

Realizing a deep reinforcement learning agent for real-time quantum feedback
- PMID: 37932251
- PMCID: PMC10628214
- DOI: 10.1038/s41467-023-42901-3
Realizing a deep reinforcement learning agent for real-time quantum feedback
Abstract
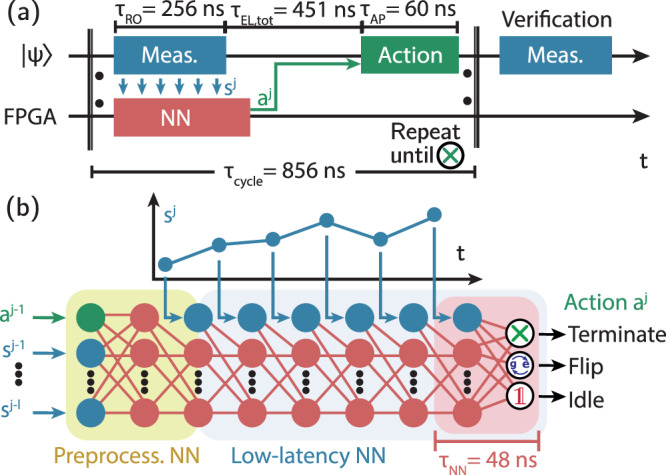
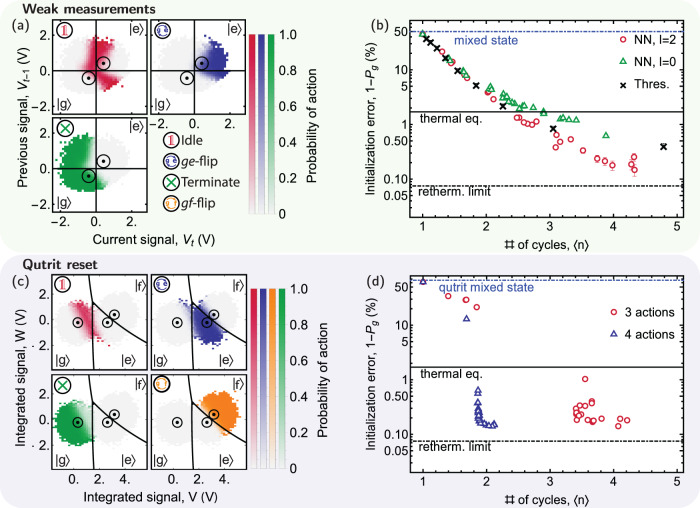
Realizing the full potential of quantum technologies requires precise real-time control on time scales much shorter than the coherence time. Model-free reinforcement learning promises to discover efficient feedback strategies from scratch without relying on a description of the quantum system. However, developing and training a reinforcement learning agent able to operate in real-time using feedback has been an open challenge. Here, we have implemented such an agent for a single qubit as a sub-microsecond-latency neural network on a field-programmable gate array (FPGA). We demonstrate its use to efficiently initialize a superconducting qubit and train the agent based solely on measurements. Our work is a first step towards adoption of reinforcement learning for the control of quantum devices and more generally any physical device requiring low-latency feedback.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures


References
-
- Wiseman, H. & Milburn, G. Quantum Measurement and Control (Cambridge University Press, 2009).
-
- Zhang J, Liu Y-X, Wu R-B, Jacobs K, Nori F. Quantum feedback: Theory, experiments, and applications. Phys. Rep. 2017;679:1. doi: 10.1016/j.physrep.2017.02.003. - DOI
-
- Campagne-Ibarcq P, et al. Persistent control of a superconducting qubit by stroboscopic measurement feedback. Phys. Rev. X. 2013;3:021008.
-
- Salathé Y, et al. Low-latency digital signal processing for feedback and feedforward in quantum computing and communication. Phys. Rev. Appl. 2018;9:034011. doi: 10.1103/PhysRevApplied.9.034011. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
