

Model metamers reveal divergent invariances between biological and artificial neural networks
- PMID: 37845543
- PMCID: PMC10620097
- DOI: 10.1038/s41593-023-01442-0
Model metamers reveal divergent invariances between biological and artificial neural networks
Abstract
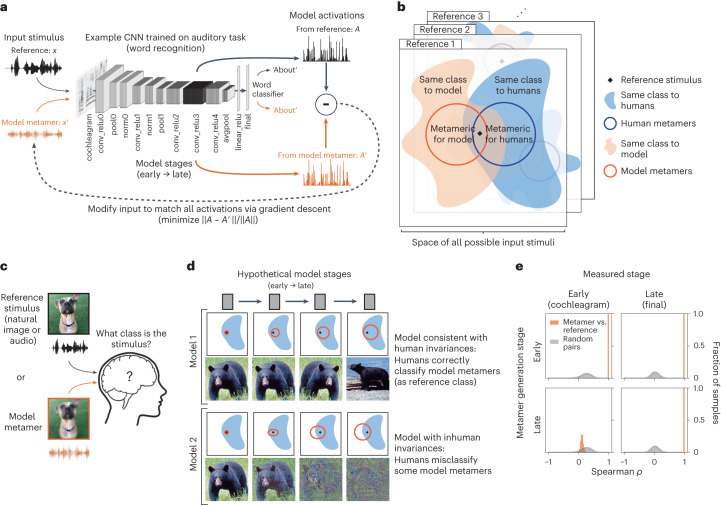
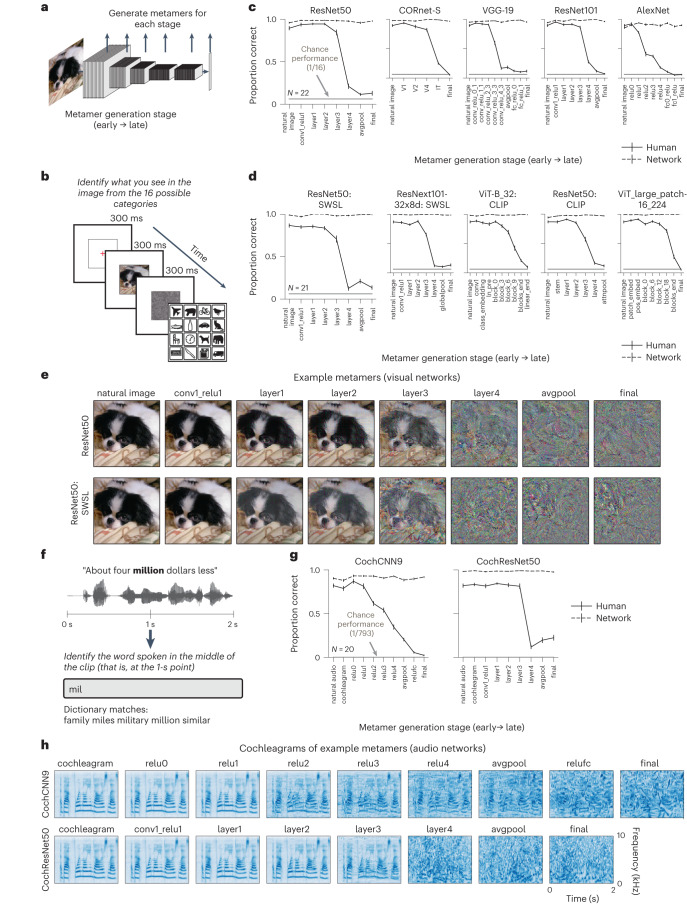
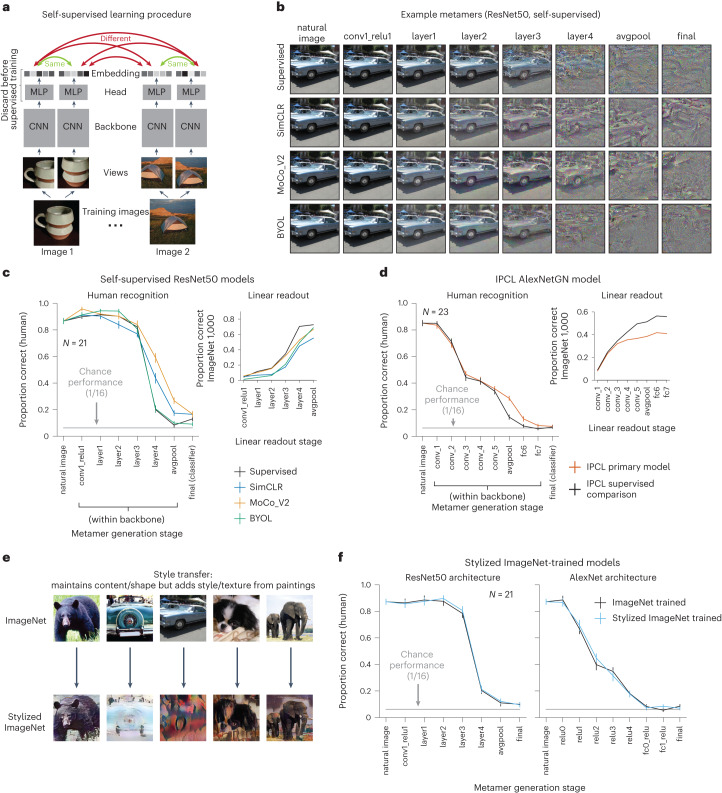
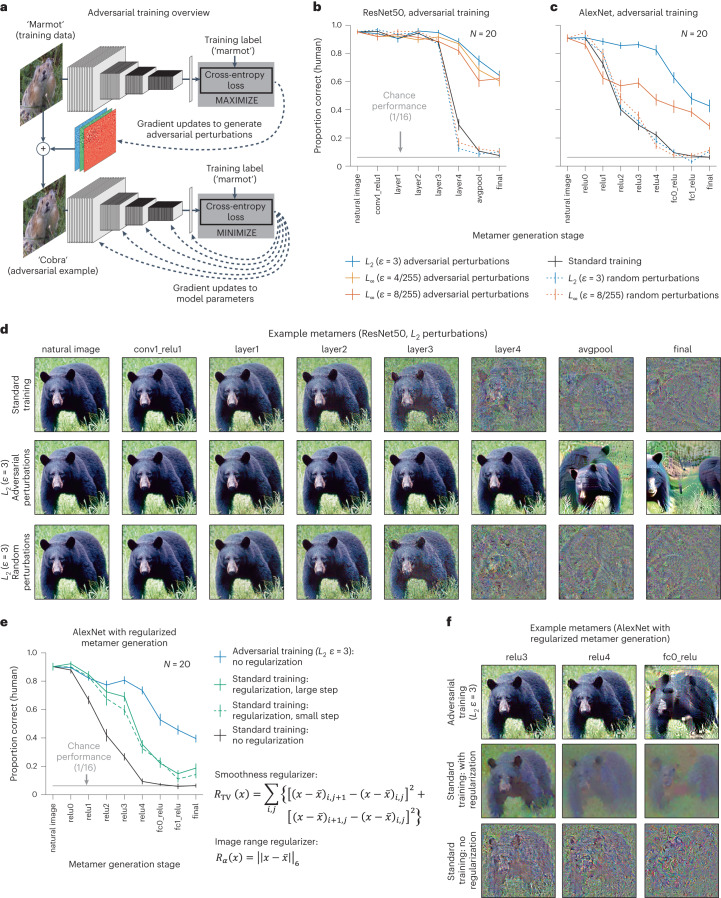
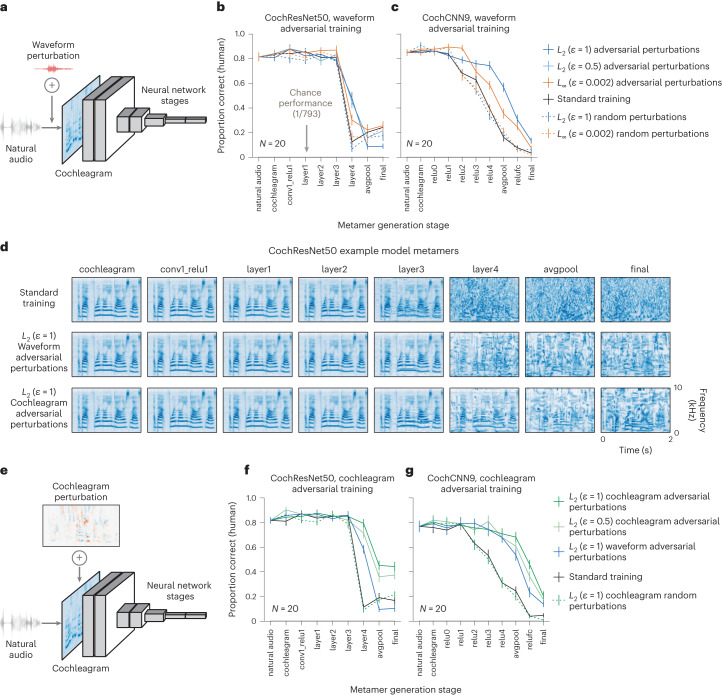
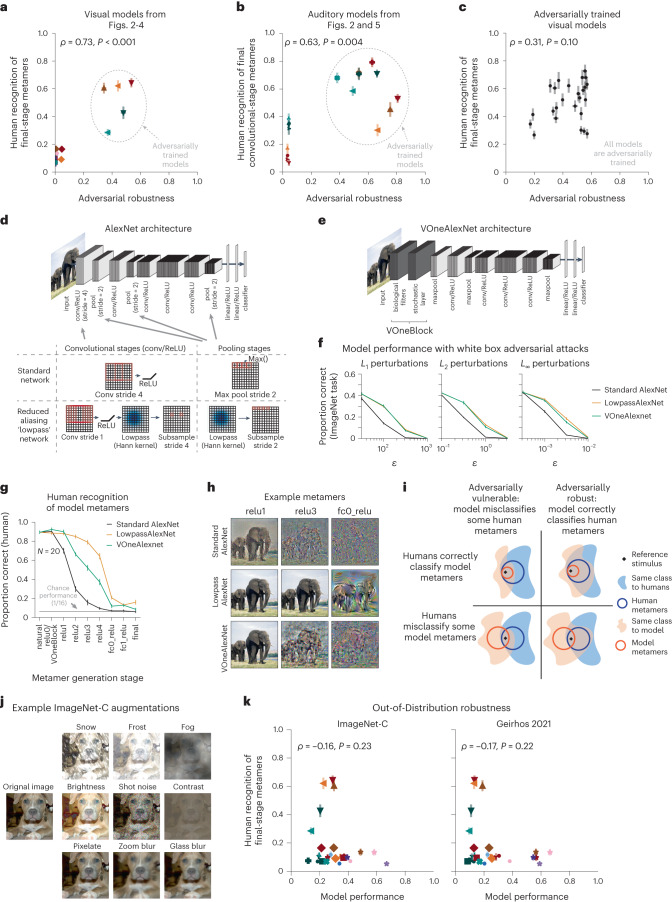
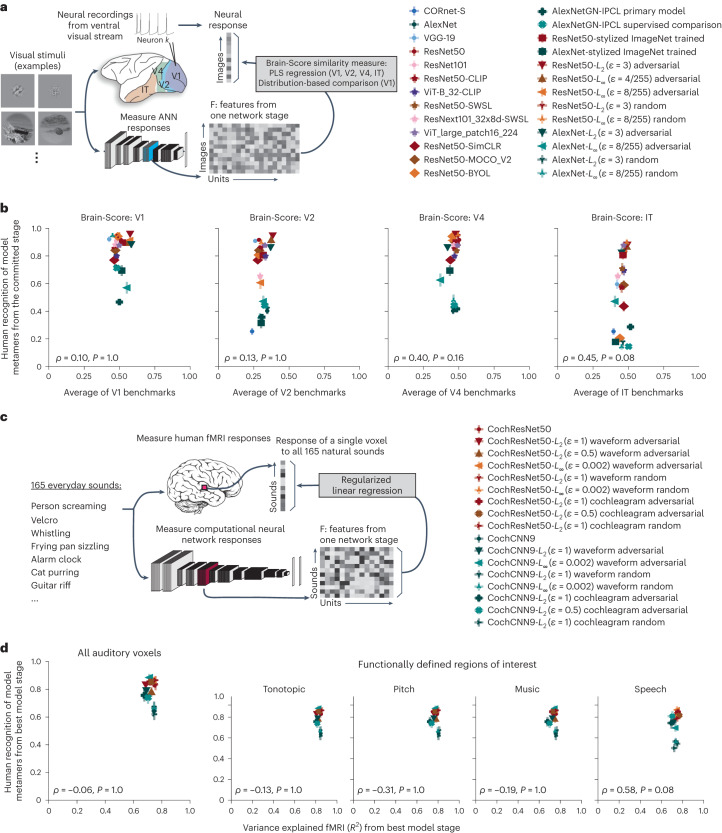
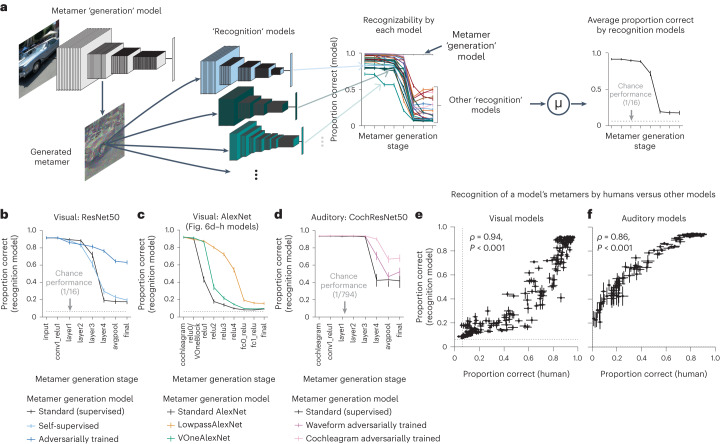
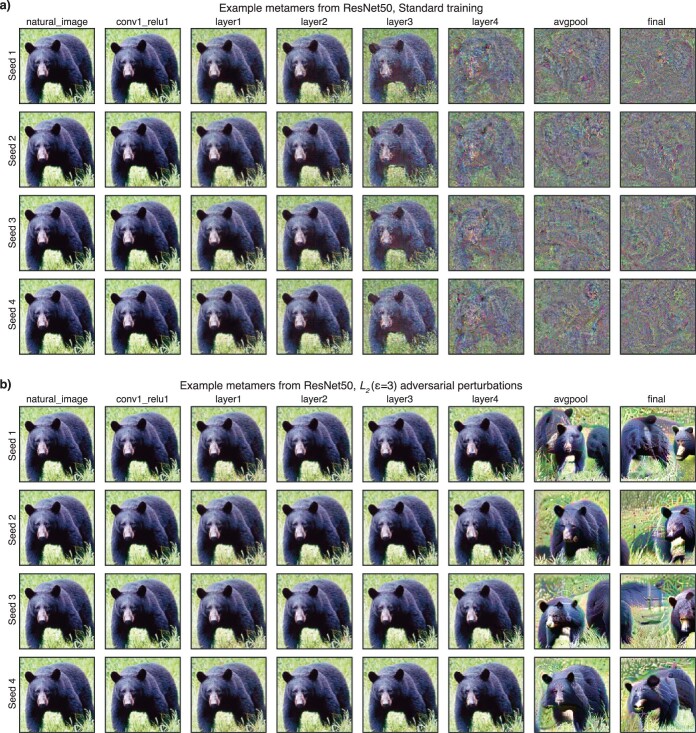
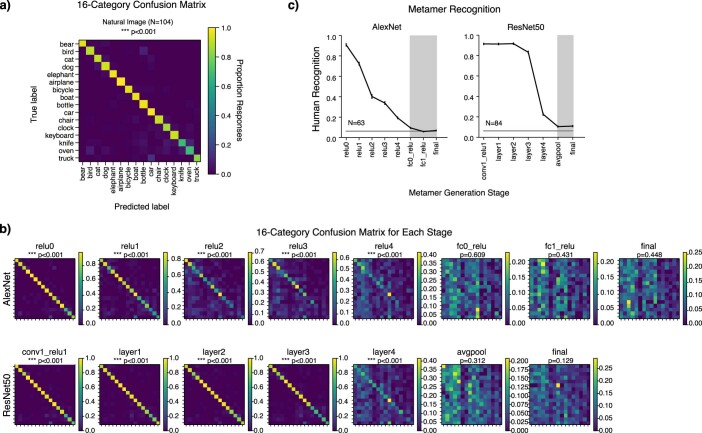
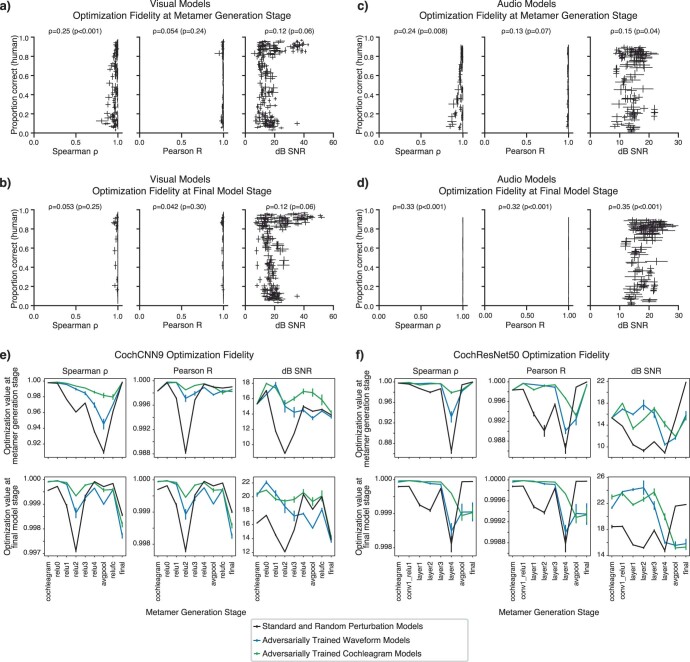
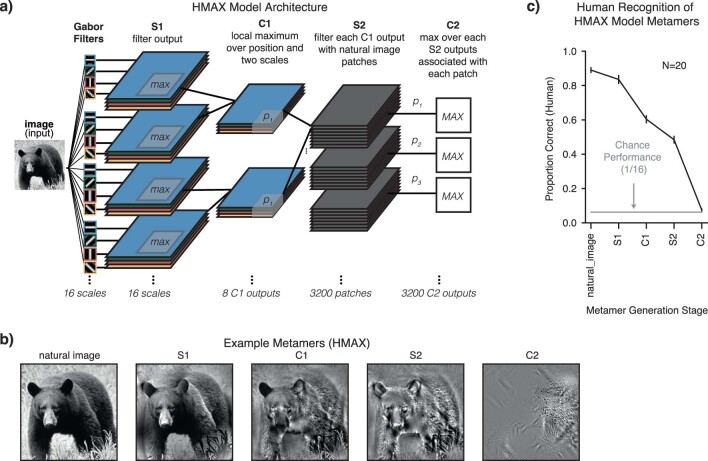
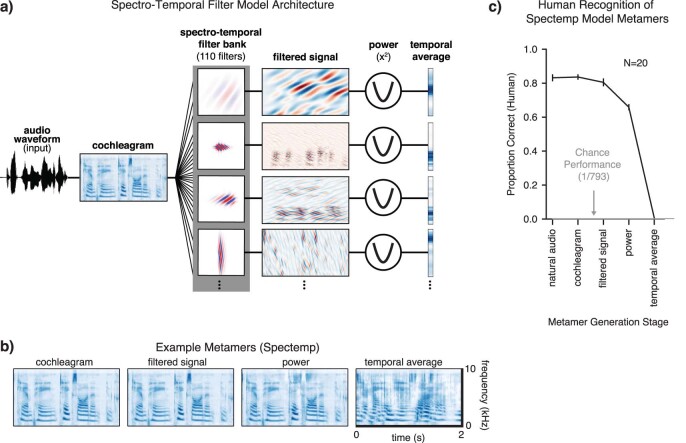
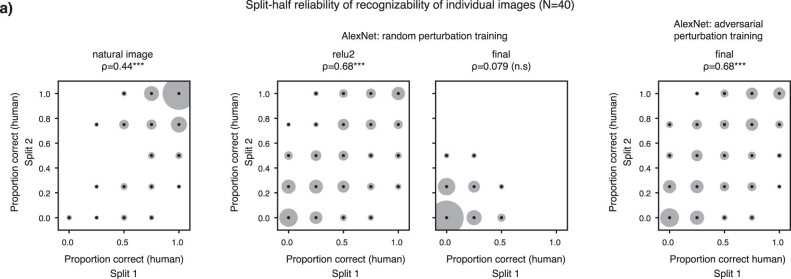
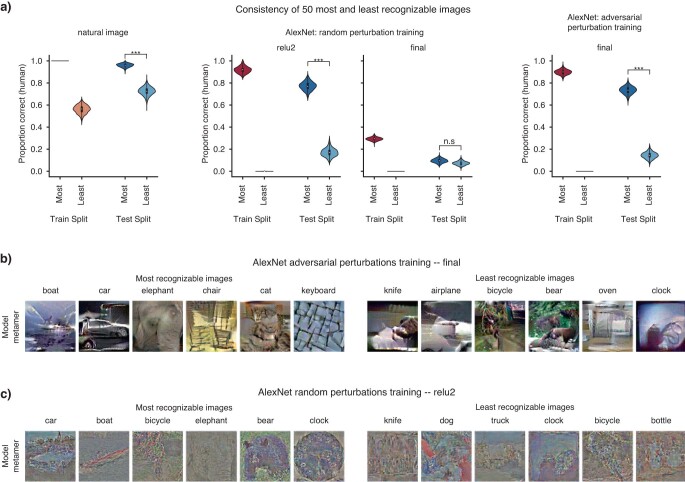
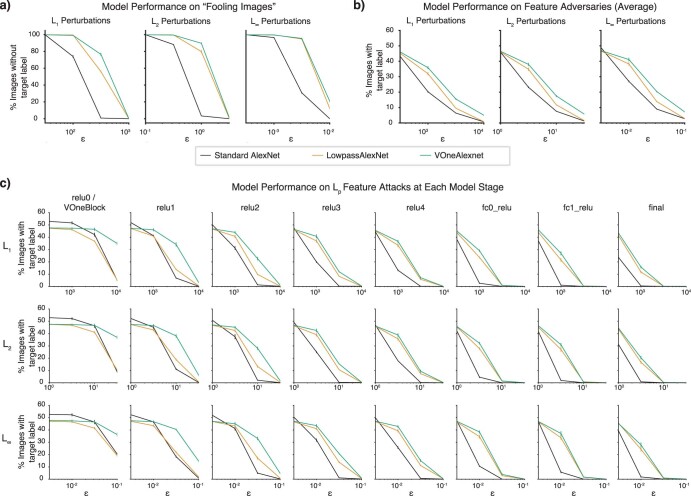
Deep neural network models of sensory systems are often proposed to learn representational transformations with invariances like those in the brain. To reveal these invariances, we generated 'model metamers', stimuli whose activations within a model stage are matched to those of a natural stimulus. Metamers for state-of-the-art supervised and unsupervised neural network models of vision and audition were often completely unrecognizable to humans when generated from late model stages, suggesting differences between model and human invariances. Targeted model changes improved human recognizability of model metamers but did not eliminate the overall human-model discrepancy. The human recognizability of a model's metamers was well predicted by their recognizability by other models, suggesting that models contain idiosyncratic invariances in addition to those required by the task. Metamer recognizability dissociated from both traditional brain-based benchmarks and adversarial vulnerability, revealing a distinct failure mode of existing sensory models and providing a complementary benchmark for model assessment.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures

References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
