

Research on automatic pilot repetition generation method based on deep reinforcement learning
- PMID: 37885770
- PMCID: PMC10598579
- DOI: 10.3389/fnbot.2023.1285831
Research on automatic pilot repetition generation method based on deep reinforcement learning
Abstract
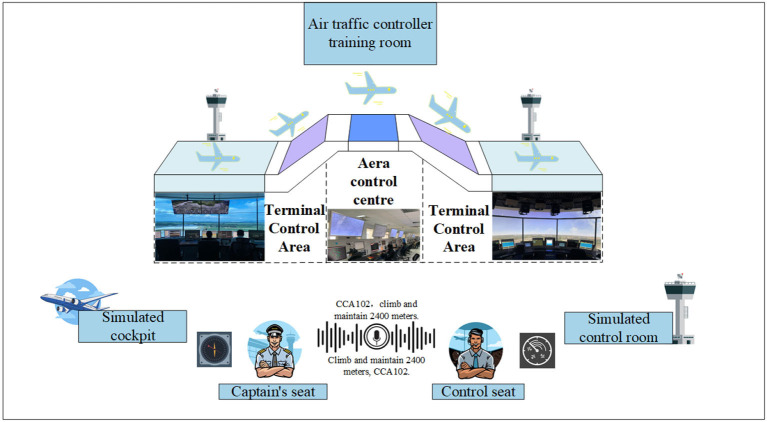
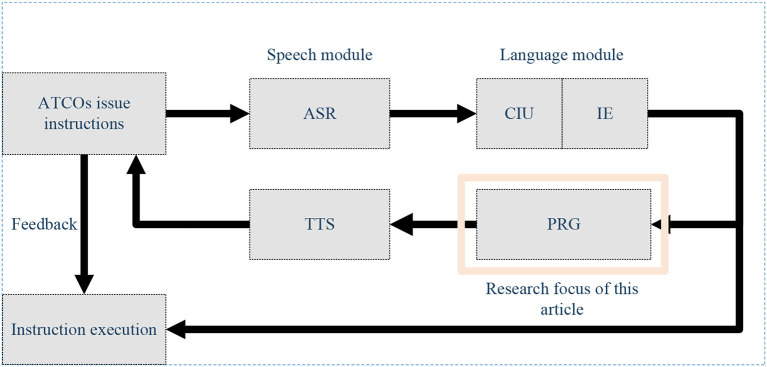
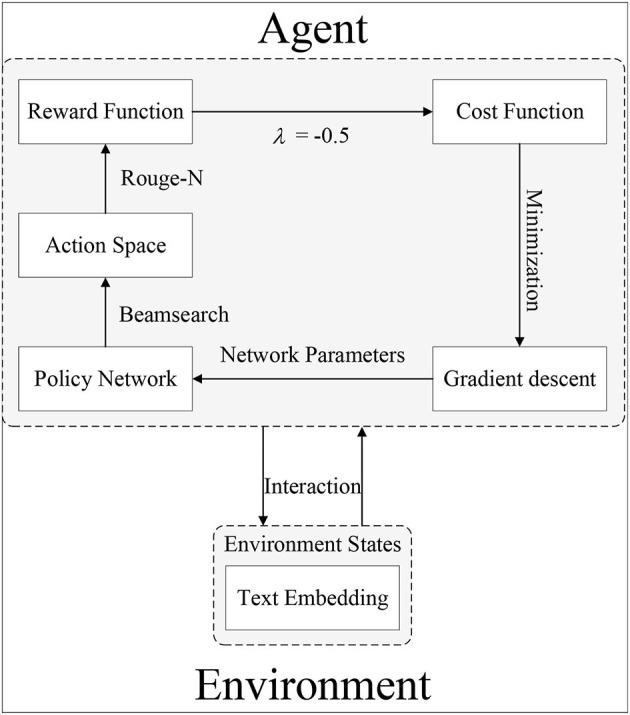
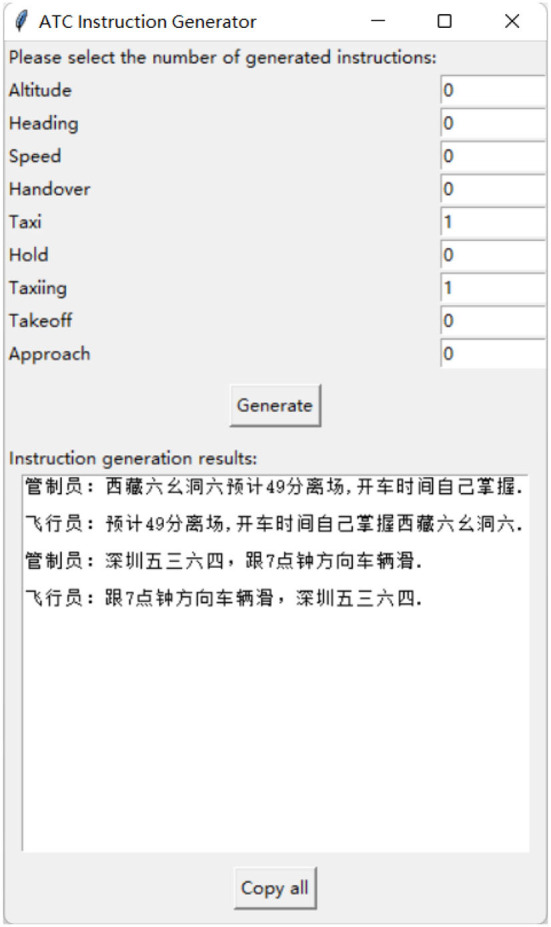
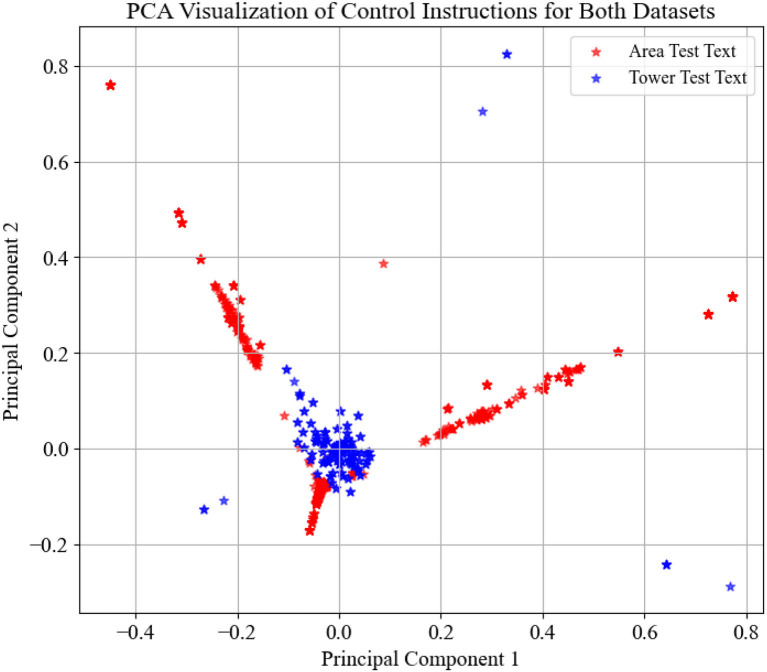
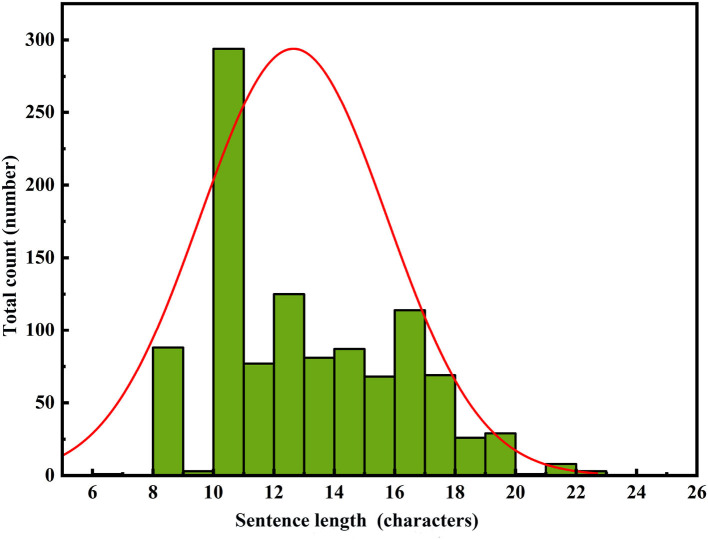
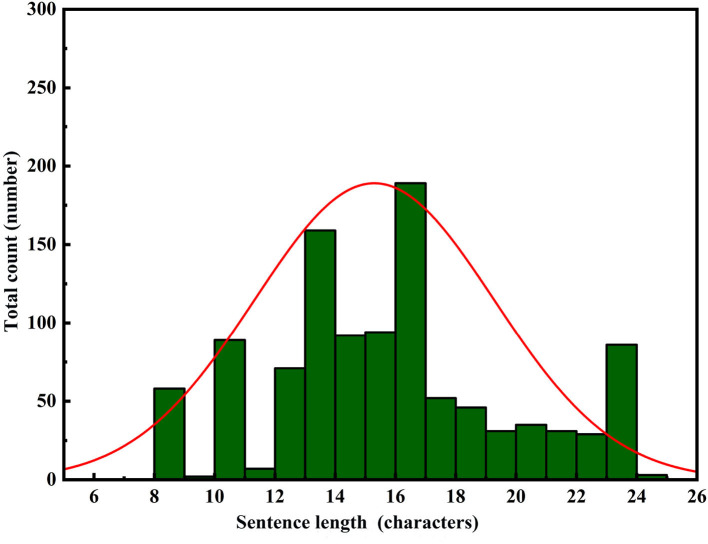
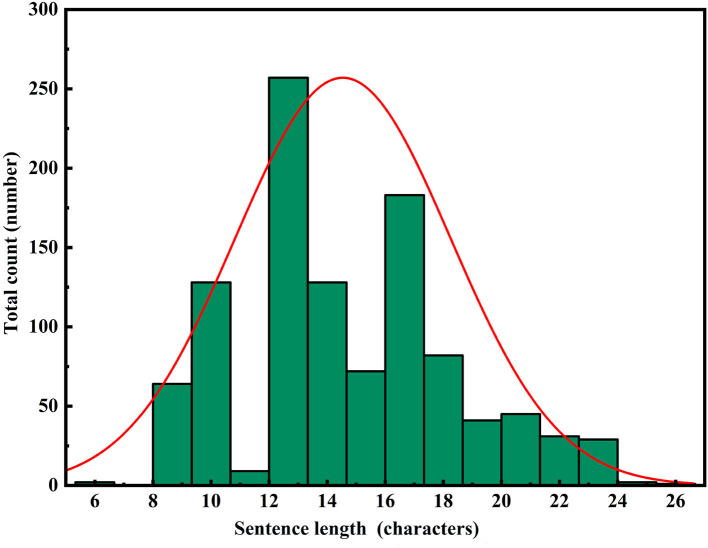
Using computers to replace pilot seats in air traffic control (ATC) simulators is an effective way to improve controller training efficiency and reduce training costs. To achieve this, we propose a deep reinforcement learning model, RoBERTa-RL (RoBERTa with Reinforcement Learning), for generating pilot repetitions. RoBERTa-RL is based on the pre-trained language model RoBERTa and is optimized through transfer learning and reinforcement learning. Transfer learning is used to address the issue of scarce data in the ATC domain, while reinforcement learning algorithms are employed to optimize the RoBERTa model and overcome the limitations in model generalization caused by transfer learning. We selected a real-world area control dataset as the target task training and testing dataset, and a tower control dataset generated based on civil aviation radio land-air communication rules as the test dataset for evaluating model generalization. In terms of the ROUGE evaluation metrics, RoBERTa-RL achieved significant results on the area control dataset with ROUGE-1, ROUGE-2, and ROUGE-L scores of 0.9962, 0.992, and 0.996, respectively. On the tower control dataset, the scores were 0.982, 0.954, and 0.982, respectively. To overcome the limitations of ROUGE in this field, we conducted a detailed evaluation of the proposed model architecture using keyword-based evaluation criteria for the generated repetition instructions. This evaluation criterion calculates various keyword-based metrics based on the segmented results of the repetition instruction text. In the keyword-based evaluation criteria, the constructed model achieved an overall accuracy of 98.8% on the area control dataset and 81.8% on the tower control dataset. In terms of generalization, RoBERTa-RL improved accuracy by 56% compared to the model before improvement and achieved a 47.5% improvement compared to various comparative models. These results indicate that employing reinforcement learning strategies to enhance deep learning algorithms can effectively mitigate the issue of poor generalization in text generation tasks, and this approach holds promise for future application in other related domains.
Keywords: controller training; generalization; reinforcement learning; text generation; transfer learning.
Copyright © 2023 Pan, Jiang, Li, Wang and Huang.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
Similar articles
-
Study on the standardization method of radiotelephony communication in low-altitude airspace based on BART.Front Neurorobot. 2025 Apr 2;19:1482327. doi: 10.3389/fnbot.2025.1482327. eCollection 2025. Front Neurorobot. 2025. PMID: 40242556 Free PMC article.
-
Emotion-Aware RoBERTa enhanced with emotion-specific attention and TF-IDF gating for fine-grained emotion recognition.Sci Rep. 2025 May 21;15(1):17617. doi: 10.1038/s41598-025-99515-6. Sci Rep. 2025. PMID: 40399457 Free PMC article.
-
Improving Radiology Report Generation Quality and Diversity through Reinforcement Learning and Text Augmentation.Bioengineering (Basel). 2024 Apr 3;11(4):351. doi: 10.3390/bioengineering11040351. Bioengineering (Basel). 2024. PMID: 38671773 Free PMC article.
-
Enhancing Air Traffic Control Communication Systems with Integrated Automatic Speech Recognition: Models, Applications and Performance Evaluation.Sensors (Basel). 2024 Jul 20;24(14):4715. doi: 10.3390/s24144715. Sensors (Basel). 2024. PMID: 39066111 Free PMC article. Review.
-
A Survey of Sim-to-Real Transfer Techniques Applied to Reinforcement Learning for Bioinspired Robots.IEEE Trans Neural Netw Learn Syst. 2023 Jul;34(7):3444-3459. doi: 10.1109/TNNLS.2021.3112718. Epub 2023 Jul 6. IEEE Trans Neural Netw Learn Syst. 2023. PMID: 34587101 Review.
Cited by
-
Assessment and analysis of accents in air traffic control speech: a fusion of deep learning and information theory.Front Neurorobot. 2024 Mar 5;18:1360094. doi: 10.3389/fnbot.2024.1360094. eCollection 2024. Front Neurorobot. 2024. PMID: 38505326 Free PMC article.
-
SLKIR: A framework for extracting key information from air traffic control instructions Using small sample learning.Sci Rep. 2024 Apr 29;14(1):9791. doi: 10.1038/s41598-024-60675-6. Sci Rep. 2024. PMID: 38684909 Free PMC article.
References
-
- Alexandr N., Irina O., Tatyana K., Inessa K., Arina P. (2021). Fine-tuning GPT-3 for Russian text summarization, in Data Science and Intelligent Systems: Proceedings of 5th Computational Methods in Systems and Software 2021 (Springer: ), 748–757.
-
- de Souza J. G., Kozielski M., Mathur P., Chang E., Guerini M., Negri M., et al. . (2018). Generating e-commerce product titles and predicting their quality, in Proceedings of the 11th International Conference on Natural Language Generation (IOP Publishing: ), 233–243.
-
- Devlin J., Chang M.-W., Lee K., Toutanova K. (2018). BERT: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
-
- Drayton J., Coxhead A. (2023). The development, evaluation and application of an aviation radiotelephony specialised technical vocabulary list. English Specific Purposes 69, 51–66. 10.1016/j.esp.2022.10.001 - DOI
-
- Elmadani K. N., Elgezouli M., Showk A. (2020). Bert fine-tuning for Arabic text summarization. arXiv preprint arXiv:2004.14135.
LinkOut - more resources
Full Text Sources
Research Materials