

IgLM: Infilling language modeling for antibody sequence design
- PMID: 37909045
- PMCID: PMC11018345
- DOI: 10.1016/j.cels.2023.10.001
IgLM: Infilling language modeling for antibody sequence design
Abstract
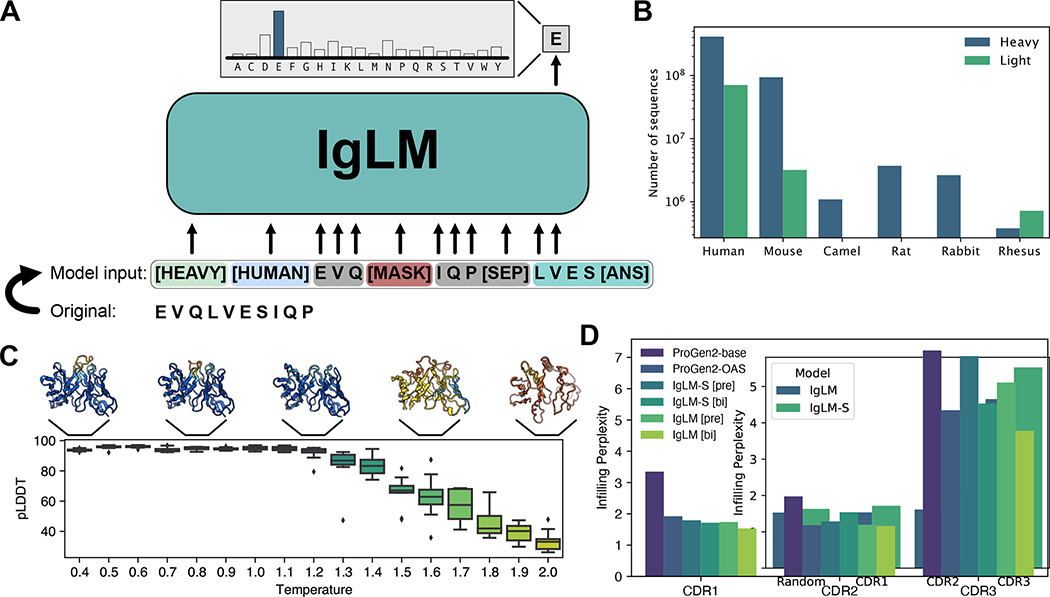
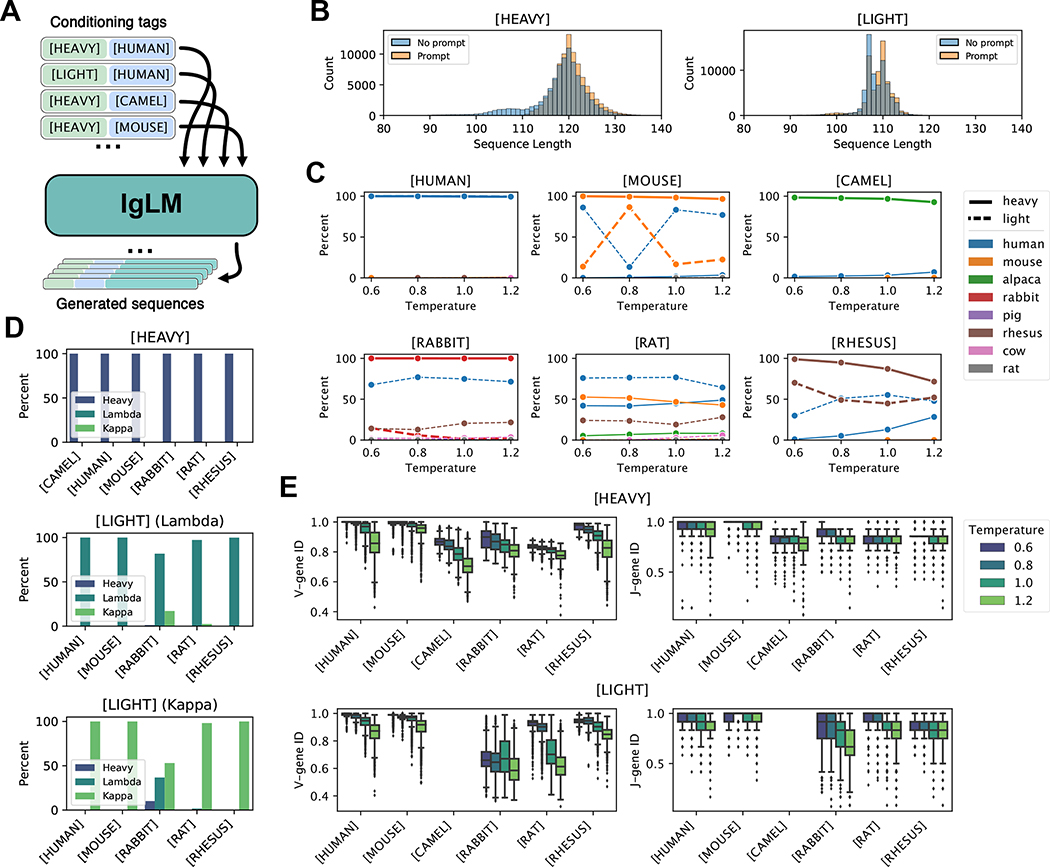
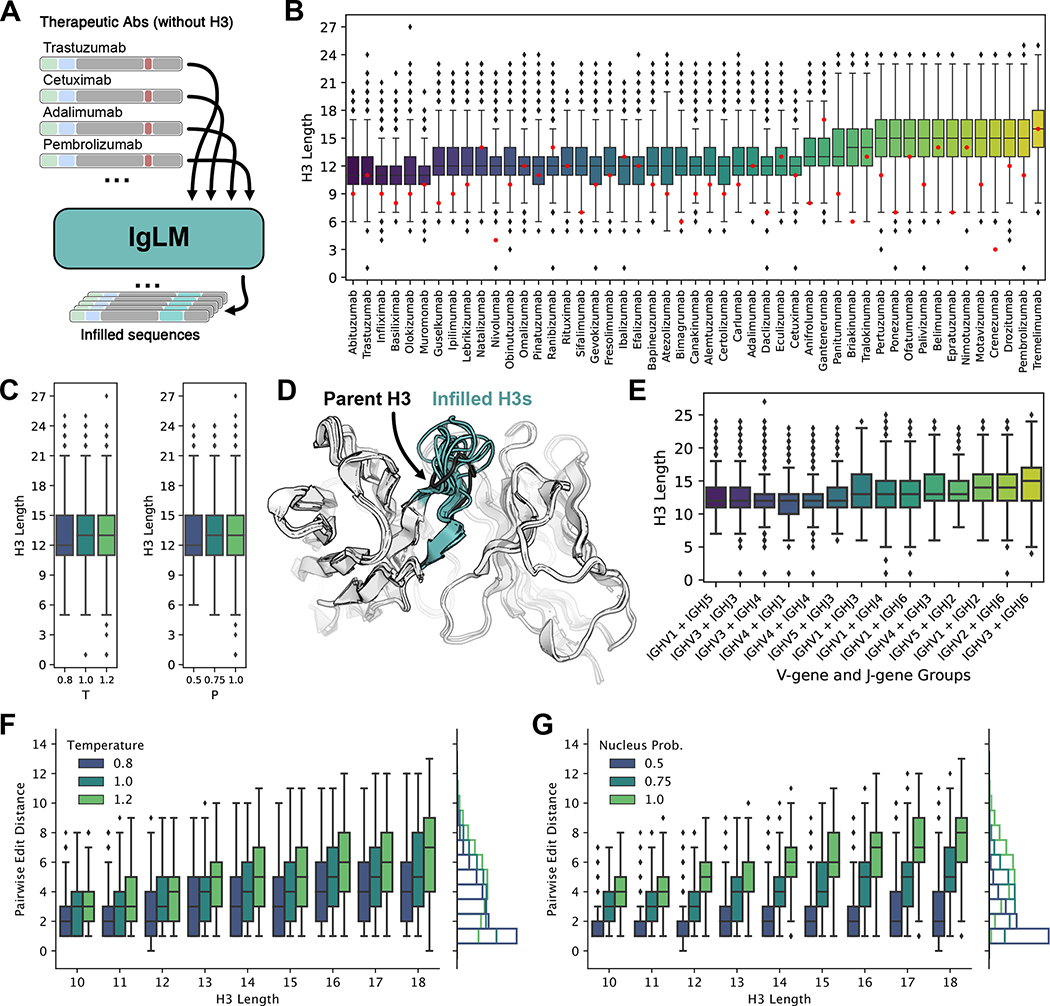
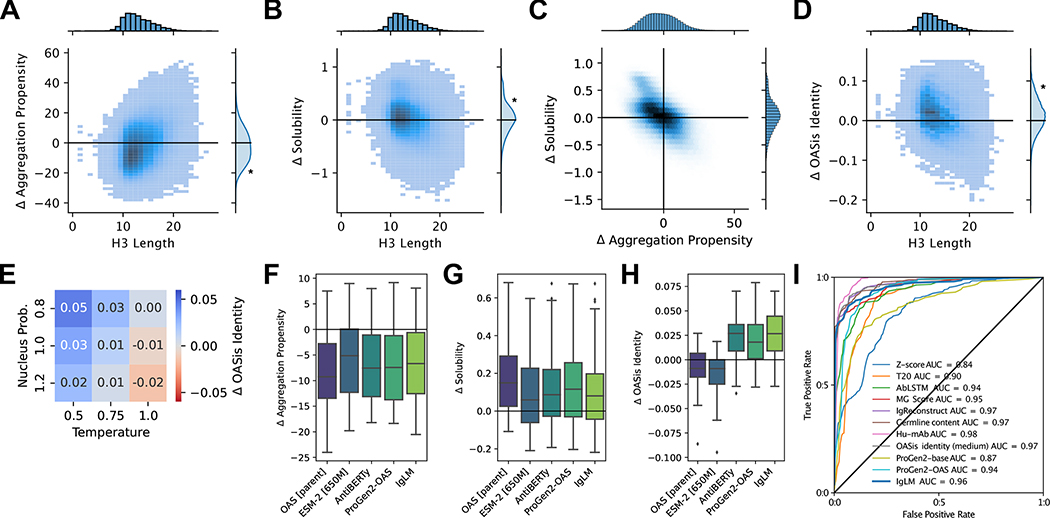
Discovery and optimization of monoclonal antibodies for therapeutic applications relies on large sequence libraries but is hindered by developability issues such as low solubility, high aggregation, and high immunogenicity. Generative language models, trained on millions of protein sequences, are a powerful tool for the on-demand generation of realistic, diverse sequences. We present the Immunoglobulin Language Model (IgLM), a deep generative language model for creating synthetic antibody libraries. Compared with prior methods that leverage unidirectional context for sequence generation, IgLM formulates antibody design based on text-infilling in natural language, allowing it to re-design variable-length spans within antibody sequences using bidirectional context. We trained IgLM on 558 million (M) antibody heavy- and light-chain variable sequences, conditioning on each sequence's chain type and species of origin. We demonstrate that IgLM can generate full-length antibody sequences from a variety of species and its infilling formulation allows it to generate infilled complementarity-determining region (CDR) loop libraries with improved in silico developability profiles. A record of this paper's transparent peer review process is included in the supplemental information.
Keywords: antibodies; deep learning; language modeling.
Copyright © 2023 Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests R.W.S., J.A.R., and J.J.G. are inventors of the IgLM technology developed in this study. The Johns Hopkins University has filed international patent application PCT/US2022/052178 Generative Language Models and Related Aspects for Peptide and Protein Sequence Design, which relates to the IgLM technology. R.W.S., J.A.R., and J.J.G. may be entitled to a portion of revenue received from commercial licensing of the IgLM technology and any intellectual property therein. J.J.G. is an unpaid member of the Executive Board of the Rosetta Commons. Under an institutional participation agreement between the University of Washington, acting on behalf of the Rosetta Commons, and the Johns Hopkins University (JHU), JHU may be entitled to a portion of revenue received on licensing of Rosetta software used in this paper. J.J.G. has a financial interest in Cyrus Biotechnology. Cyrus Biotechnology distributes the Rosetta software, which may include methods used in this paper. These arrangements have been reviewed and approved by the Johns Hopkins University in accordance with its conflict-of-interest policies.
Figures
Comment in
-
Becoming fluent in proteins.Cell Syst. 2023 Nov 15;14(11):923-924. doi: 10.1016/j.cels.2023.10.008. Cell Syst. 2023. PMID: 37972558
References
-
- Bachas S, Rakocevic G, Spencer D, Sastry AV, Haile R, Sutton JM, Kasun G, Stachyra A, Gutierrez JM, Yassine E et al. (2022). Antibody optimization enabled by artificial intelligence predictions of binding affinity and naturalness. bioRxiv, 2022–08.
-
- Chennamsetty N, Voynov V, Kayser V, Helk B and Trout BL (2010). Prediction of aggregation prone regions of therapeutic proteins. The Journal of Physical Chemistry B 114, 6614–6624. - PubMed
-
- Chothia C and Lesk AM (1987). Canonical structures for the hypervariable regions of immunoglobulins. Journal of molecular biology 196, 901–917. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
