

Super-Resolved Dynamic 3D Reconstruction of the Vocal Tract during Natural Speech
- PMID: 37888339
- PMCID: PMC10607793
- DOI: 10.3390/jimaging9100233
Super-Resolved Dynamic 3D Reconstruction of the Vocal Tract during Natural Speech
Abstract
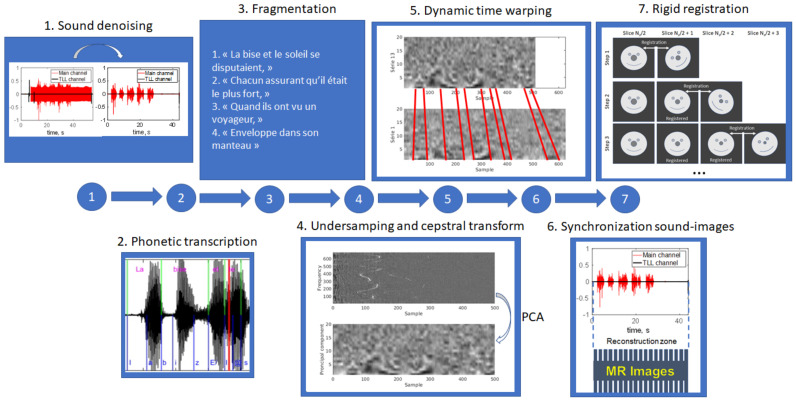
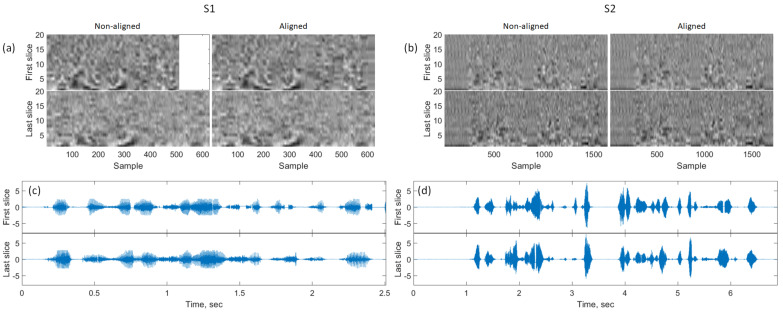
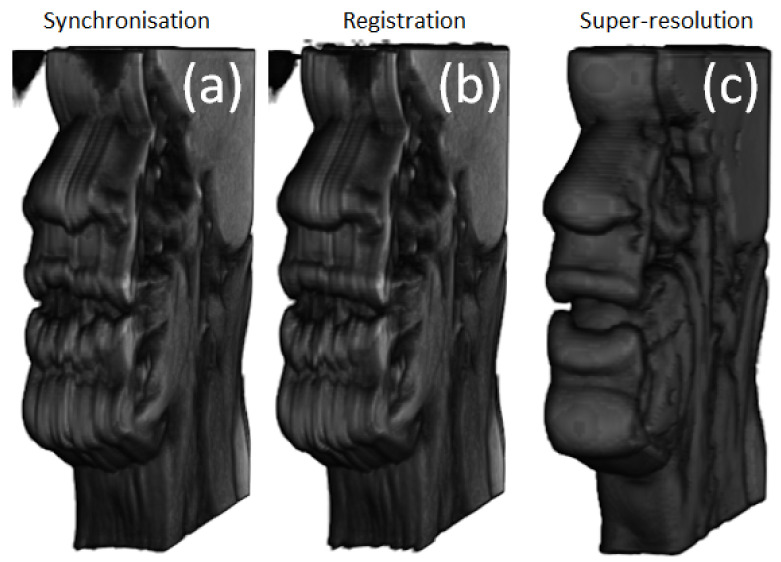
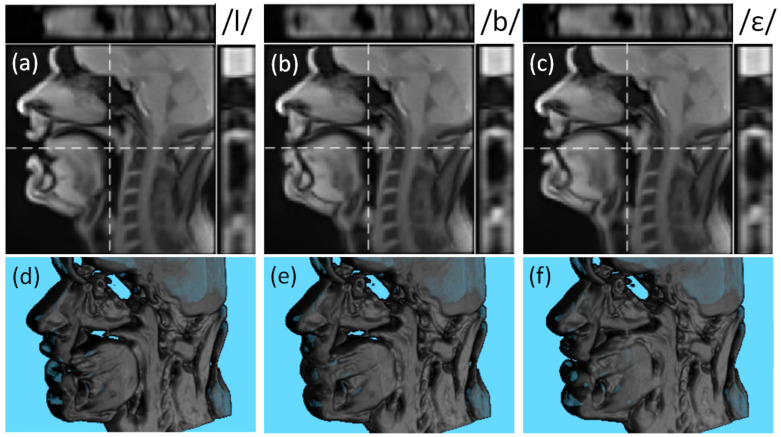
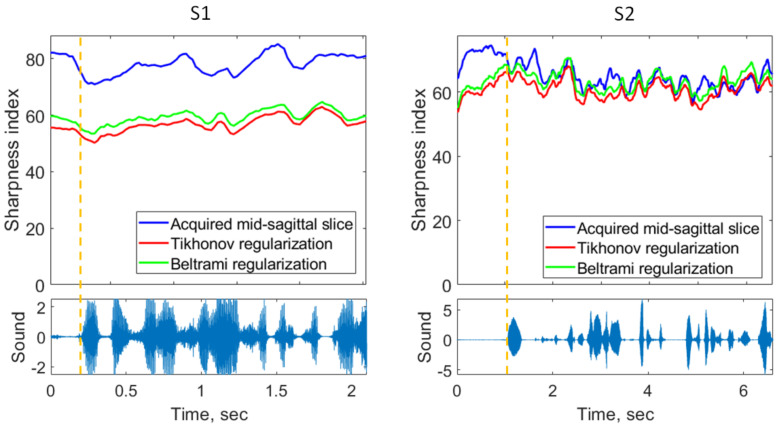
MRI is the gold standard modality for speech imaging. However, it remains relatively slow, which complicates imaging of fast movements. Thus, an MRI of the vocal tract is often performed in 2D. While 3D MRI provides more information, the quality of such images is often insufficient. The goal of this study was to test the applicability of super-resolution algorithms for dynamic vocal tract MRI. In total, 25 sagittal slices of 8 mm with an in-plane resolution of 1.6 × 1.6 mm2 were acquired consecutively using a highly-undersampled radial 2D FLASH sequence. The volunteers were reading a text in French with two different protocols. The slices were aligned using the simultaneously recorded sound. The super-resolution strategy was used to reconstruct 1.6 × 1.6 × 1.6 mm3 isotropic volumes. The resulting images were less sharp than the native 2D images but demonstrated a higher signal-to-noise ratio. It was also shown that the super-resolution allows for eliminating inconsistencies leading to regular transitions between the slices. Additionally, it was demonstrated that using visual stimuli and shorter text fragments improves the inter-slice consistency and the super-resolved image sharpness. Therefore, with a correct speech task choice, the proposed method allows for the reconstruction of high-quality dynamic 3D volumes of the vocal tract during natural speech.
Keywords: dynamic MRI; magnetic resonance imaging; speech; super-resolution; vocal tract.
Conflict of interest statement
The authors declare no conflict of interest.
Figures








References
-
- Badin P. Fricative Consonants: Acoustic and X-Ray Measurements. J. Phon. 1991;19:397–408. doi: 10.1016/S0095-4470(19)30331-6. - DOI
-
- Fabre D., Hueber T., Girin L., Alameda-Pineda X., Badin P. Automatic Animation of an Articulatory Tongue Model from Ultrasound Images of the Vocal Tract. Speech Commun. 2017;93:63–75. doi: 10.1016/j.specom.2017.08.002. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
