

This is a preprint.
A Large Language Model-Based Generative Natural Language Processing Framework Finetuned on Clinical Notes Accurately Extracts Headache Frequency from Electronic Health Records
- PMID: 37873417
- PMCID: PMC10593021
- DOI: 10.1101/2023.10.02.23296403
A Large Language Model-Based Generative Natural Language Processing Framework Finetuned on Clinical Notes Accurately Extracts Headache Frequency from Electronic Health Records
Update in
-
A large language model-based generative natural language processing framework fine-tuned on clinical notes accurately extracts headache frequency from electronic health records.Headache. 2024 Apr;64(4):400-409. doi: 10.1111/head.14702. Epub 2024 Mar 25. Headache. 2024. PMID: 38525734 Free PMC article.
Abstract
Background: Headache frequency, defined as the number of days with any headache in a month (or four weeks), remains a key parameter in the evaluation of treatment response to migraine preventive medications. However, due to the variations and inconsistencies in documentation by clinicians, significant challenges exist to accurately extract headache frequency from the electronic health record (EHR) by traditional natural language processing (NLP) algorithms.
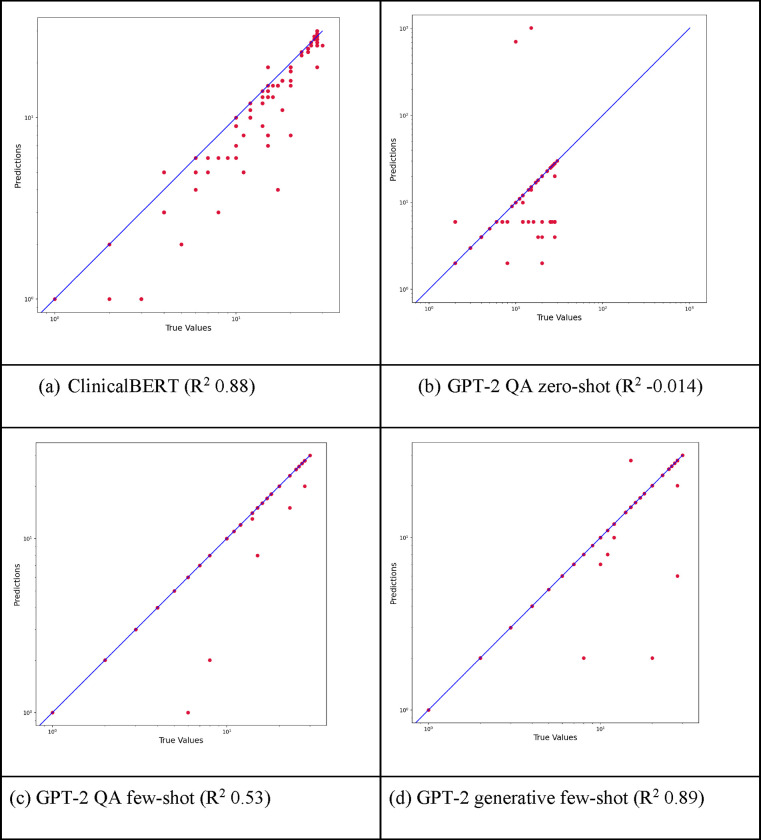
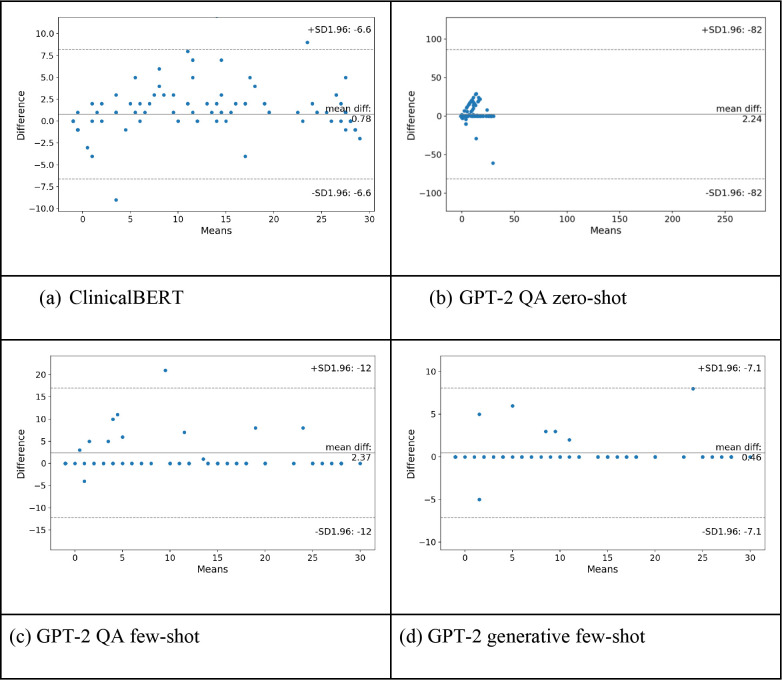
Methods: This was a retrospective cross-sectional study with human subjects identified from three tertiary headache referral centers- Mayo Clinic Arizona, Florida, and Rochester. All neurology consultation notes written by more than 10 headache specialists between 2012 to 2022 were extracted and 1915 notes were used for model fine-tuning (90%) and testing (10%). We employed four different NLP frameworks: (1) ClinicalBERT (Bidirectional Encoder Representations from Transformers) regression model (2) Generative Pre-Trained Transformer-2 (GPT-2) Question Answering (QA) Model zero-shot (3) GPT-2 QA model few-shot training fine-tuned on Mayo Clinic notes; and (4) GPT-2 generative model few-shot training fine-tuned on Mayo Clinic notes to generate the answer by considering the context of included text.
Results: The GPT-2 generative model was the best-performing model with an accuracy of 0.92[0.91 - 0.93] and R2 score of 0.89[0.87, 0.9], and all GPT2-based models outperformed the ClinicalBERT model in terms of the exact matching accuracy. Although the ClinicalBERT regression model had the lowest accuracy 0.27[0.26 - 0.28], it demonstrated a high R2 score 0.88[0.85, 0.89], suggesting the ClinicalBERT model can reasonably predict the headache frequency within a range of ≤ ± 3 days, and the R2 score was higher than the GPT-2 QA zero-shot model or GPT-2 QA model few-shot training fine-tuned model.
Conclusion: We developed a robust model based on a state-of-the-art large language model (LLM)- a GPT-2 generative model that can extract headache frequency from EHR free-text clinical notes with high accuracy and R2 score. It overcame several challenges related to different ways clinicians document headache frequency that were not easily achieved by traditional NLP models. We also showed that GPT2-based frameworks outperformed ClinicalBERT in terms of accuracy in extracting headache frequency from clinical notes. To facilitate research in the field, we released the GPT-2 generative model and inference code with open-source license of community use in GitHub.
Keywords: artificial intelligence; headache frequency; large language model; migraine; natural language processing.
Figures

Similar articles
-
A large language model-based generative natural language processing framework fine-tuned on clinical notes accurately extracts headache frequency from electronic health records.Headache. 2024 Apr;64(4):400-409. doi: 10.1111/head.14702. Epub 2024 Mar 25. Headache. 2024. PMID: 38525734 Free PMC article.
-
Zero-Shot Extraction of Seizure Outcomes from Clinical Notes Using Generative Pretrained Transformers.J Healthc Inform Res. 2025 Apr 29;9(3):380-400. doi: 10.1007/s41666-025-00198-5. eCollection 2025 Sep. J Healthc Inform Res. 2025. PMID: 40726746 Free PMC article.
-
Few-Shot Learning for Clinical Natural Language Processing Using Siamese Neural Networks: Algorithm Development and Validation Study.JMIR AI. 2023 May 4;2:e44293. doi: 10.2196/44293. JMIR AI. 2023. PMID: 38875537 Free PMC article.
-
New meaning for NLP: the trials and tribulations of natural language processing with GPT-3 in ophthalmology.Br J Ophthalmol. 2022 Jul;106(7):889-892. doi: 10.1136/bjophthalmol-2022-321141. Epub 2022 May 6. Br J Ophthalmol. 2022. PMID: 35523534 Review.
-
Advancing rheumatology with natural language processing: insights and prospects from a systematic review.Rheumatol Adv Pract. 2024 Sep 19;8(4):rkae120. doi: 10.1093/rap/rkae120. eCollection 2024. Rheumatol Adv Pract. 2024. PMID: 39399162 Free PMC article. Review.
Cited by
-
Mobile App-Based Interactive Care Plan for Migraine: Survey Study of Usability and Improvement Opportunities.JMIR Form Res. 2025 Mar 26;9:e66763. doi: 10.2196/66763. JMIR Form Res. 2025. PMID: 40143383 Free PMC article.
References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources