

Effects of stochastic coding on olfactory discrimination in flies and mice
- PMID: 37906721
- PMCID: PMC10618007
- DOI: 10.1371/journal.pbio.3002206
Effects of stochastic coding on olfactory discrimination in flies and mice
Abstract
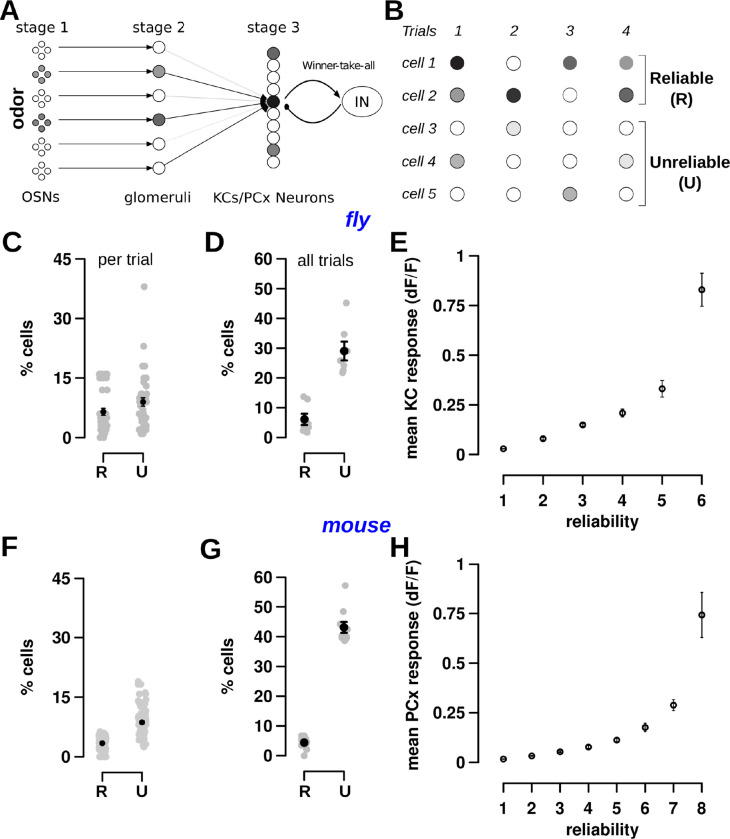
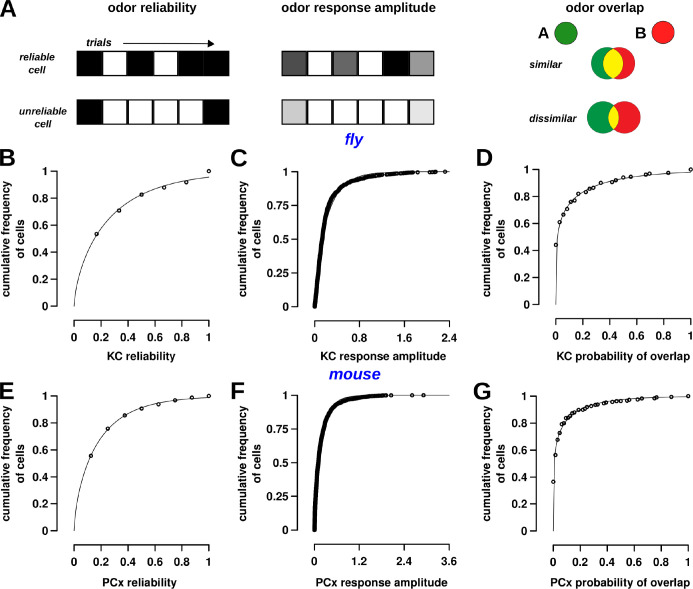
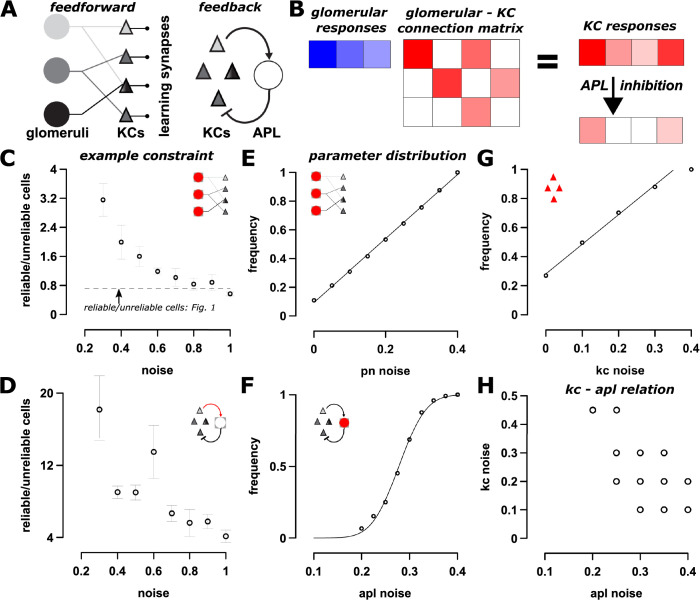
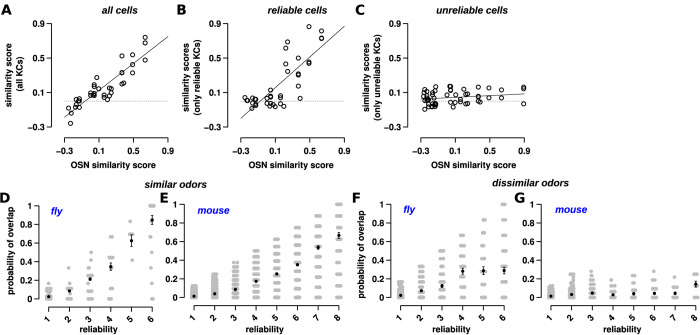
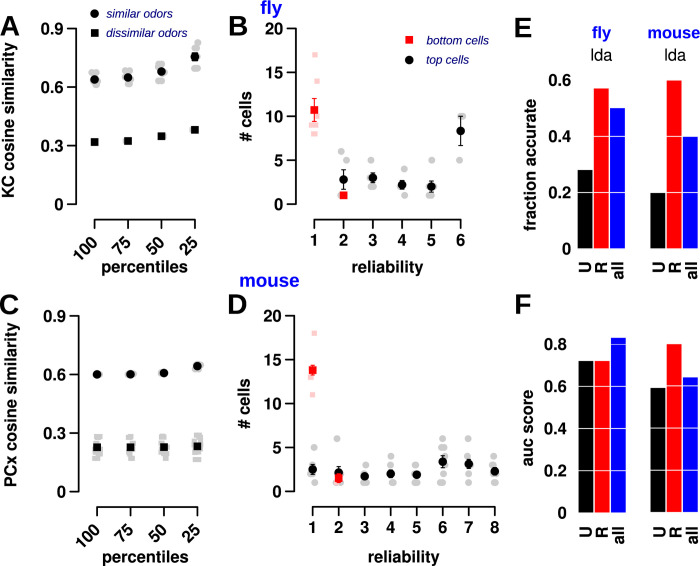
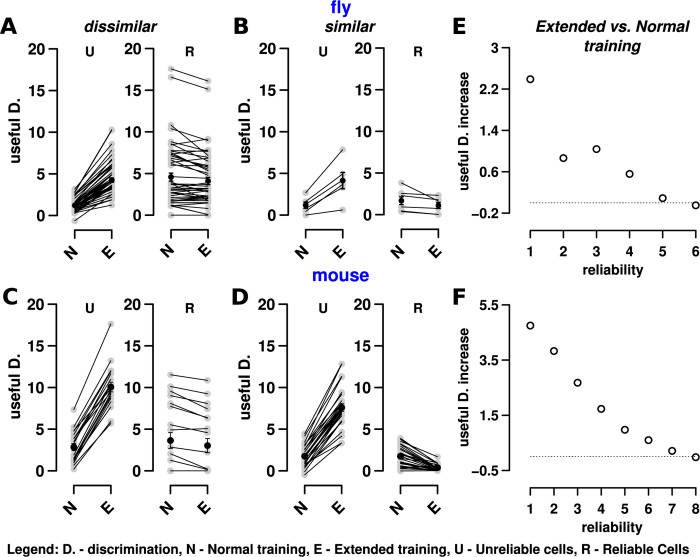
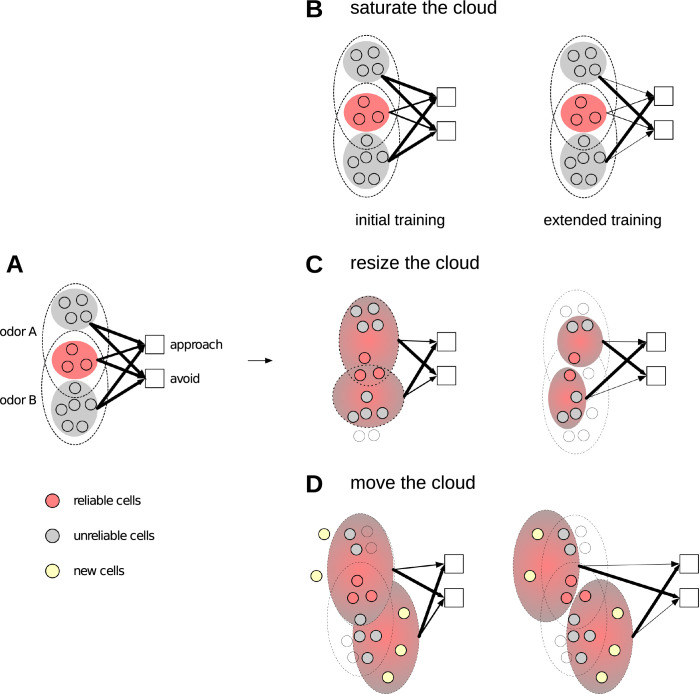
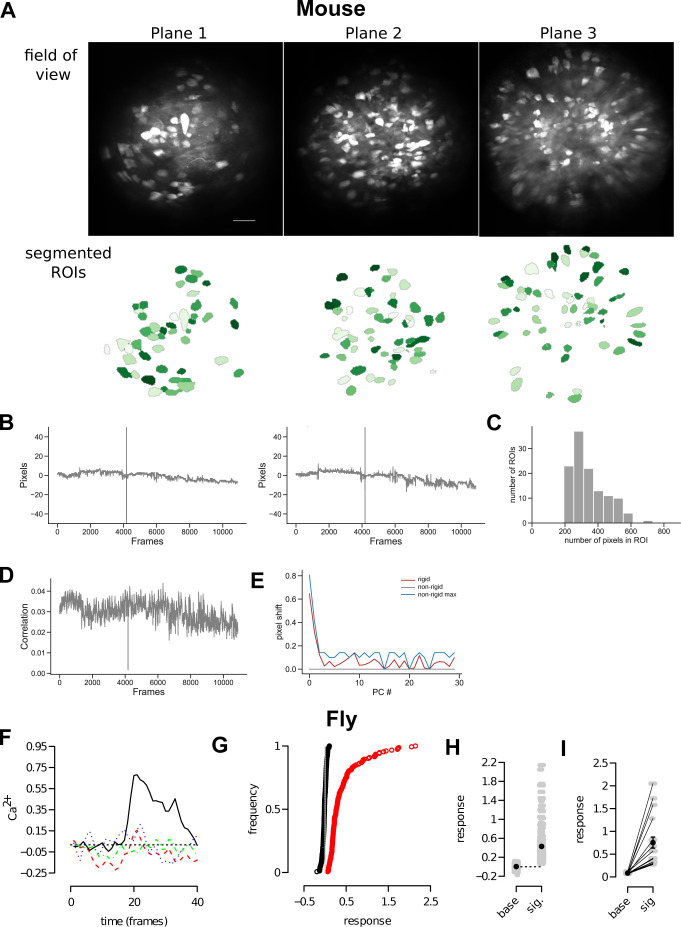
Sparse coding can improve discrimination of sensory stimuli by reducing overlap between their representations. Two factors, however, can offset sparse coding's benefits: similar sensory stimuli have significant overlap and responses vary across trials. To elucidate the effects of these 2 factors, we analyzed odor responses in the fly and mouse olfactory regions implicated in learning and discrimination-the mushroom body (MB) and the piriform cortex (PCx). We found that neuronal responses fall along a continuum from extremely reliable across trials to extremely variable or stochastic. Computationally, we show that the observed variability arises from noise within central circuits rather than sensory noise. We propose this coding scheme to be advantageous for coarse- and fine-odor discrimination. More reliable cells enable quick discrimination between dissimilar odors. For similar odors, however, these cells overlap and do not provide distinguishing information. By contrast, more unreliable cells are decorrelated for similar odors, providing distinguishing information, though these benefits only accrue with extended training with more trials. Overall, we have uncovered a conserved, stochastic coding scheme in vertebrates and invertebrates, and we identify a candidate mechanism, based on variability in a winner-take-all (WTA) inhibitory circuit, that improves discrimination with training.
Copyright: © 2023 Srinivasan et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
Similar articles
-
Odor representations in olfactory cortex: distributed rate coding and decorrelated population activity.Neuron. 2012 Jun 21;74(6):1087-98. doi: 10.1016/j.neuron.2012.04.021. Neuron. 2012. PMID: 22726838 Free PMC article.
-
Task-Demand-Dependent Neural Representation of Odor Information in the Olfactory Bulb and Posterior Piriform Cortex.J Neurosci. 2019 Dec 11;39(50):10002-10018. doi: 10.1523/JNEUROSCI.1234-19.2019. Epub 2019 Oct 31. J Neurosci. 2019. PMID: 31672791 Free PMC article.
-
Differential associative training enhances olfactory acuity in Drosophila melanogaster.J Neurosci. 2014 Jan 29;34(5):1819-37. doi: 10.1523/JNEUROSCI.2598-13.2014. J Neurosci. 2014. PMID: 24478363 Free PMC article.
-
Common principles for odour coding across vertebrates and invertebrates.Nat Rev Neurosci. 2024 Jul;25(7):453-472. doi: 10.1038/s41583-024-00822-0. Epub 2024 May 28. Nat Rev Neurosci. 2024. PMID: 38806946 Review.
-
Understanding smell--the olfactory stimulus problem.Neurosci Biobehav Rev. 2013 Sep;37(8):1667-79. doi: 10.1016/j.neubiorev.2013.06.009. Epub 2013 Jun 25. Neurosci Biobehav Rev. 2013. PMID: 23806440 Review.
Cited by
-
Communication subspace dynamics of the canonical olfactory pathway.iScience. 2024 Oct 28;27(12):111275. doi: 10.1016/j.isci.2024.111275. eCollection 2024 Dec 20. iScience. 2024. PMID: 39628563 Free PMC article.
-
Distinct information conveyed to the olfactory bulb by feedforward input from the nose and feedback from the cortex.Nat Commun. 2024 Apr 16;15(1):3268. doi: 10.1038/s41467-024-47366-6. Nat Commun. 2024. PMID: 38627390 Free PMC article.
-
Sensory encoding and memory in the mushroom body: signals, noise, and variability.Learn Mem. 2024 Jun 11;31(5):a053825. doi: 10.1101/lm.053825.123. Print 2024 May. Learn Mem. 2024. PMID: 38862174 Free PMC article. Review.
-
A Perspective on Neuroscience Data Standardization with Neurodata Without Borders.J Neurosci. 2024 Sep 18;44(38):e0381242024. doi: 10.1523/JNEUROSCI.0381-24.2024. J Neurosci. 2024. PMID: 39293939 Free PMC article.
References
-
- Field DJ. What Is the Goal of Sensory Coding? Neural Comput. 1994;6(4):559–601. doi: 10.1162/neco.1994.6.4.559 - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
