

Striatal Dopamine Signals and Reward Learning
- PMID: 37841525
- PMCID: PMC10572094
- DOI: 10.1093/function/zqad056
Striatal Dopamine Signals and Reward Learning
Abstract
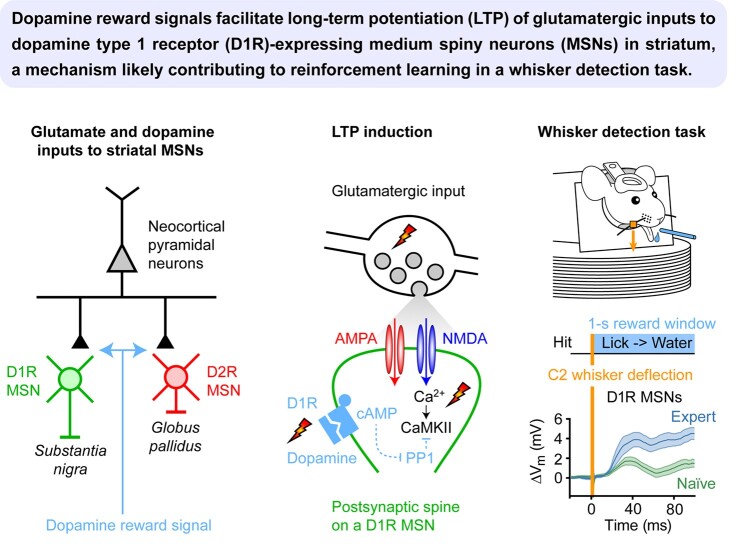
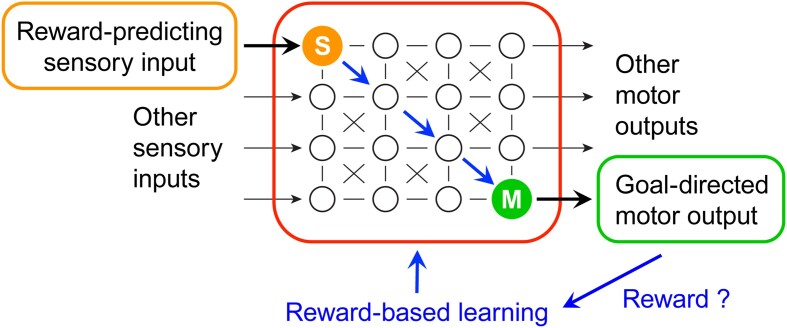
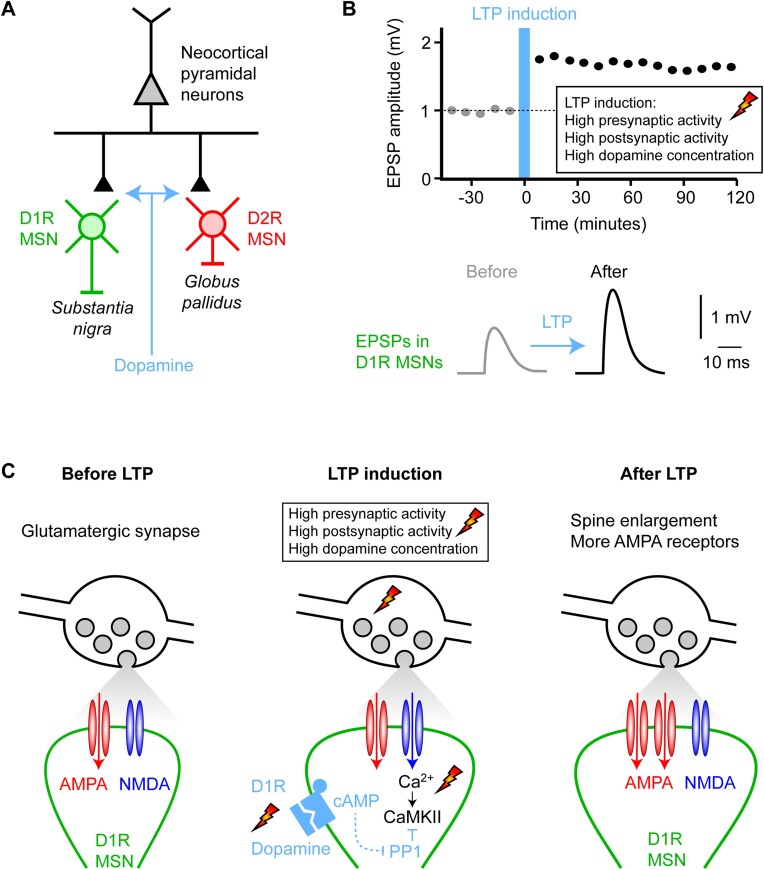
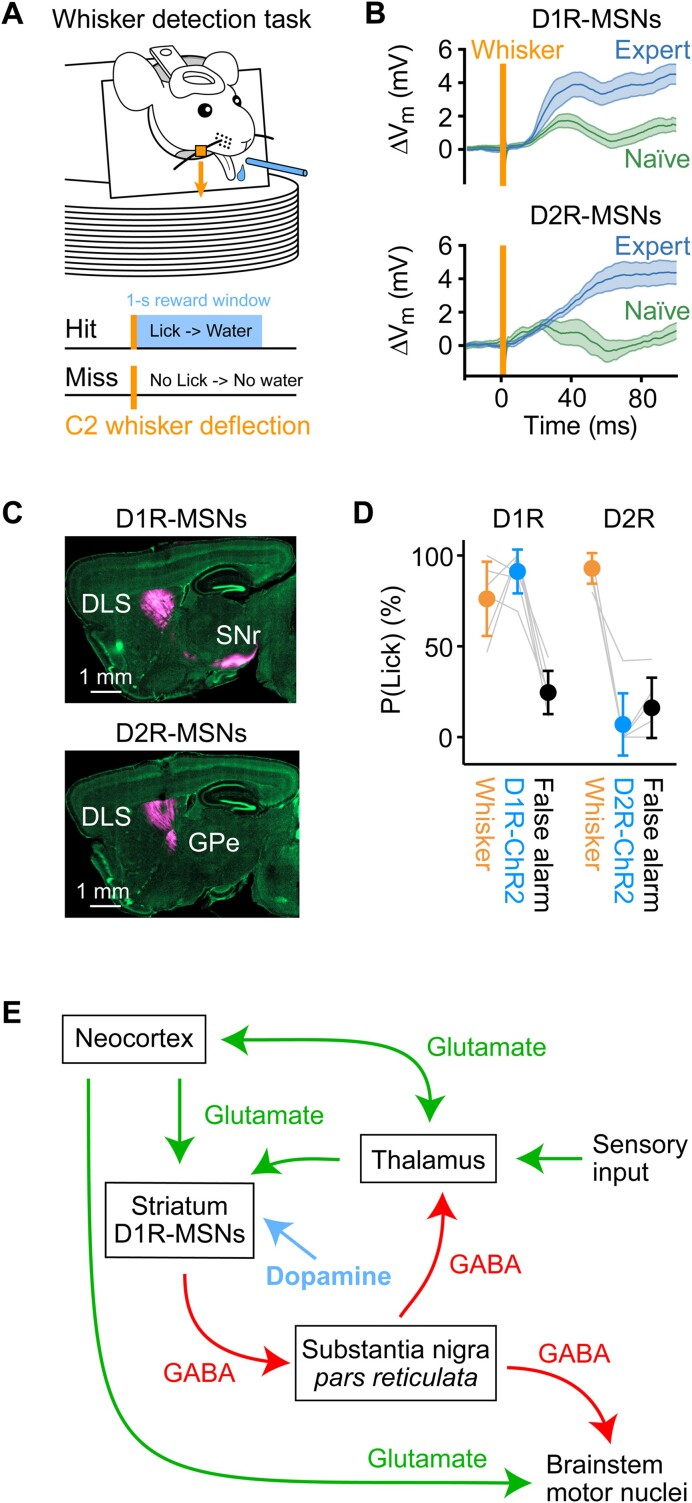
We are constantly bombarded by sensory information and constantly making decisions on how to act. In order to optimally adapt behavior, we must judge which sequences of sensory inputs and actions lead to successful outcomes in specific circumstances. Neuronal circuits of the basal ganglia have been strongly implicated in action selection, as well as the learning and execution of goal-directed behaviors, with accumulating evidence supporting the hypothesis that midbrain dopamine neurons might encode a reward signal useful for learning. Here, we review evidence suggesting that midbrain dopaminergic neurons signal reward prediction error, driving synaptic plasticity in the striatum underlying learning. We focus on phasic increases in action potential firing of midbrain dopamine neurons in response to unexpected rewards. These dopamine neurons prominently innervate the dorsal and ventral striatum. In the striatum, the released dopamine binds to dopamine receptors, where it regulates the plasticity of glutamatergic synapses. The increase of striatal dopamine accompanying an unexpected reward activates dopamine type 1 receptors (D1Rs) initiating a signaling cascade that promotes long-term potentiation of recently active glutamatergic input onto striatonigral neurons. Sensorimotor-evoked glutamatergic input, which is active immediately before reward delivery will thus be strengthened onto neurons in the striatum expressing D1Rs. In turn, these neurons cause disinhibition of brainstem motor centers and disinhibition of the motor thalamus, thus promoting motor output to reinforce rewarded stimulus-action outcomes. Although many details of the hypothesis need further investigation, altogether, it seems likely that dopamine signals in the striatum might underlie important aspects of goal-directed reward-based learning.
Keywords: Reward-based learning; dopamine; goal-directed behavior; licking; motor control; neuronal circuits; sensory processing; striatum; synaptic plasticity; whisker sensory perception.
© The Author(s) 2023. Published by Oxford University Press on behalf of American Physiological Society.
Conflict of interest statement
C.C.H.P. holds the position of Editorial Board Member for FUNCTION and is blinded from reviewing or making decisions for the manuscript.
Figures

References
-
- Sutton RS. Learning to predict by the methods of temporal differences. Mach Learn. 1988;3(1):9–44.
-
- Sutton RS, Barto AG. Time-derivative models of Pavlovian reinforcement. In: Learning and Computational Neuroscience: Foundations of Adaptive Networks, Cambridge, Massachusetts, The MIT Press, 1990:497–537.
-
- Bush RR, Mosteller F. A mathematical model for simple learning. Psychol Rev. 1951;58(5):313–323. - PubMed
-
- Bush RR, Mosteller F. A model for stimulus generalization and discrimination. Psychol Rev. 1951;58(6):413–423. - PubMed
-
- Rescorla RA, Wagner AR. A theory of Pavlovian conditioning: variations in the effectiveness of reinforcement and nonreinforcement. In:Classical Conditioning II: Current Research and Theory. Vol 2. New York, NY:Appleton-Century-Crofts, 1972:64–99.
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources