

Interpreting Randomized Controlled Trials
- PMID: 37835368
- PMCID: PMC10571666
- DOI: 10.3390/cancers15194674
Interpreting Randomized Controlled Trials
Abstract
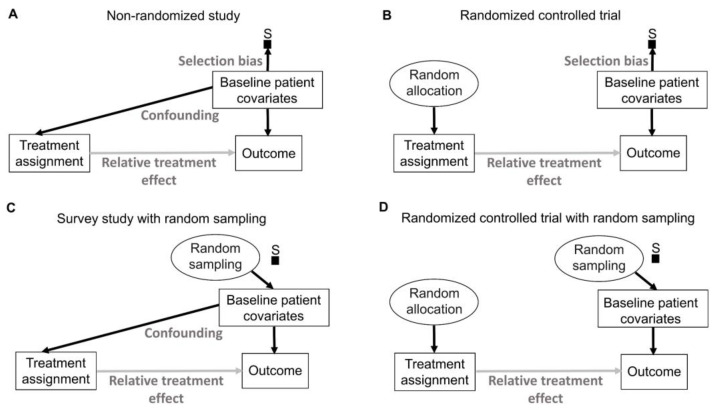
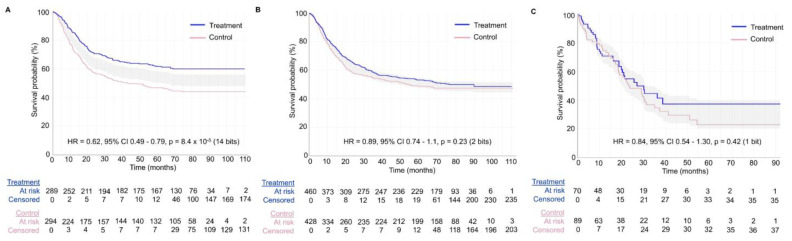
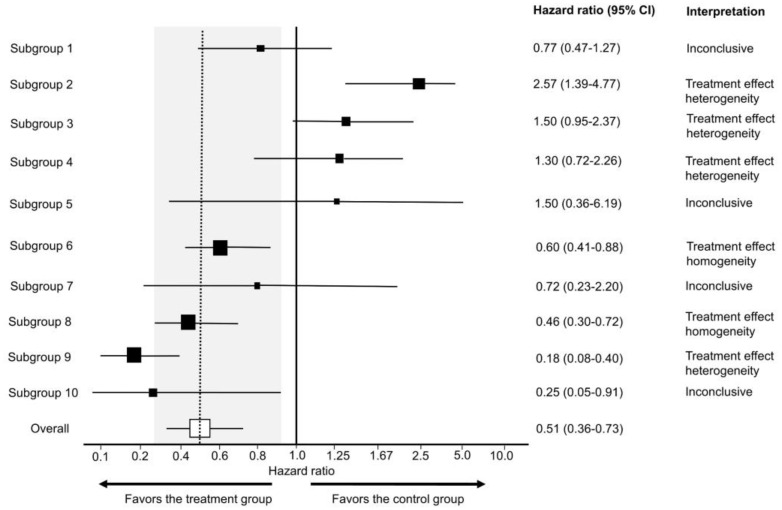
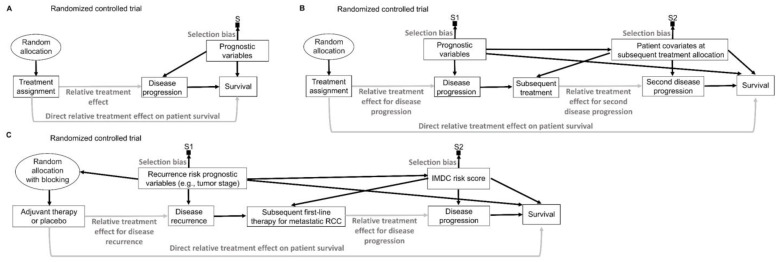
This article describes rationales and limitations for making inferences based on data from randomized controlled trials (RCTs). We argue that obtaining a representative random sample from a patient population is impossible for a clinical trial because patients are accrued sequentially over time and thus comprise a convenience sample, subject only to protocol entry criteria. Consequently, the trial's sample is unlikely to represent a definable patient population. We use causal diagrams to illustrate the difference between random allocation of interventions within a clinical trial sample and true simple or stratified random sampling, as executed in surveys. We argue that group-specific statistics, such as a median survival time estimate for a treatment arm in an RCT, have limited meaning as estimates of larger patient population parameters. In contrast, random allocation between interventions facilitates comparative causal inferences about between-treatment effects, such as hazard ratios or differences between probabilities of response. Comparative inferences also require the assumption of transportability from a clinical trial's convenience sample to a targeted patient population. We focus on the consequences and limitations of randomization procedures in order to clarify the distinctions between pairs of complementary concepts of fundamental importance to data science and RCT interpretation. These include internal and external validity, generalizability and transportability, uncertainty and variability, representativeness and inclusiveness, blocking and stratification, relevance and robustness, forward and reverse causal inference, intention to treat and per protocol analyses, and potential outcomes and counterfactuals.
Keywords: blocking; confidence intervals; generalizability; hazard ratios; random allocation; random sampling; random treatment assignment; randomized controlled trials; stratification; transportability.
Conflict of interest statement
P.M. reports honoraria for scientific advisory board membership for Mirati Therapeutics, Bristol Myers Squibb, and Exelixis; consulting fees from Axiom Healthcare; nonbranded educational programs supported by Exelixis and Pfizer; leadership or fiduciary roles as a Medical Steering Committee member for the Kidney Cancer Association and a Kidney Cancer Scientific Advisory Board member for KCCure; and research funding from Takeda, Bristol Myers Squibb, Mirati Therapeutics, and Gateway for Cancer Research. J.L. and P.F.T. Thall have nothing to disclose.
Figures




Similar articles
-
Safety and Efficacy of Imatinib for Hospitalized Adults with COVID-19: A structured summary of a study protocol for a randomised controlled trial.Trials. 2020 Oct 28;21(1):897. doi: 10.1186/s13063-020-04819-9. Trials. 2020. PMID: 33115543 Free PMC article.
-
Effectiveness and cost-effectiveness of four different strategies for SARS-CoV-2 surveillance in the general population (CoV-Surv Study): a structured summary of a study protocol for a cluster-randomised, two-factorial controlled trial.Trials. 2021 Jan 8;22(1):39. doi: 10.1186/s13063-020-04982-z. Trials. 2021. PMID: 33419461 Free PMC article.
-
The future of Cochrane Neonatal.Early Hum Dev. 2020 Nov;150:105191. doi: 10.1016/j.earlhumdev.2020.105191. Epub 2020 Sep 12. Early Hum Dev. 2020. PMID: 33036834
-
Systematic review of applied transportability and generalizability analyses: A landscape analysis.Ann Epidemiol. 2025 Apr;104:61-70. doi: 10.1016/j.annepidem.2025.03.001. Epub 2025 Mar 8. Ann Epidemiol. 2025. PMID: 40064249
-
Cluster over individual randomization: are study design choices appropriately justified? Review of a random sample of trials.Clin Trials. 2020 Jun;17(3):253-263. doi: 10.1177/1740774519896799. Epub 2020 May 5. Clin Trials. 2020. PMID: 32367741 Review.
Cited by
-
Increasing Power in Phase III Oncology Trials With Multivariable Regression: An Empirical Assessment of 535 Primary End Point Analyses.JCO Clin Cancer Inform. 2024 Sep;8:e2400102. doi: 10.1200/CCI.24.00102. JCO Clin Cancer Inform. 2024. PMID: 39213473
-
Justification, margin values, and analysis populations for oncologic noninferiority and equivalence trials: a meta-epidemiological study.J Natl Cancer Inst. 2025 May 1;117(5):898-906. doi: 10.1093/jnci/djae318. J Natl Cancer Inst. 2025. PMID: 39657246
-
Towards Treatment Effect Interpretability: A Bayesian Re-analysis of 194,129 Patient Outcomes Across 230 Oncology Trials.medRxiv [Preprint]. 2024 Jul 24:2024.07.23.24310891. doi: 10.1101/2024.07.23.24310891. medRxiv. 2024. PMID: 39108512 Free PMC article. Preprint.
-
Evidenced-Based Prior for Estimating the Treatment Effect of Phase III Randomized Trials in Oncology.JCO Precis Oncol. 2024 Oct;8:e2400363. doi: 10.1200/PO.24.00363. Epub 2024 Oct 2. JCO Precis Oncol. 2024. PMID: 39348660
-
Reproducibility of statistically significant phase III oncology trials: An In Silico meta-epidemiological analysis.Eur J Cancer. 2025 Aug 26;226:115596. doi: 10.1016/j.ejca.2025.115596. Epub 2025 Jul 4. Eur J Cancer. 2025. PMID: 40628175 Free PMC article.
References
-
- Marshall I.J., Nye B., Kuiper J., Noel-Storr A., Marshall R., Maclean R., Soboczenski F., Nenkova A., Thomas J., Wallace B.C. Trialstreamer: A living, automatically updated database of clinical trial reports. J. Am. Med. Inform. Assoc. 2020;27:1903–1912. doi: 10.1093/jamia/ocaa163. - DOI - PMC - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
