

Distribution-dependent representations in auditory category learning and generalization
- PMID: 37829077
- PMCID: PMC10566369
- DOI: 10.3389/fpsyg.2023.1132570
Distribution-dependent representations in auditory category learning and generalization
Abstract
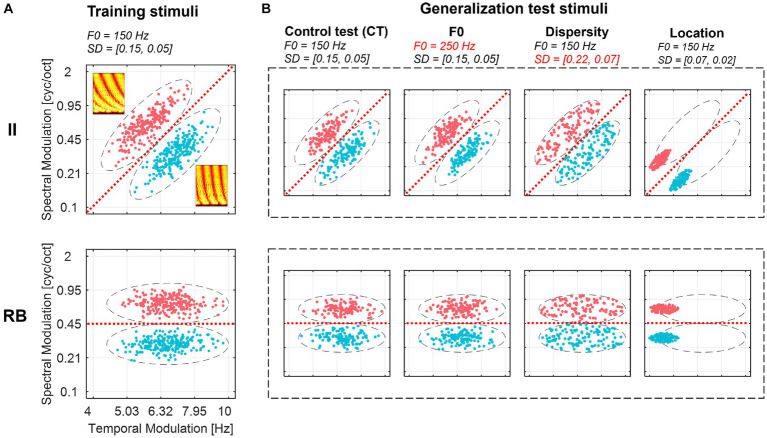
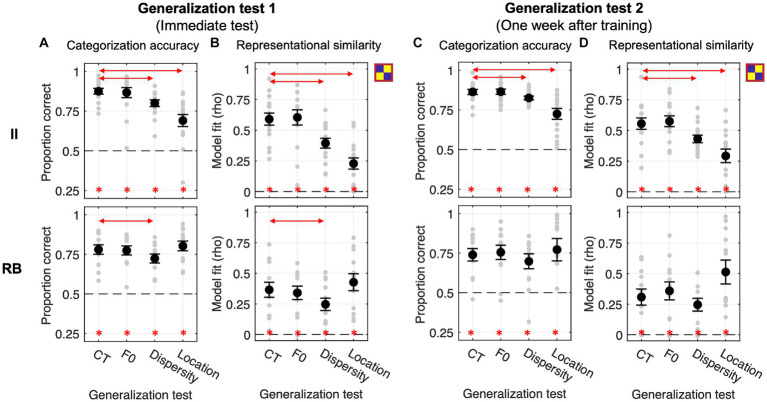
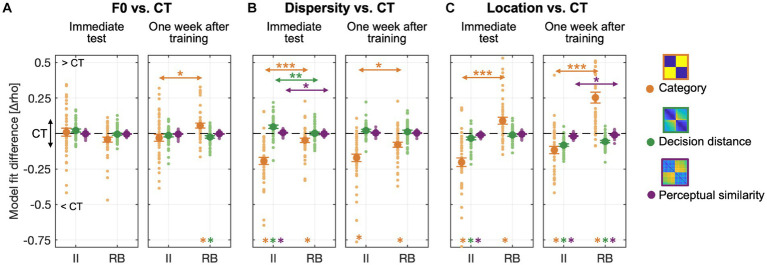
A fundamental objective in Auditory Sciences is to understand how people learn to generalize auditory category knowledge in new situations. How we generalize to novel scenarios speaks to the nature of acquired category representations and generalization mechanisms in handling perceptual variabilities and novelty. The dual learning system (DLS) framework proposes that auditory category learning involves an explicit, hypothesis-testing learning system, which is optimal for learning rule-based (RB) categories, and an implicit, procedural-based learning system, which is optimal for learning categories requiring pre-decisional information integration (II) across acoustic dimensions. Although DLS describes distinct mechanisms of two types of category learning, it is yet clear the nature of acquired representations and how we transfer them to new contexts. Here, we conducted three experiments to examine differences between II and RB category representations by examining what acoustic and perceptual novelties and variabilities affect learners' generalization success. Learners can successfully categorize different sets of untrained sounds after only eight blocks of training for both II and RB categories. The category structures and novel contexts differentially modulated the generalization success. The II learners significantly decreased generalization performances when categorizing new items derived from an untrained perceptual area and in a context with more distributed samples. In contrast, RB learners' generalizations are resistant to changes in perceptual regions but are sensitive to changes in sound dispersity. Representational similarity modeling revealed that the generalization in the more dispersed sampling context was accomplished differently by II and RB learners. II learners increased representations of perceptual similarity and decision distance to compensate for the decreased transfer of category representations, whereas the RB learners used a more computational cost strategy by default, computing the decision-bound distance to guide generalization decisions. These results suggest that distinct representations emerged after learning the two types of category structures and using different computations and flexible mechanisms in resolving generalization challenges when facing novel perceptual variability in new contexts. These findings provide new evidence for dissociated representations of auditory categories and reveal novel generalization mechanisms in resolving variabilities to maintain perceptual constancy.
Keywords: auditory category learning; dual learning system; generalization; information integration; representation nature; rule-based learning.
Copyright © 2023 Gan, Zheng, Wang and Feng.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures





References
-
- Ashby F. G., Maddox W. T. (1992). Complex decision rules in categorization: contrasting novice and experienced performance. J. Exp. Psychol. Hum. Percept. Perform. 18, 50–71. doi: 10.1037/0096-1523.18.1.50 - DOI
LinkOut - more resources
Full Text Sources