

TextNetTopics Pro, a topic model-based text classification for short text by integration of semantic and document-topic distribution information
- PMID: 37867598
- PMCID: PMC10585361
- DOI: 10.3389/fgene.2023.1243874
TextNetTopics Pro, a topic model-based text classification for short text by integration of semantic and document-topic distribution information
Abstract
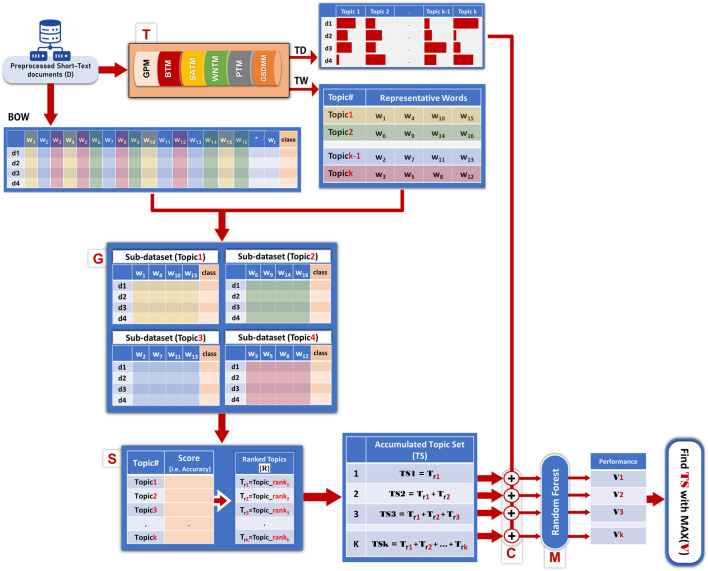
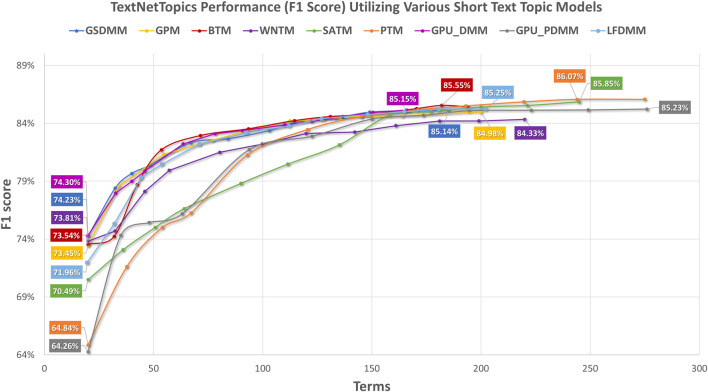
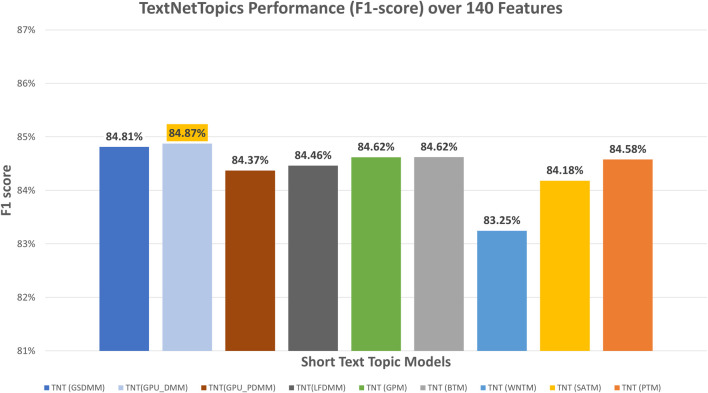
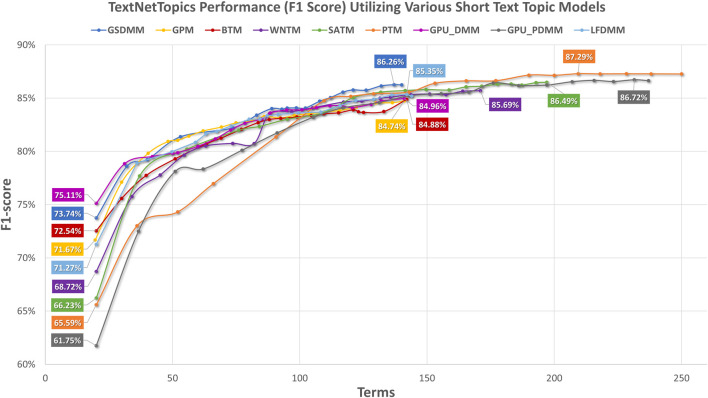
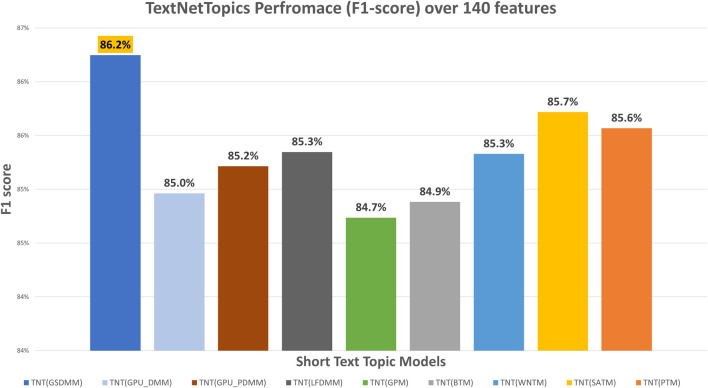
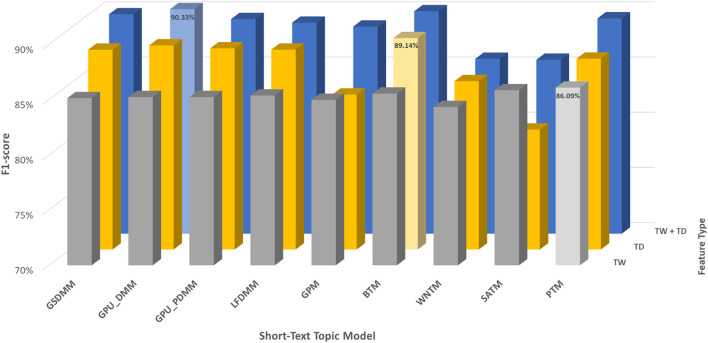
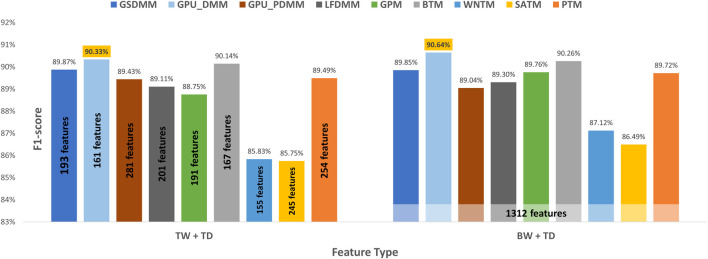
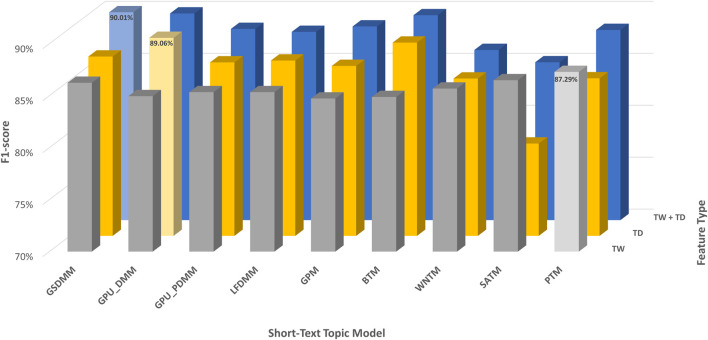
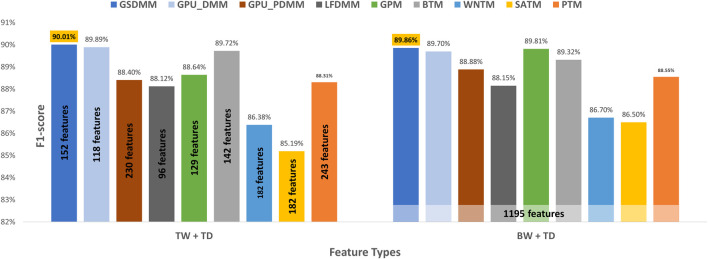
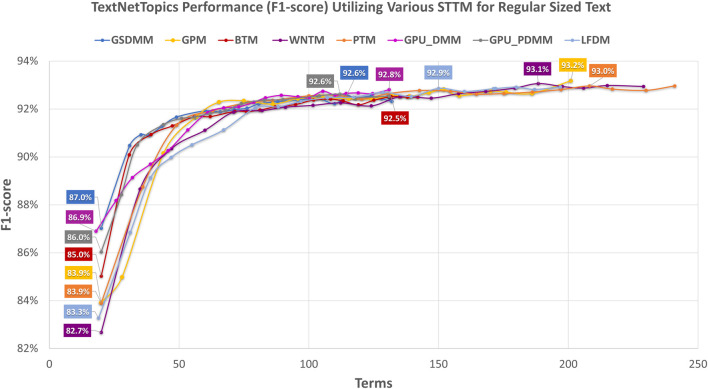
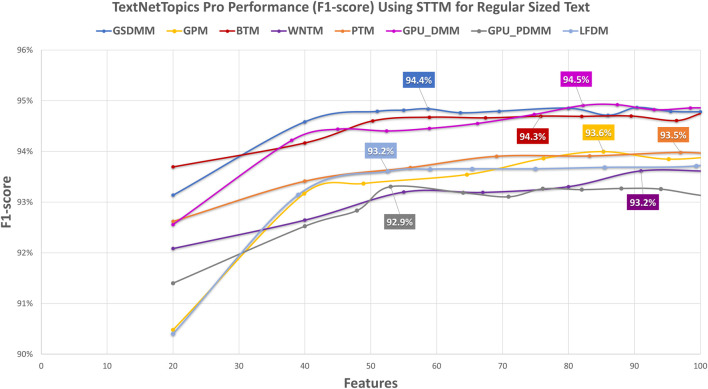
With the exponential growth in the daily publication of scientific articles, automatic classification and categorization can assist in assigning articles to a predefined category. Article titles are concise descriptions of the articles' content with valuable information that can be useful in document classification and categorization. However, shortness, data sparseness, limited word occurrences, and the inadequate contextual information of scientific document titles hinder the direct application of conventional text mining and machine learning algorithms on these short texts, making their classification a challenging task. This study firstly explores the performance of our earlier study, TextNetTopics on the short text. Secondly, here we propose an advanced version called TextNetTopics Pro, which is a novel short-text classification framework that utilizes a promising combination of lexical features organized in topics of words and topic distribution extracted by a topic model to alleviate the data-sparseness problem when classifying short texts. We evaluate our proposed approach using nine state-of-the-art short-text topic models on two publicly available datasets of scientific article titles as short-text documents. The first dataset is related to the Biomedical field, and the other one is related to Computer Science publications. Additionally, we comparatively evaluate the predictive performance of the models generated with and without using the abstracts. Finally, we demonstrate the robustness and effectiveness of the proposed approach in handling the imbalanced data, particularly in the classification of Drug-Induced Liver Injury articles as part of the CAMDA challenge. Taking advantage of the semantic information detected by topic models proved to be a reliable way to improve the overall performance of ML classifiers.
Keywords: feature selection; short text; sparse data; text classification; topic modeling; topic projection; topic selection.
Copyright © 2023 Voskergian, Bakir-Gungor and Yousef.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
Similar articles
-
Topic selection for text classification using ensemble topic modeling with grouping, scoring, and modeling approach.Sci Rep. 2024 Oct 9;14(1):23516. doi: 10.1038/s41598-024-74022-2. Sci Rep. 2024. PMID: 39384798 Free PMC article.
-
TextNetTopics: Text Classification Based Word Grouping as Topics and Topics' Scoring.Front Genet. 2022 Jun 20;13:893378. doi: 10.3389/fgene.2022.893378. eCollection 2022. Front Genet. 2022. PMID: 35795215 Free PMC article.
-
Large scale biomedical texts classification: a kNN and an ESA-based approaches.J Biomed Semantics. 2016 Jun 16;7:40. doi: 10.1186/s13326-016-0073-1. J Biomed Semantics. 2016. PMID: 27312781 Free PMC article.
-
Investigating the Efficient Use of Word Embedding with Neural-Topic Models for Interpretable Topics from Short Texts.Sensors (Basel). 2022 Jan 23;22(3):852. doi: 10.3390/s22030852. Sensors (Basel). 2022. PMID: 35161598 Free PMC article.
-
An overview of topic modeling and its current applications in bioinformatics.Springerplus. 2016 Sep 20;5(1):1608. doi: 10.1186/s40064-016-3252-8. eCollection 2016. Springerplus. 2016. PMID: 27652181 Free PMC article. Review.
Cited by
-
Topic selection for text classification using ensemble topic modeling with grouping, scoring, and modeling approach.Sci Rep. 2024 Oct 9;14(1):23516. doi: 10.1038/s41598-024-74022-2. Sci Rep. 2024. PMID: 39384798 Free PMC article.
-
RCE-IFE: recursive cluster elimination with intra-cluster feature elimination.PeerJ Comput Sci. 2025 Feb 7;11:e2528. doi: 10.7717/peerj-cs.2528. eCollection 2025. PeerJ Comput Sci. 2025. PMID: 40062294 Free PMC article.
References
-
- Al Qundus J., Paschke A., Gupta S., Alzouby A. M., Yousef M. (2020). Exploring the impact of short-text complexity and structure on its quality in social media. JEIM 33 (6), 1443–1466. 10.1108/JEIM-06-2019-0156 - DOI
-
- Alsmadi I., Gan K. H. (2019). Review of short-text classification. IJWIS 15 (2), 155–182. 10.1108/IJWIS-12-2017-0083 - DOI
-
- arXiv Paper Abstracts (2022). arXiv paper abstracts. Available at: https://www.kaggle.com/datasets/spsayakpaul/arxiv-paper-abstracts (Accessed January 27 2023).
-
- Bagheri A., Sammani A., van der Heijden P. G. M., Asselbergs F. W., Oberski D. L. (2020). Etm: enrichment by topic modeling for automated clinical sentence classification to detect patients’ disease history. J. Intell. Inf. Syst. 55, 329–349. 10.1007/s10844-020-00605-w - DOI
-
- Barde B. V., Bainwad A. M. (2017). “An overview of topic modeling methods and tools,” in Proceeding of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, June 2017 (IEEE; ), 745–750. 10.1109/ICCONS.2017.8250563 - DOI
LinkOut - more resources
Full Text Sources