

Forecasting the dynamics of a complex microbial community using integrated meta-omics
- PMID: 37957315
- PMCID: PMC10781640
- DOI: 10.1038/s41559-023-02241-3
Forecasting the dynamics of a complex microbial community using integrated meta-omics
Abstract
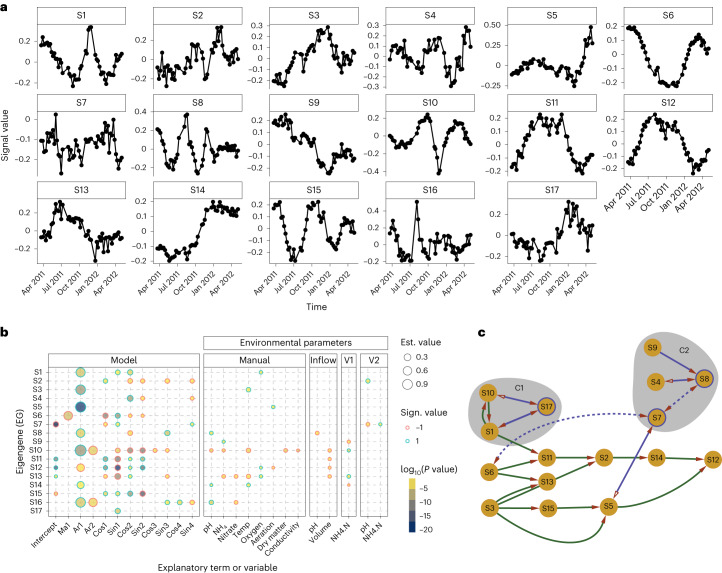
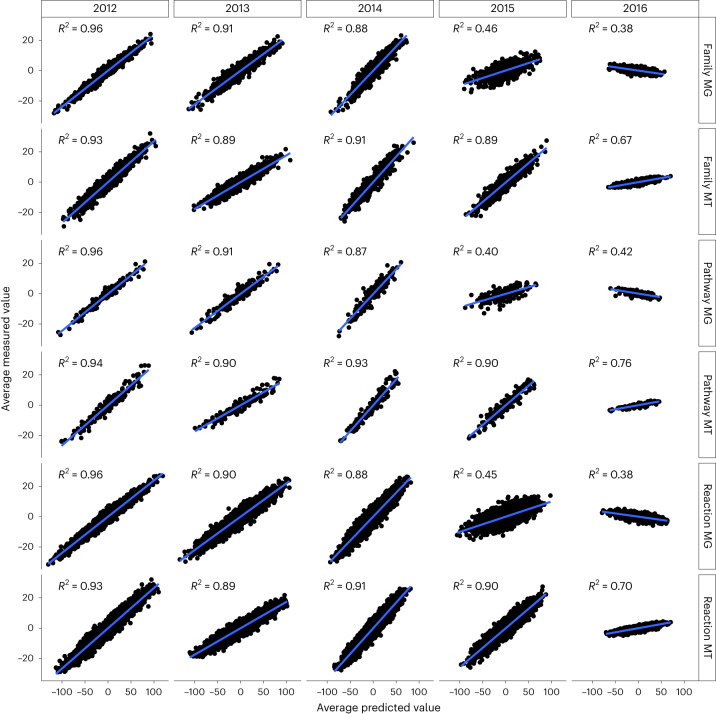
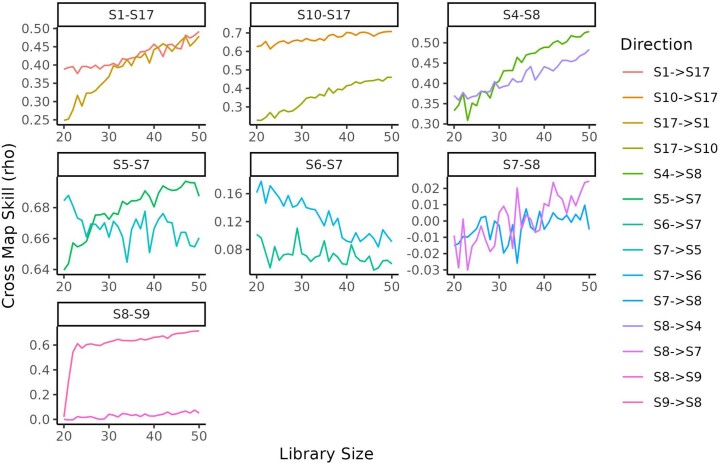
Predicting the behaviour of complex microbial communities is challenging. However, this is essential for complex biotechnological processes such as those in biological wastewater treatment plants (BWWTPs), which require sustainable operation. Here we summarize 14 months of longitudinal meta-omics data from a BWWTP anaerobic tank into 17 temporal signals, explaining 91.1% of the temporal variance, and link those signals to ecological events within the community. We forecast the signals over the subsequent five years and use 21 extra samples collected at defined time intervals for testing and validation. Our forecasts are correct for six signals and hint on phenomena such as predation cycles. Using all the 17 forecasts and the environmental variables, we predict gene abundance and expression, with a coefficient of determination ≥0.87 for the subsequent three years. Our study demonstrates the ability to forecast the dynamics of open microbial ecosystems using interactions between community cycles and environmental parameters.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures











References
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
