multi-object detection model based on ML-AFP (multi-level aggregation feature perception) mechanism. Since tiny targets such as non-motor vehicle and pedestrians are not easily detected, this paper adds a micro target detection layer and a double head mechanism to improve the detection ability of tiny targets. Varifocal loss is used to achieve a more accurate ranking in the process of non-maximum suppression to solve the problem of target occlusion, and this paper also proposes a ML-AFP mechanism. The adaptive fusion of spatial feature information at different scales improves the expression ability of network model features, and improves the detection accuracy of the model as a whole. Our experimental results on multiple challenging datasets such as KITTI, BDD100K, and show that the accuracy, recall rate and mAP value of the proposed model are greatly improved, which solves the problem of multi-object detection in crowded road scenes.
© 2023. Springer Nature Limited.
Conflict of interest statement
The authors declare no competing interests.
Figures




Similar articles
-
Enhanced YOLOv5: An Efficient Road Object Detection Method.Sensors (Basel). 2023 Oct 10;23(20):8355. doi: 10.3390/s23208355. Sensors (Basel). 2023. PMID: 37896450 Free PMC article.
-
Research on multi-object detection technology for road scenes based on SDG-YOLOv5.PeerJ Comput Sci. 2024 Apr 30;10:e2021. doi: 10.7717/peerj-cs.2021. eCollection 2024. PeerJ Comput Sci. 2024. PMID: 38855227 Free PMC article.
-
ASG-YOLOv5: Improved YOLOv5 unmanned aerial vehicle remote sensing aerial images scenario for small object detection based on attention and spatial gating.PLoS One. 2024 Jun 3;19(6):e0298698. doi: 10.1371/journal.pone.0298698. eCollection 2024. PLoS One. 2024. PMID: 38829850 Free PMC article.
-
RE-YOLOv5: Enhancing Occluded Road Object Detection via Visual Receptive Field Improvements.Sensors (Basel). 2025 Apr 17;25(8):2518. doi: 10.3390/s25082518. Sensors (Basel). 2025. PMID: 40285209 Free PMC article.
-
Research on a vehicle and pedestrian detection algorithm based on improved attention and feature fusion.Math Biosci Eng. 2024 Apr 26;21(4):5782-5802. doi: 10.3934/mbe.2024255. Math Biosci Eng. 2024. PMID: 38872558
Cited by
-
AcuSim: A Synthetic Dataset for Cervicocranial Acupuncture Points Localisation.Sci Data. 2025 Apr 15;12(1):625. doi: 10.1038/s41597-025-04934-9. Sci Data. 2025. PMID: 40234485 Free PMC article.
References
-
- Tian, Y. Research on object detection and classification technology in traffic video surveillance. Beijing University of Posts and Telecommunications. 02–04. (2009).
-
- Tian, Z., Shen, C., Chen, H. & T, He. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 9627–9636 (IEEE, 2019). 10.1109/ICCV.2019.00972
-
- Zhou, X., Wang, D. & Krhenbühl, P. Objects as points. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7263–7271 (Long Beach, 2019).
-
- Law, H. & Deng, J. CornerNet: Detecting objects as paired keypoints. In: Proceedings of the European Conference on Computer Vision, 765–781 (2018). 10.1007/978-3-030-01264-9_45
Grants and funding
LinkOut - more resources
Full Text Sources
