

Large Language Models for Therapy Recommendations Across 3 Clinical Specialties: Comparative Study
- PMID: 37902826
- PMCID: PMC10644179
- DOI: 10.2196/49324
Large Language Models for Therapy Recommendations Across 3 Clinical Specialties: Comparative Study
Abstract
Background: As advancements in artificial intelligence (AI) continue, large language models (LLMs) have emerged as promising tools for generating medical information. Their rapid adaptation and potential benefits in health care require rigorous assessment in terms of the quality, accuracy, and safety of the generated information across diverse medical specialties.
Objective: This study aimed to evaluate the performance of 4 prominent LLMs, namely, Claude-instant-v1.0, GPT-3.5-Turbo, Command-xlarge-nightly, and Bloomz, in generating medical content spanning the clinical specialties of ophthalmology, orthopedics, and dermatology.
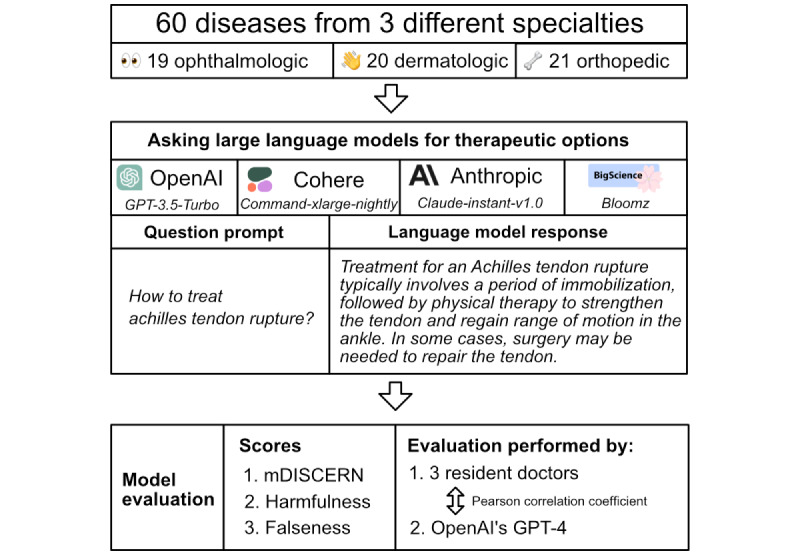
Methods: Three domain-specific physicians evaluated the AI-generated therapeutic recommendations for a diverse set of 60 diseases. The evaluation criteria involved the mDISCERN score, correctness, and potential harmfulness of the recommendations. ANOVA and pairwise t tests were used to explore discrepancies in content quality and safety across models and specialties. Additionally, using the capabilities of OpenAI's most advanced model, GPT-4, an automated evaluation of each model's responses to the diseases was performed using the same criteria and compared to the physicians' assessments through Pearson correlation analysis.
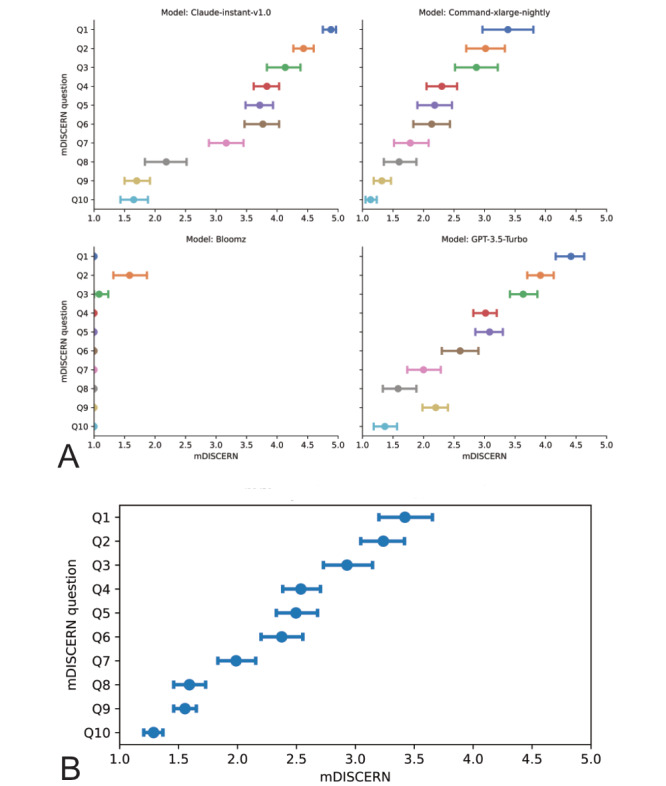
Results: Claude-instant-v1.0 emerged with the highest mean mDISCERN score (3.35, 95% CI 3.23-3.46). In contrast, Bloomz lagged with the lowest score (1.07, 95% CI 1.03-1.10). Our analysis revealed significant differences among the models in terms of quality (P<.001). Evaluating their reliability, the models displayed strong contrasts in their falseness ratings, with variations both across models (P<.001) and specialties (P<.001). Distinct error patterns emerged, such as confusing diagnoses; providing vague, ambiguous advice; or omitting critical treatments, such as antibiotics for infectious diseases. Regarding potential harm, GPT-3.5-Turbo was found to be the safest, with the lowest harmfulness rating. All models lagged in detailing the risks associated with treatment procedures, explaining the effects of therapies on quality of life, and offering additional sources of information. Pearson correlation analysis underscored a substantial alignment between physician assessments and GPT-4's evaluations across all established criteria (P<.01).
Conclusions: This study, while comprehensive, was limited by the involvement of a select number of specialties and physician evaluators. The straightforward prompting strategy ("How to treat…") and the assessment benchmarks, initially conceptualized for human-authored content, might have potential gaps in capturing the nuances of AI-driven information. The LLMs evaluated showed a notable capability in generating valuable medical content; however, evident lapses in content quality and potential harm signal the need for further refinements. Given the dynamic landscape of LLMs, this study's findings emphasize the need for regular and methodical assessments, oversight, and fine-tuning of these AI tools to ensure they produce consistently trustworthy and clinically safe medical advice. Notably, the introduction of an auto-evaluation mechanism using GPT-4, as detailed in this study, provides a scalable, transferable method for domain-agnostic evaluations, extending beyond therapy recommendation assessments.
Keywords: ChatGPT; LLM; accuracy; artificial intelligence; chatbot; chatbots; dermatology; health information; large language models; medical advice; medical information; ophthalmology; orthopedic; orthopedics; quality; recommendation; recommendations; reliability; reliable; safety; therapy.
©Theresa Isabelle Wilhelm, Jonas Roos, Robert Kaczmarczyk. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 30.10.2023.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
References
-
- Wang F, Preininger A. AI in health: state of the art, challenges, and future directions. Yearb Med Inform. 2019 Aug;28(1):16–26. doi: 10.1055/s-0039-1677908. http://www.thieme-connect.com/DOI/DOI?10.1055/s-0039-1677908 - DOI - PMC - PubMed
-
- Introducing ChatGPT. OpenAI. [2023-05-08]. https://openai.com/blog/chatgpt .
-
- OpenAI GPT-4 Technical Report. arXiv. doi: 10.5860/choice.189890. Preprint posted online on March 15, 2023. https://arxiv.org/abs/2303.08774 - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Research Materials
